論文一覧
• Auralist: Introducing Serendipity into Music
Recommendation
• ETF: Extended Tensor Factorization Model for Personalizing
Prediction of Review Helpfulness
• Mining Contrastive Opinions on Political Texts using Cross-
Perspective Topic Model
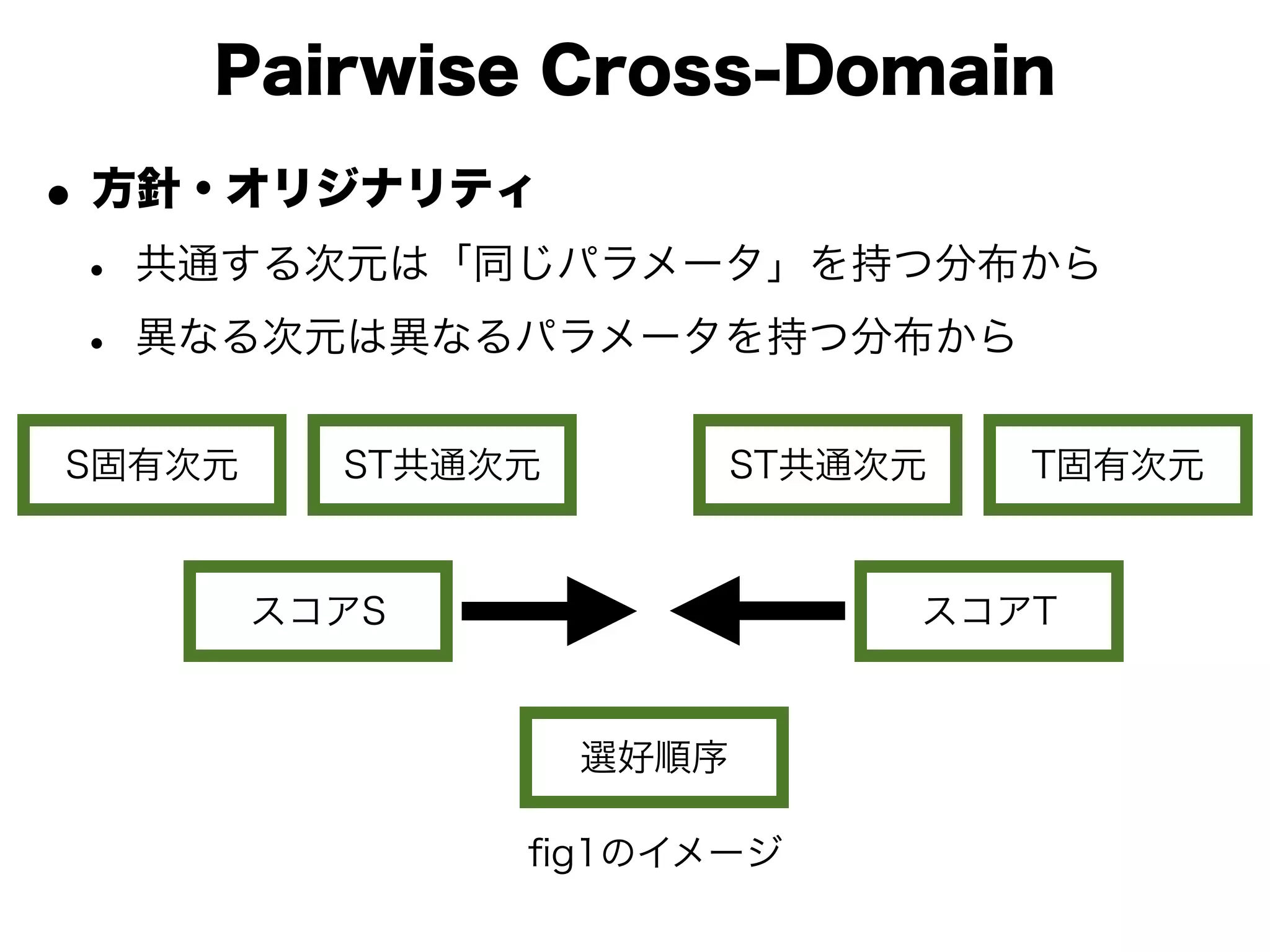
• Pairwise Cross-Domain Factor Model for Heterogeneous
Transfer Ranking
• Scalable Inference in Latent Variable Models
3.
論文一覧
• Auralist: Introducing Serendipity into Music
推薦の話
Recommendation
• ETF: Extended Tensor Factorization Model for Personalizing
レビューの話
Prediction of Review Helpfulness
• Mining Contrastive Opinions on Political Texts using Cross-
意見の話
Perspective Topic Model
• Pairwise Cross-Domain Factor Model for Heterogeneous
Transfer Ranking ランキングの話
• Scalable Inference in Latent Variable Models
スケーラブルの話
4.
Auralist: Introducing Serendipity
into Music Recommendation
Yuan Cao Zhang, Diarmuid Séaghdha,
Daniele Quercia and Tamas Jambor
(Multimedia and Geo Mining)
ETF: Extended TensorFactorization
Model for Personalizing Prediction
of Review Helpfulness
Samaneh Moghaddam, Mohsen Jamali and Martin Ester
(Spotlight on Mining)
Mining Contrastive Opinionson
Political Texts using the Cross-
perspective Topic Model
Yi Fang, Luo Si, Naveen Somasundaram and Zhengtao Yu
(Spotlight on Mining)



















































![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)






