Download as PDF, PPTX



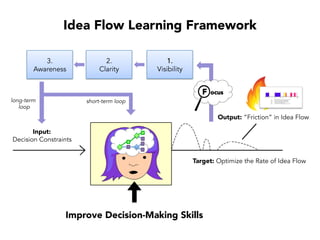
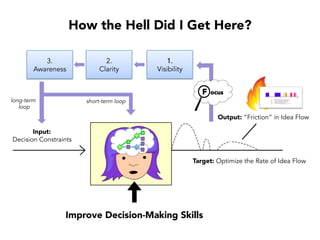











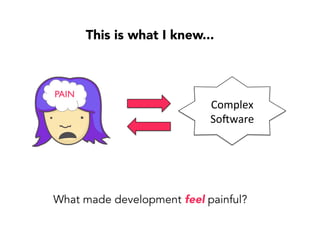
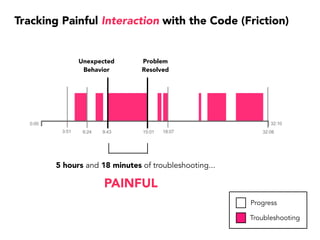
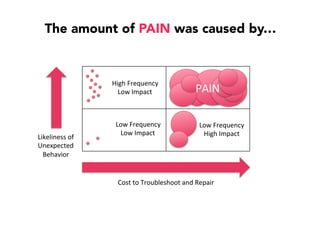




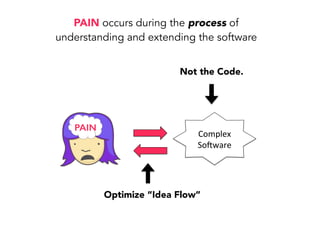
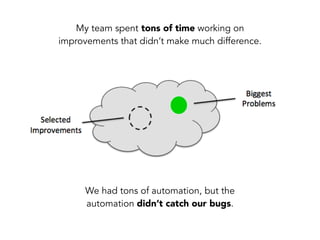
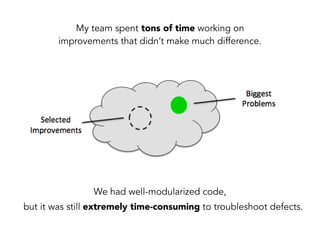
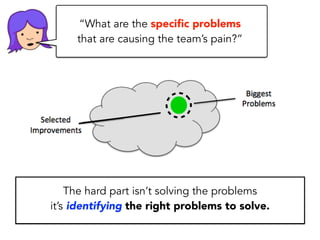







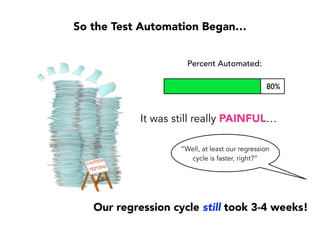


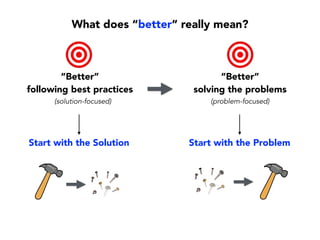

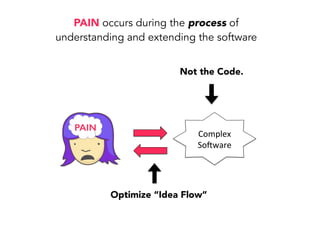
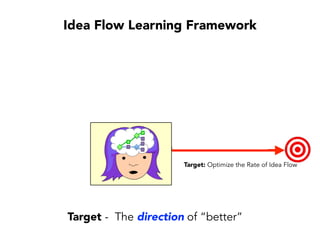










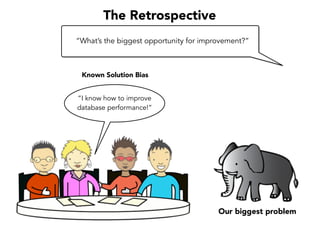

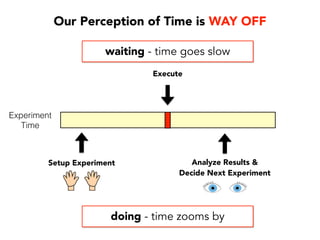


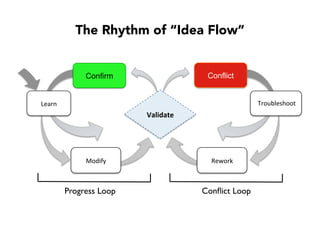
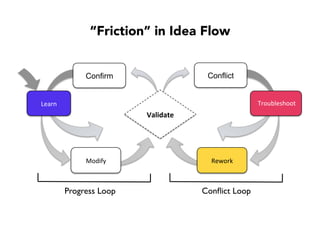
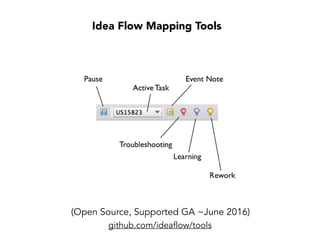
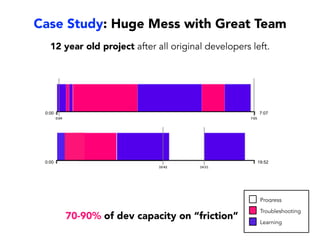
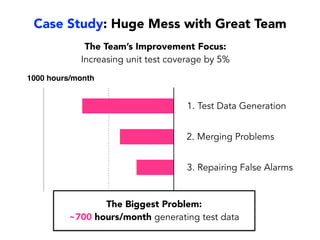
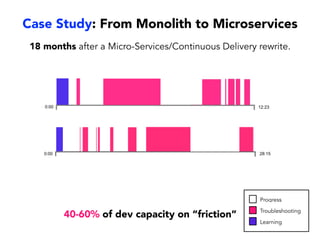
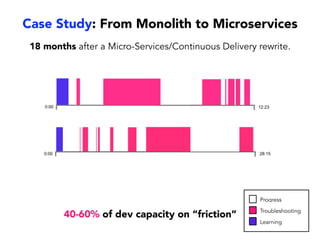
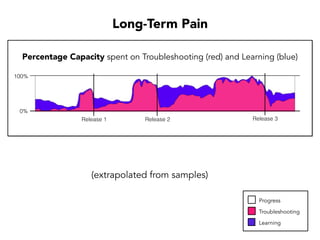
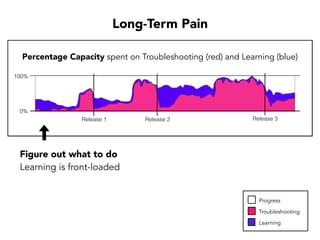
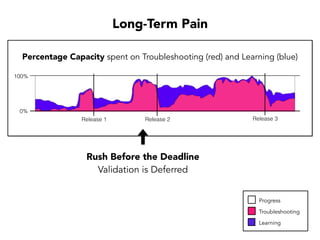
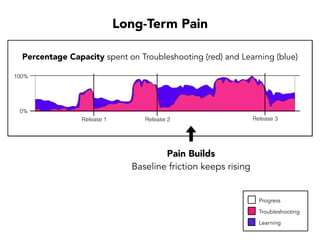
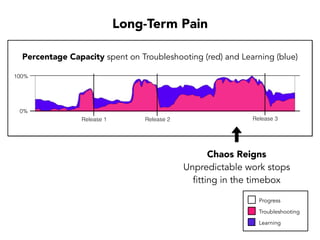

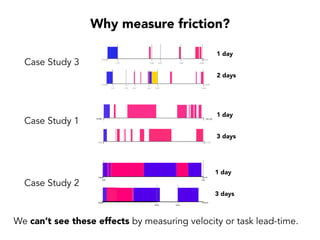
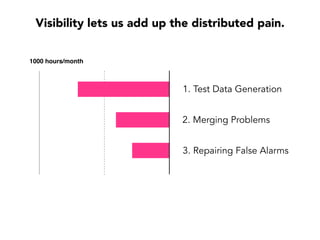

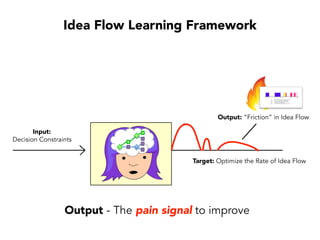
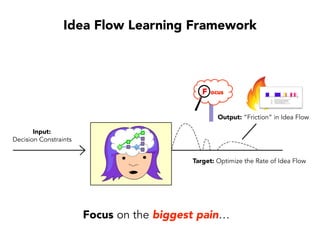
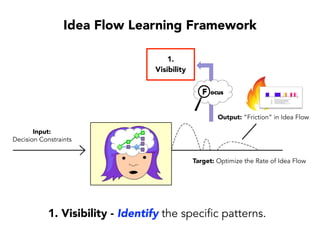

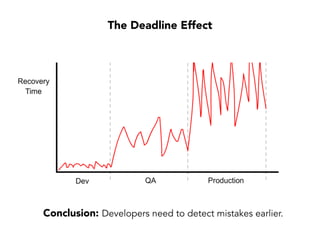
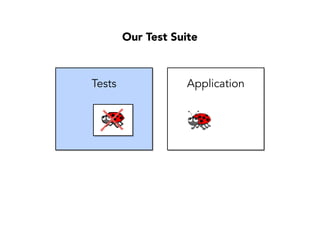
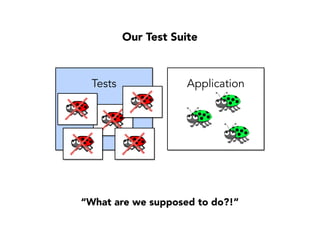
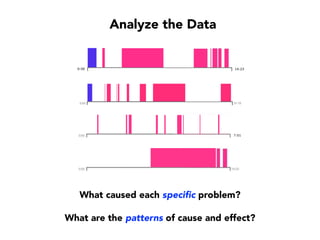
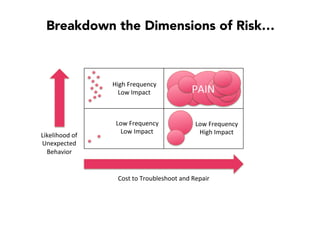

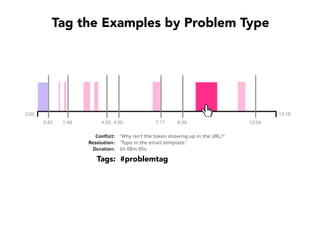
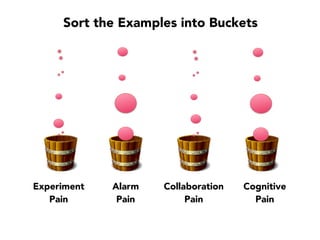
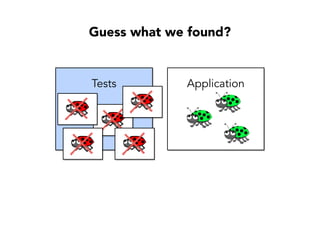

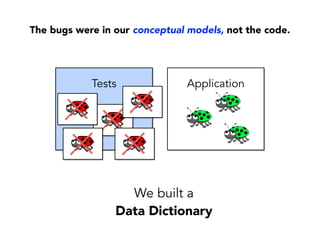
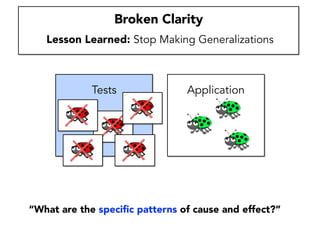
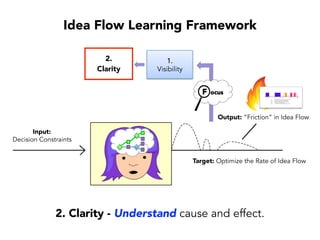


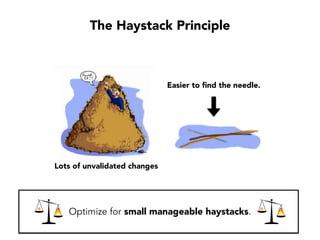
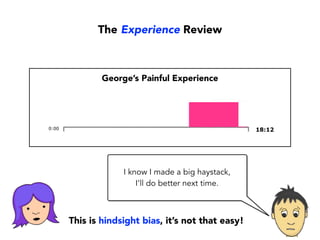

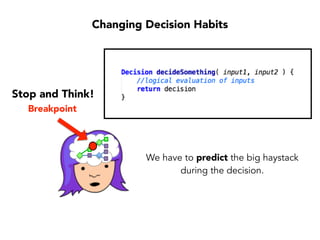

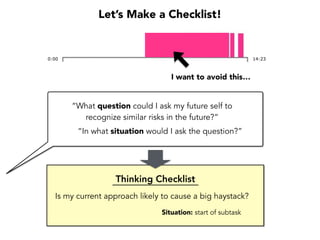
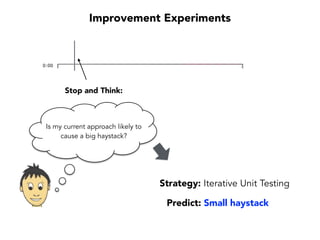
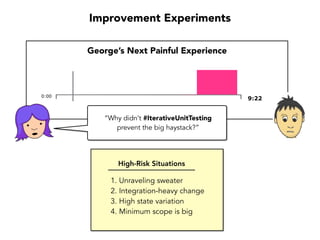
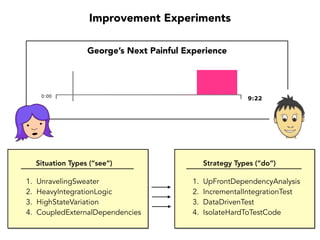
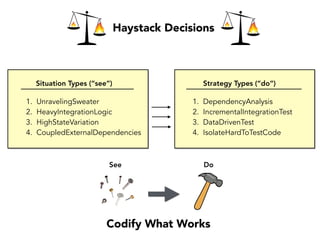


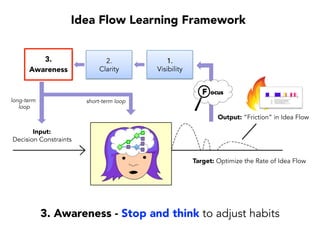
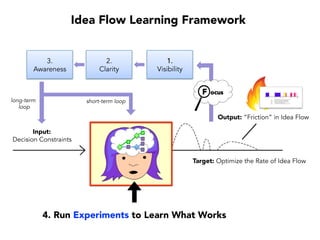

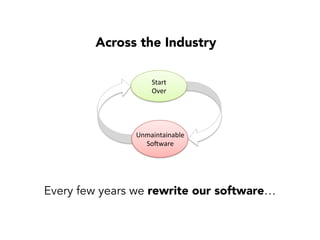



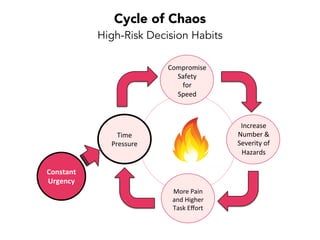
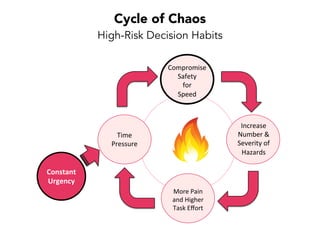
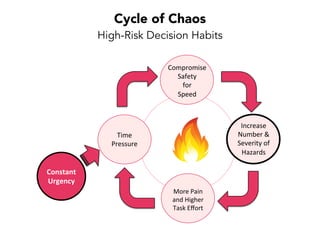
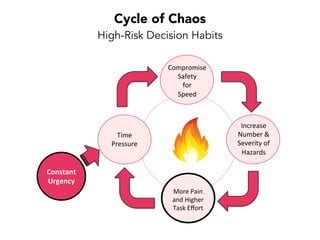
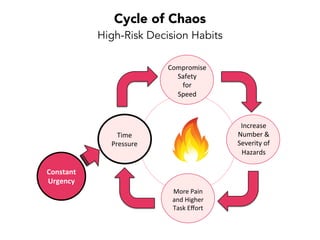
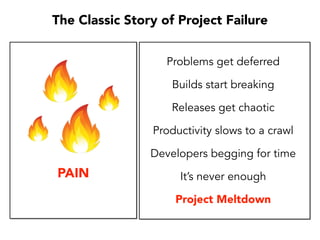


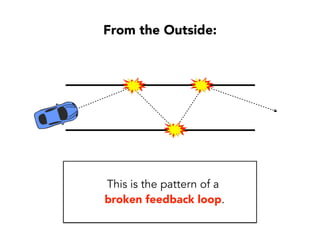
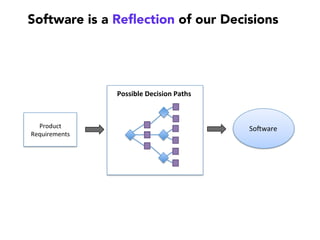
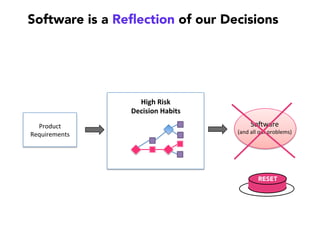
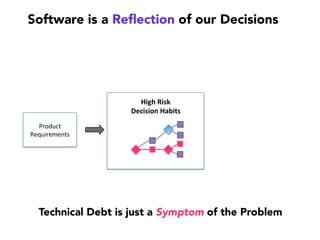
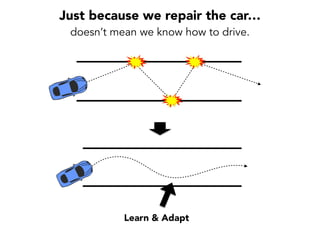
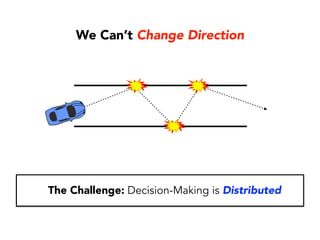
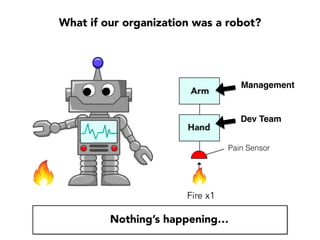
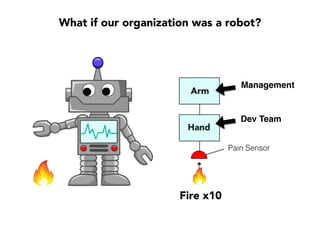
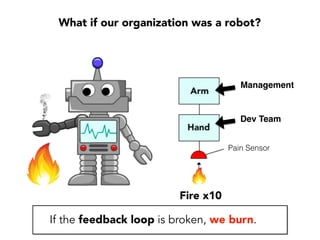
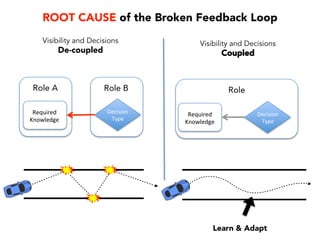
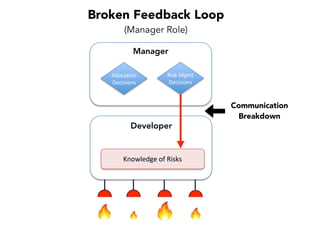

Janelle Klein discusses the challenges faced in software development and the common mistakes leading to project failures, primarily focusing on misidentifying the root causes of issues. She emphasizes the importance of understanding the actual problems instead of rushing to implement solutions, and highlights human factors as a significant source of development pain. The document concludes with recommendations for improving decision-making processes and fostering a culture of responsibility among team members.



















![[HCMC STC Jan 2015] Choosing The Best Of The Plan-Driven And Agile Developmen...](https://cdn.slidesharecdn.com/ss_thumbnails/choosingthebest-150208212855-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


































































