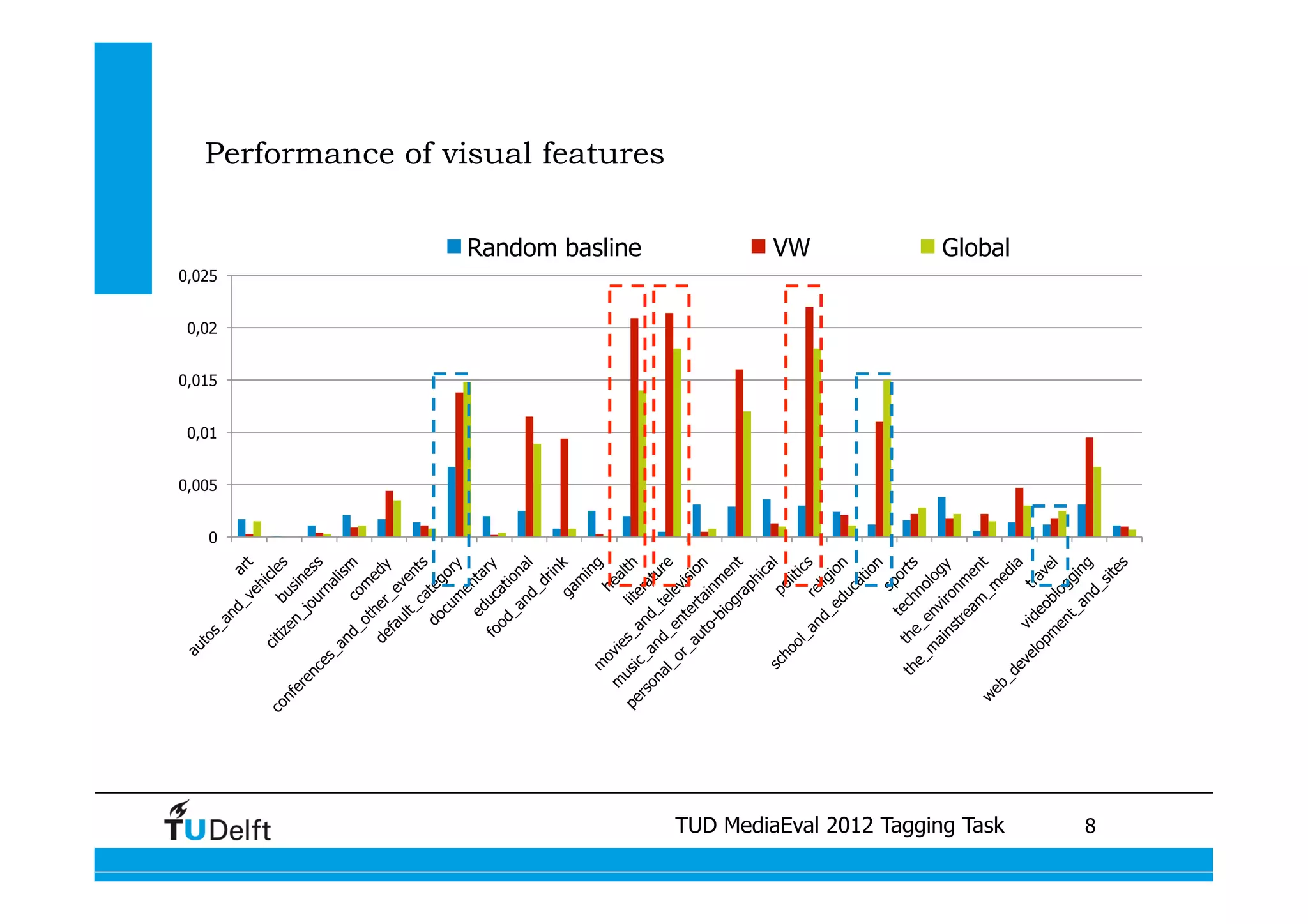
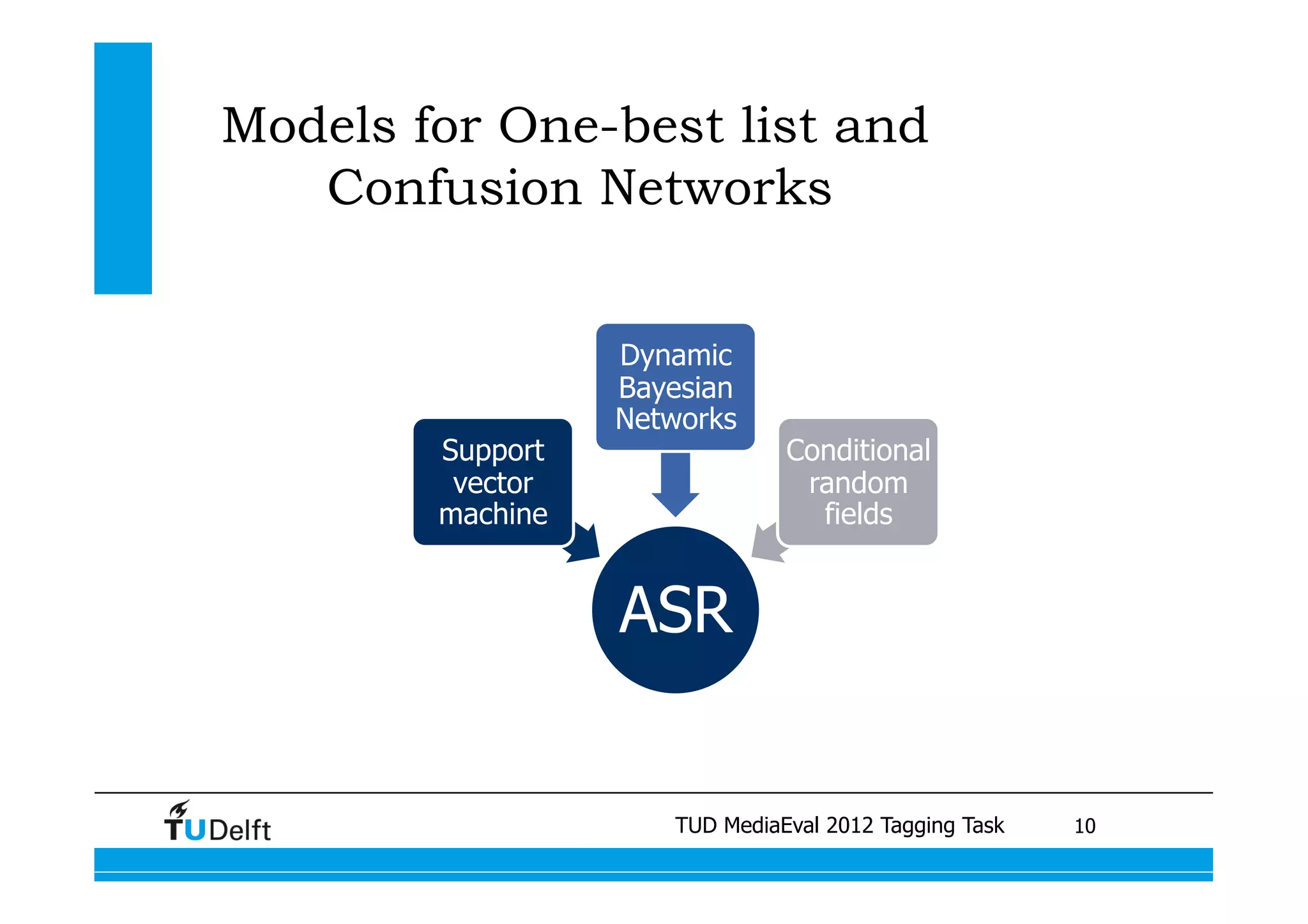
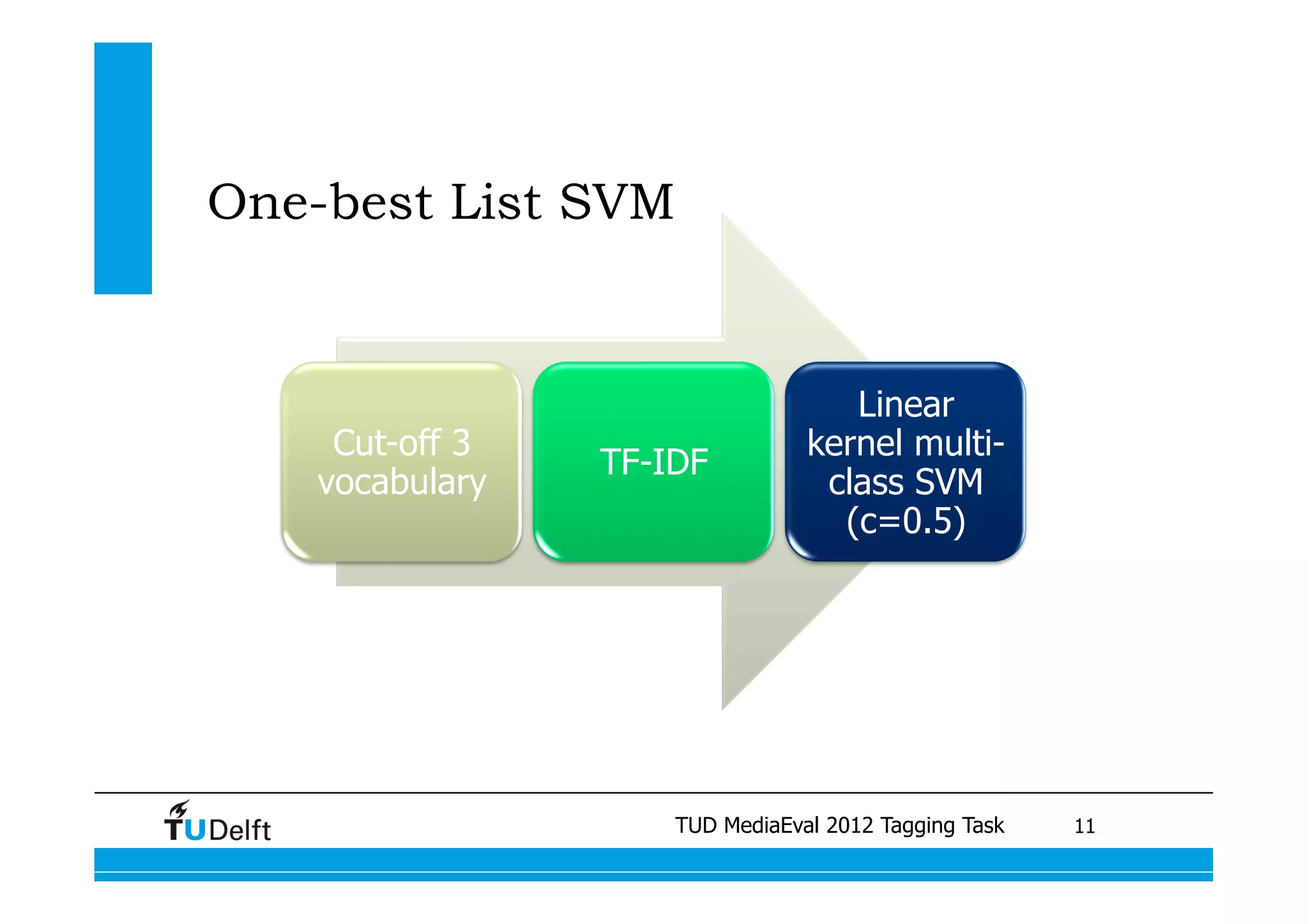
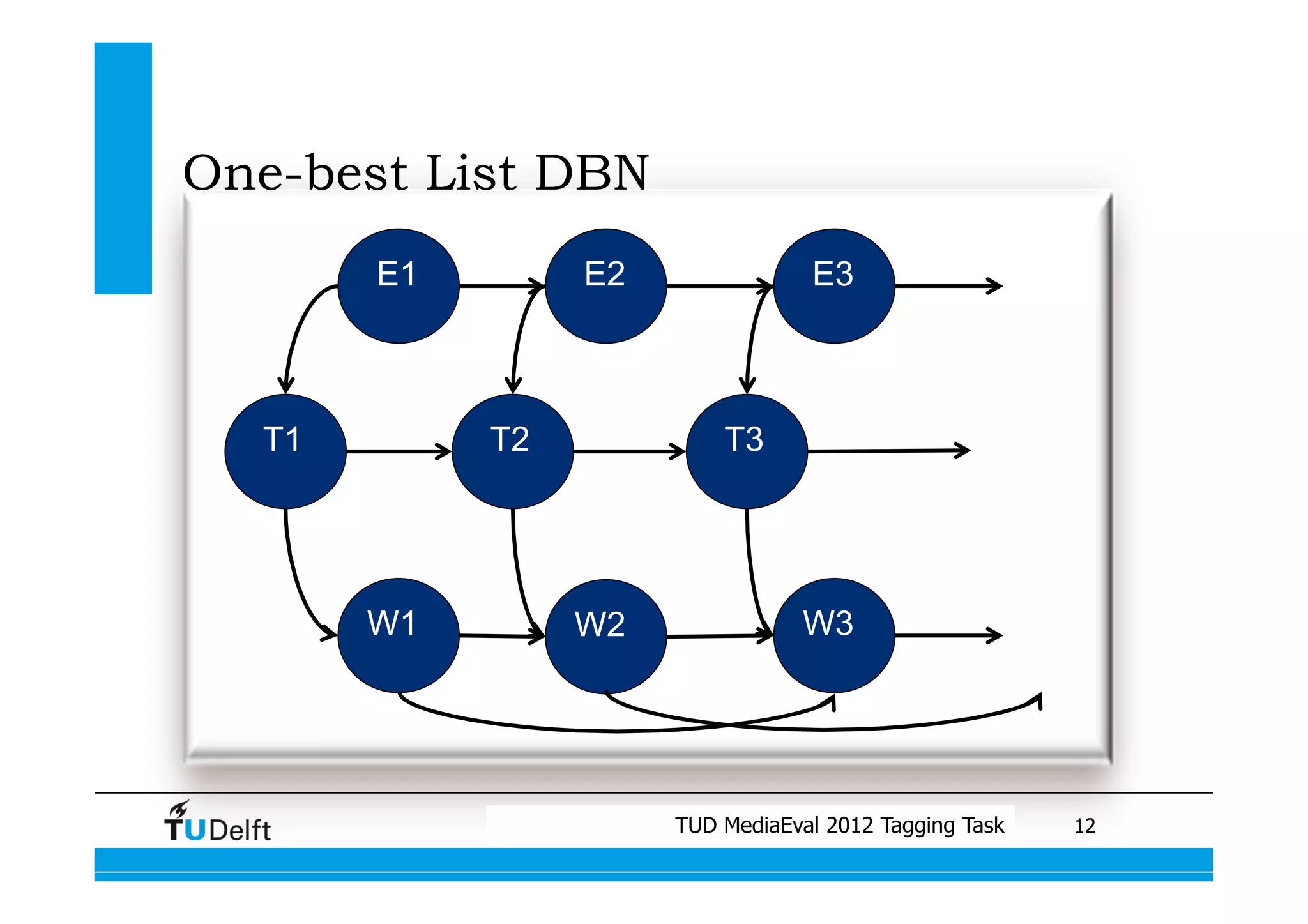
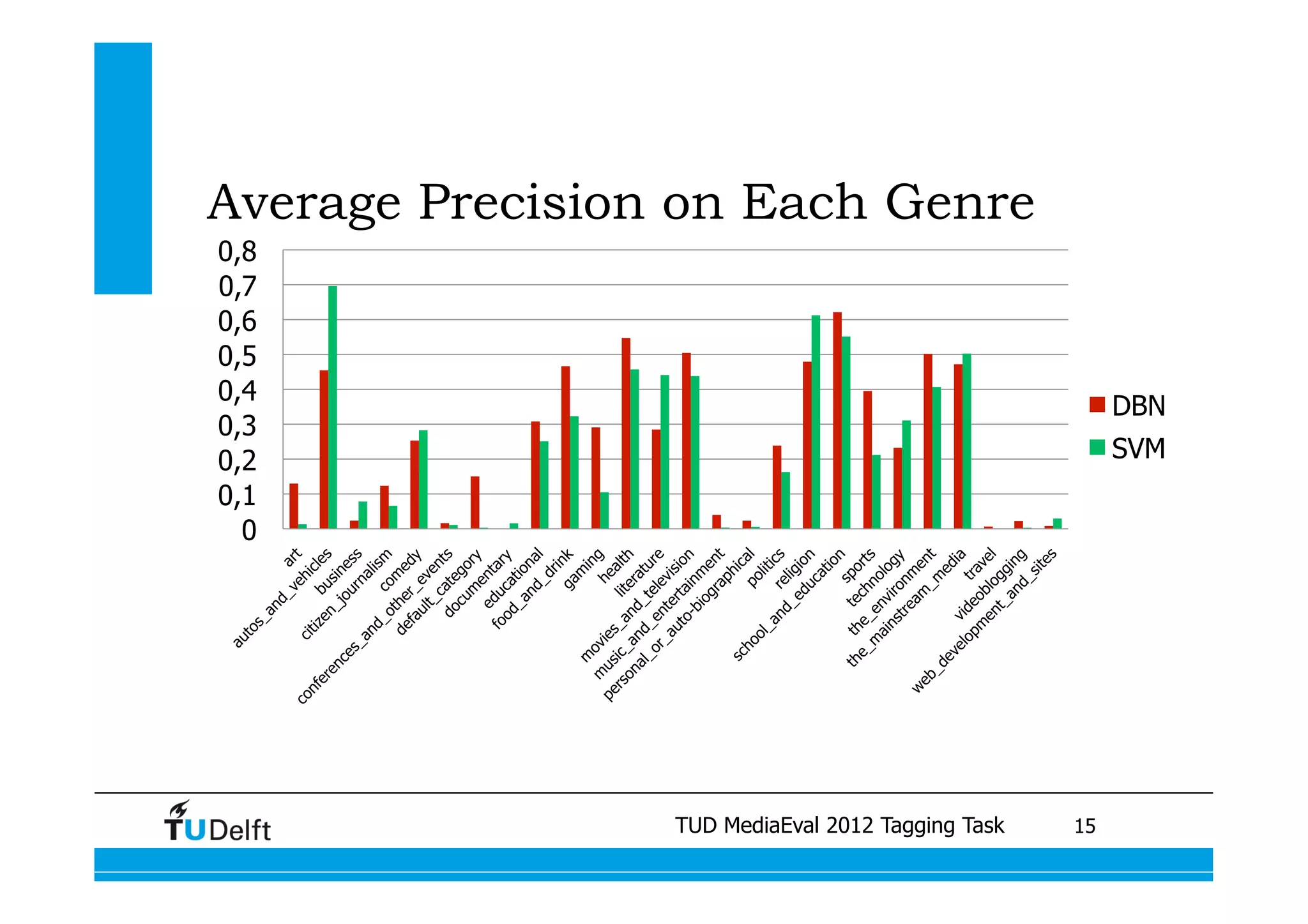
This document summarizes two projects presented by Delft University of Technology at the TUD MediaEval 2012 Tagging Task. The first project used one-vs-all classifiers and feature fusion to perform multi-modality video categorization. The second project compared different models for predicting tags based on automatic speech recognition output, including support vector machines, dynamic Bayesian networks, and conditional random fields. The dynamic Bayesian network model achieved the best performance overall.