Downloaded 12 times
















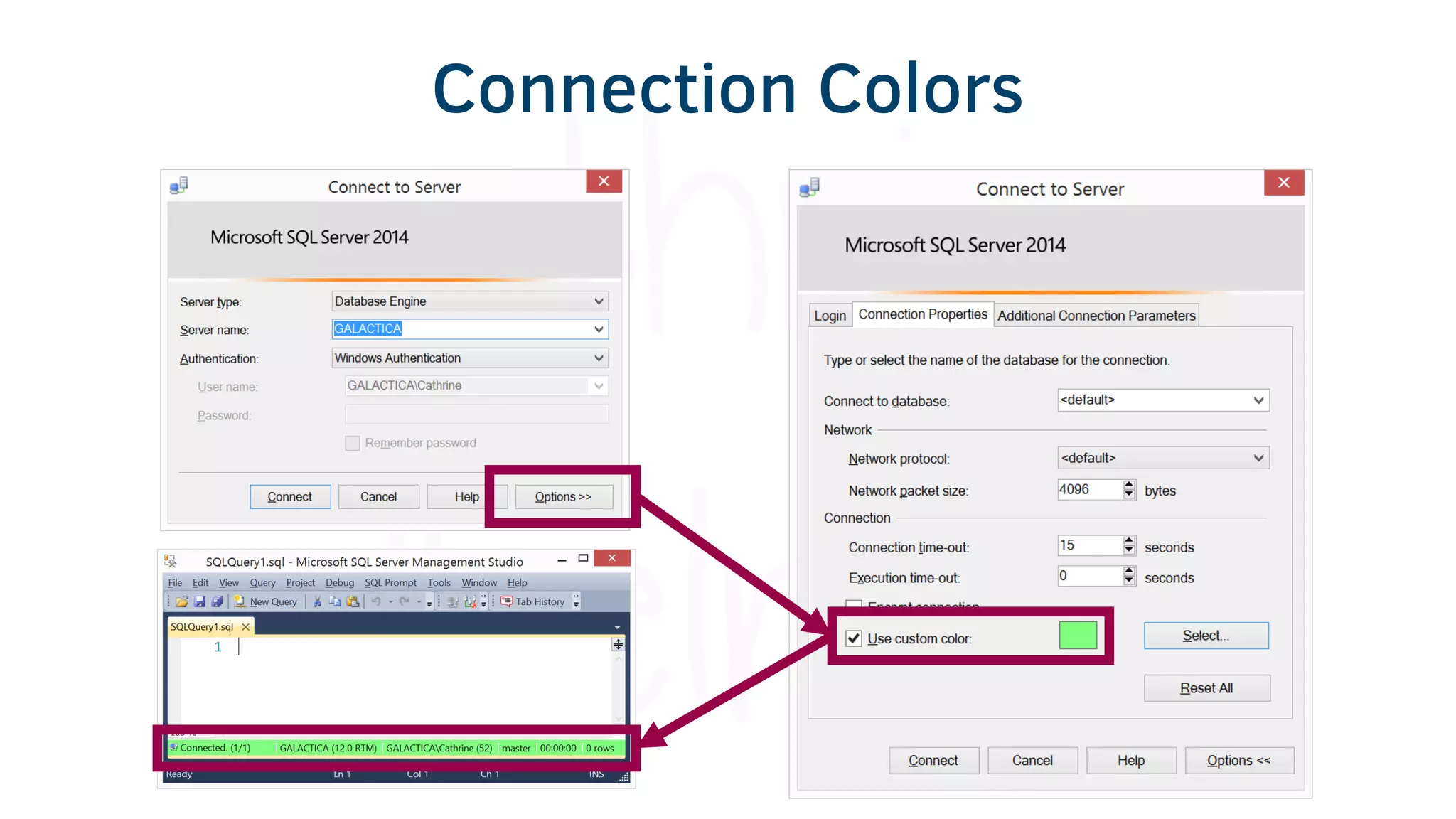
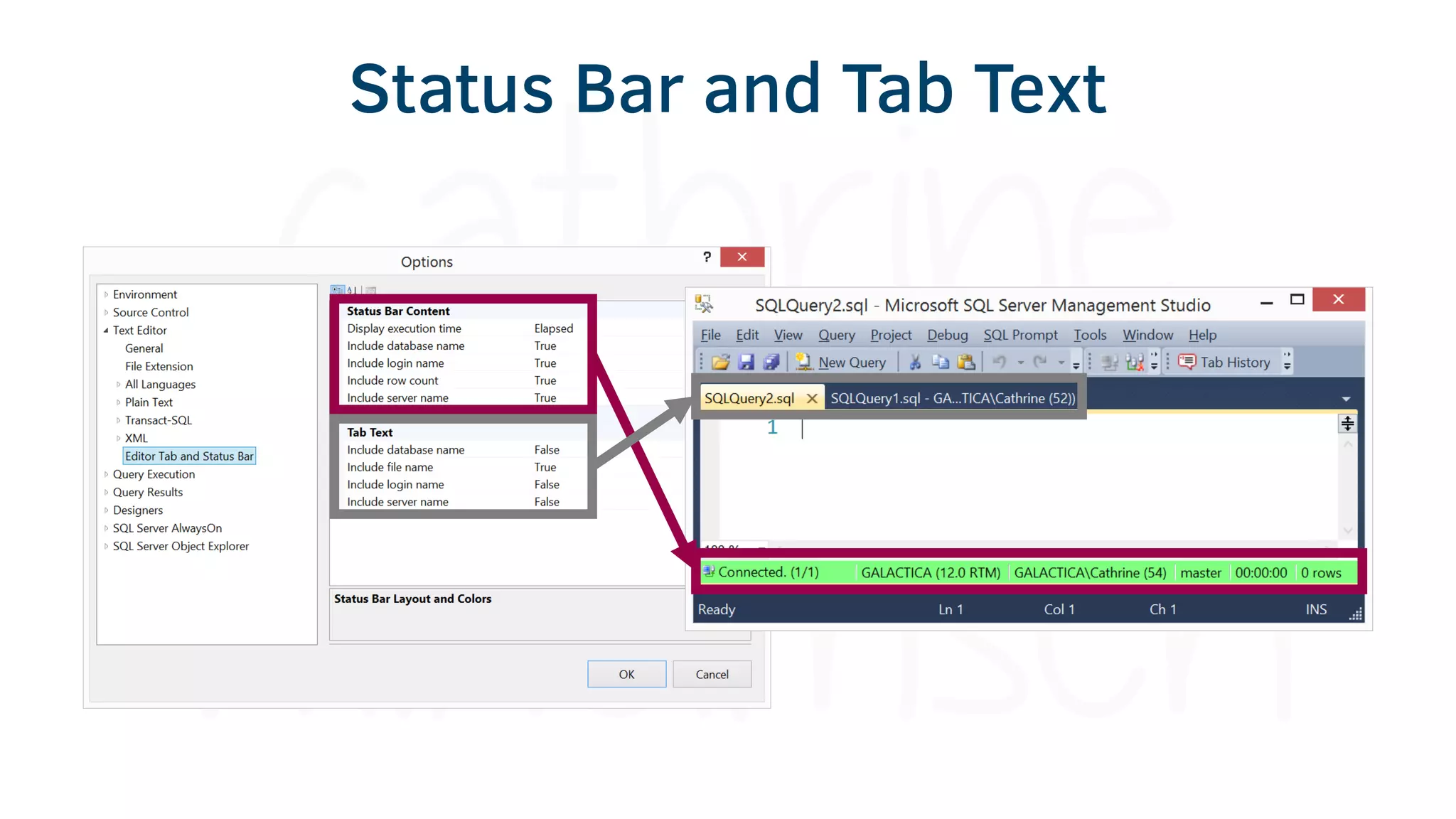
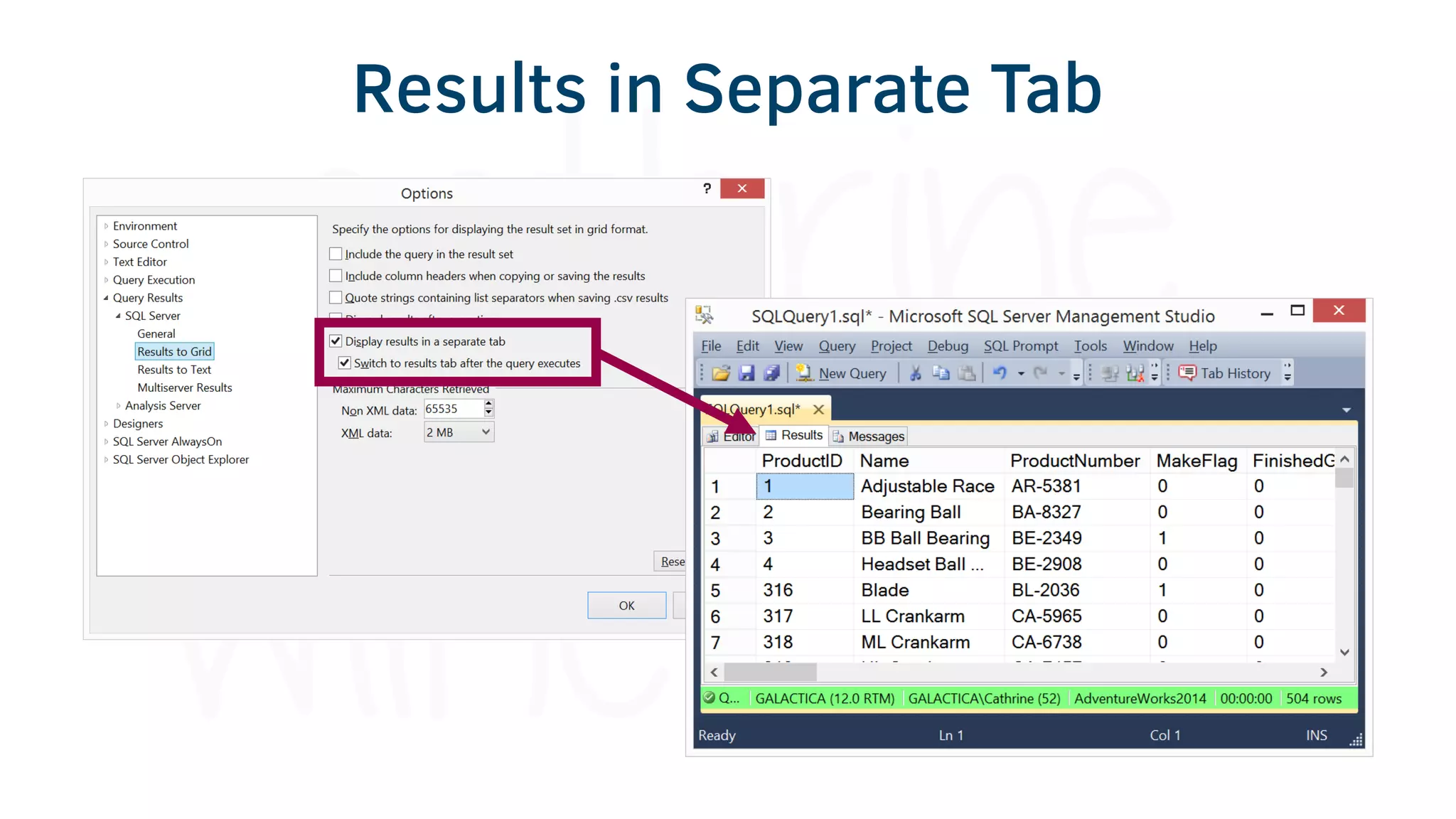
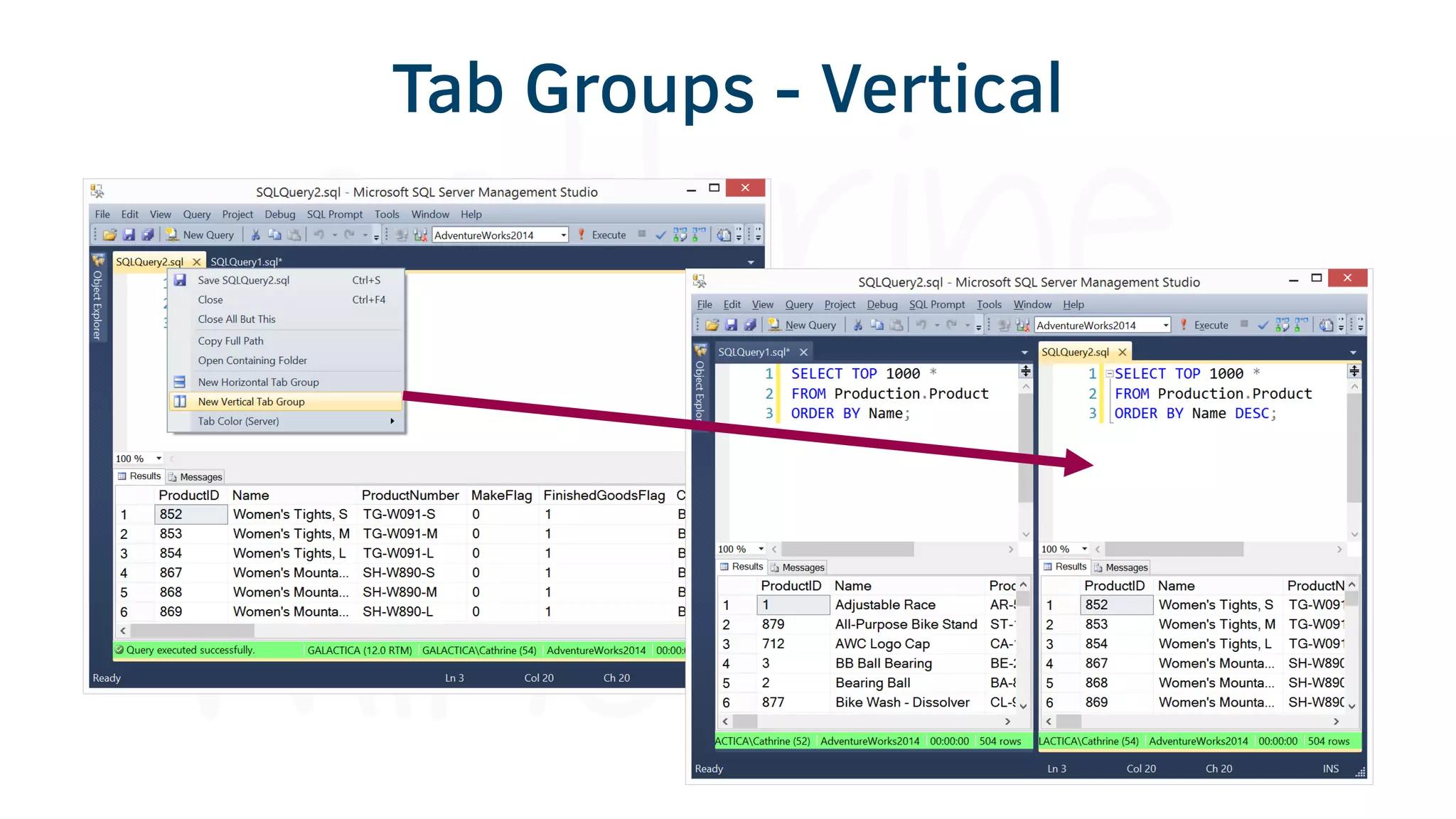
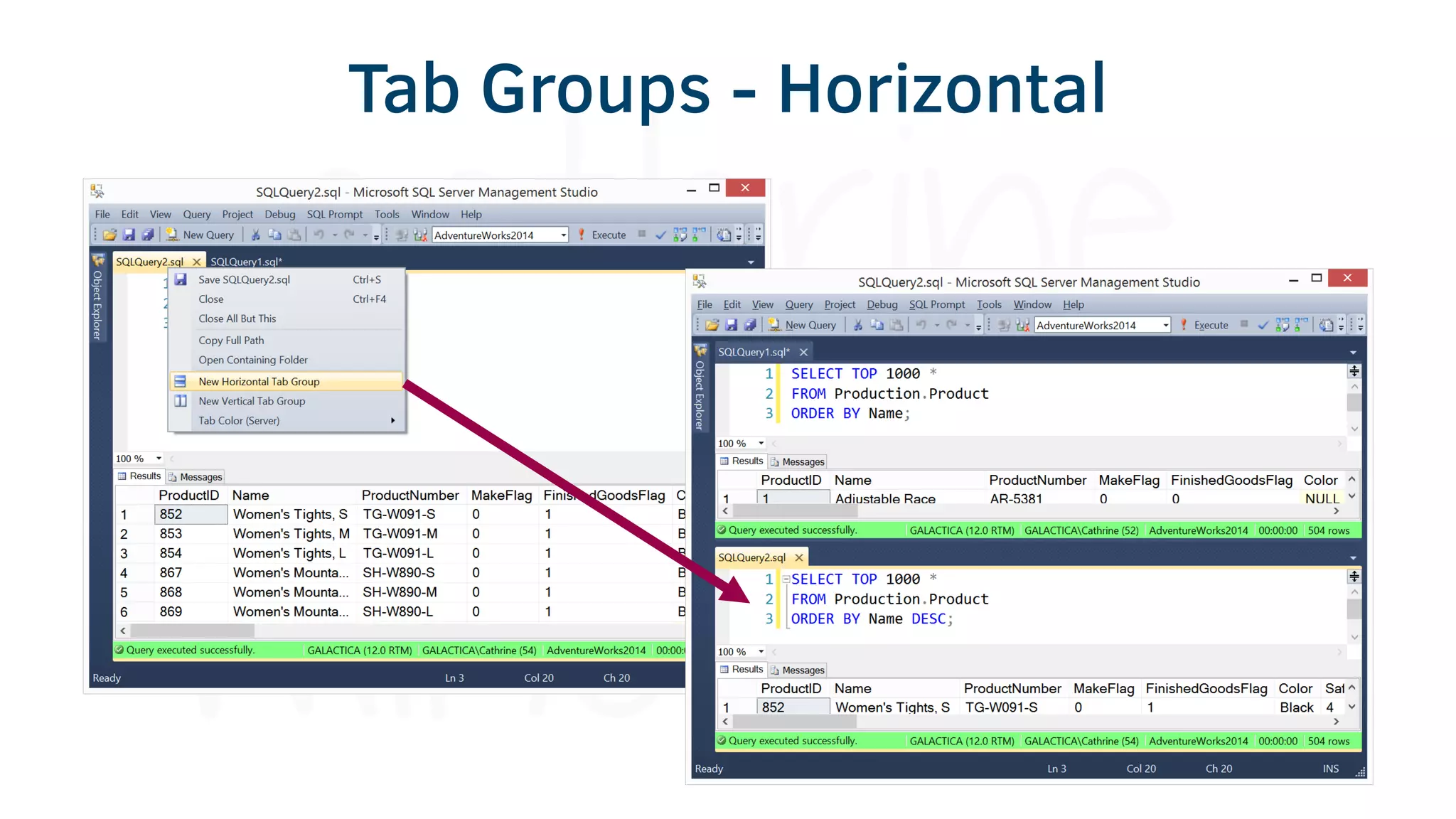
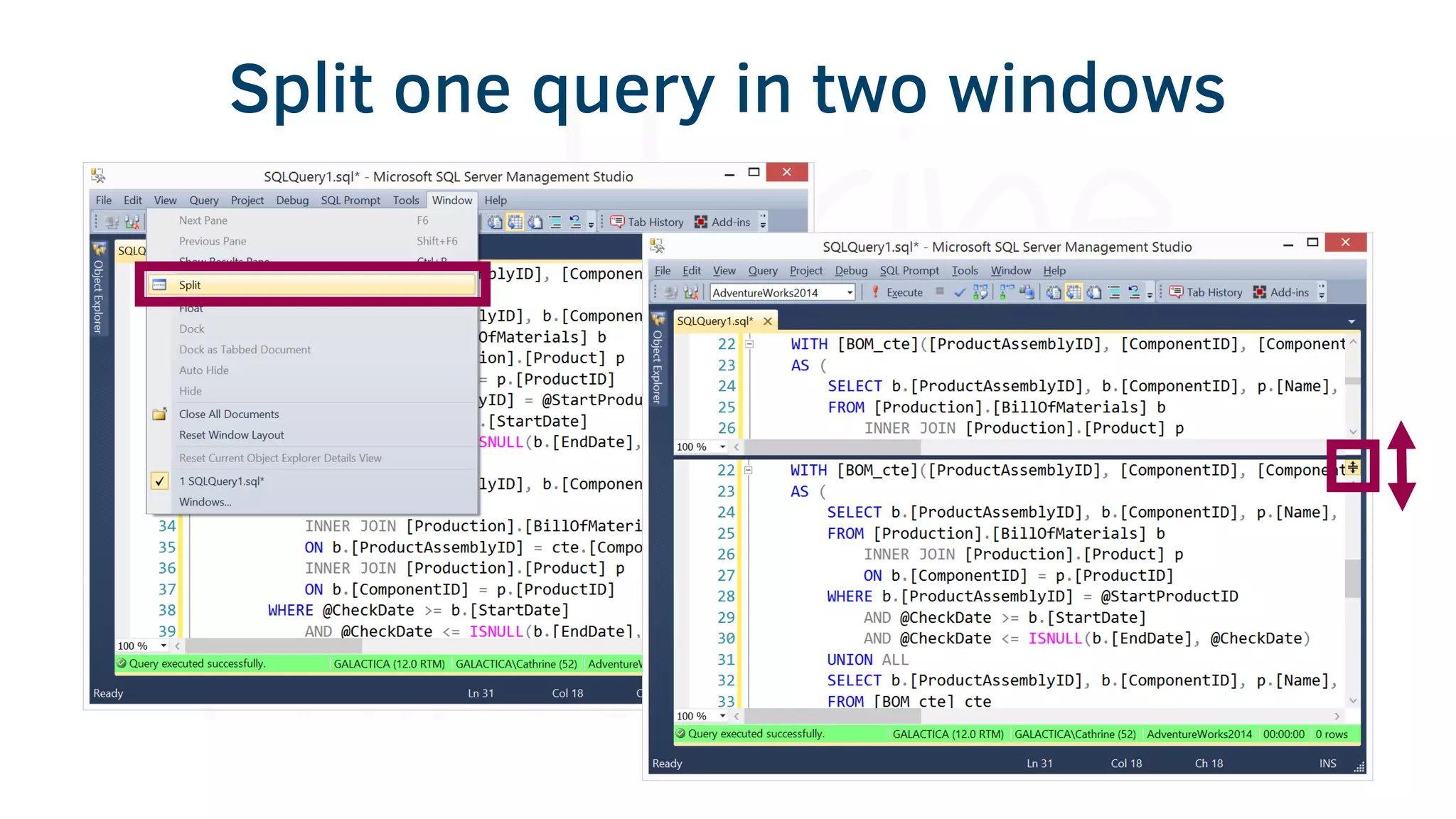

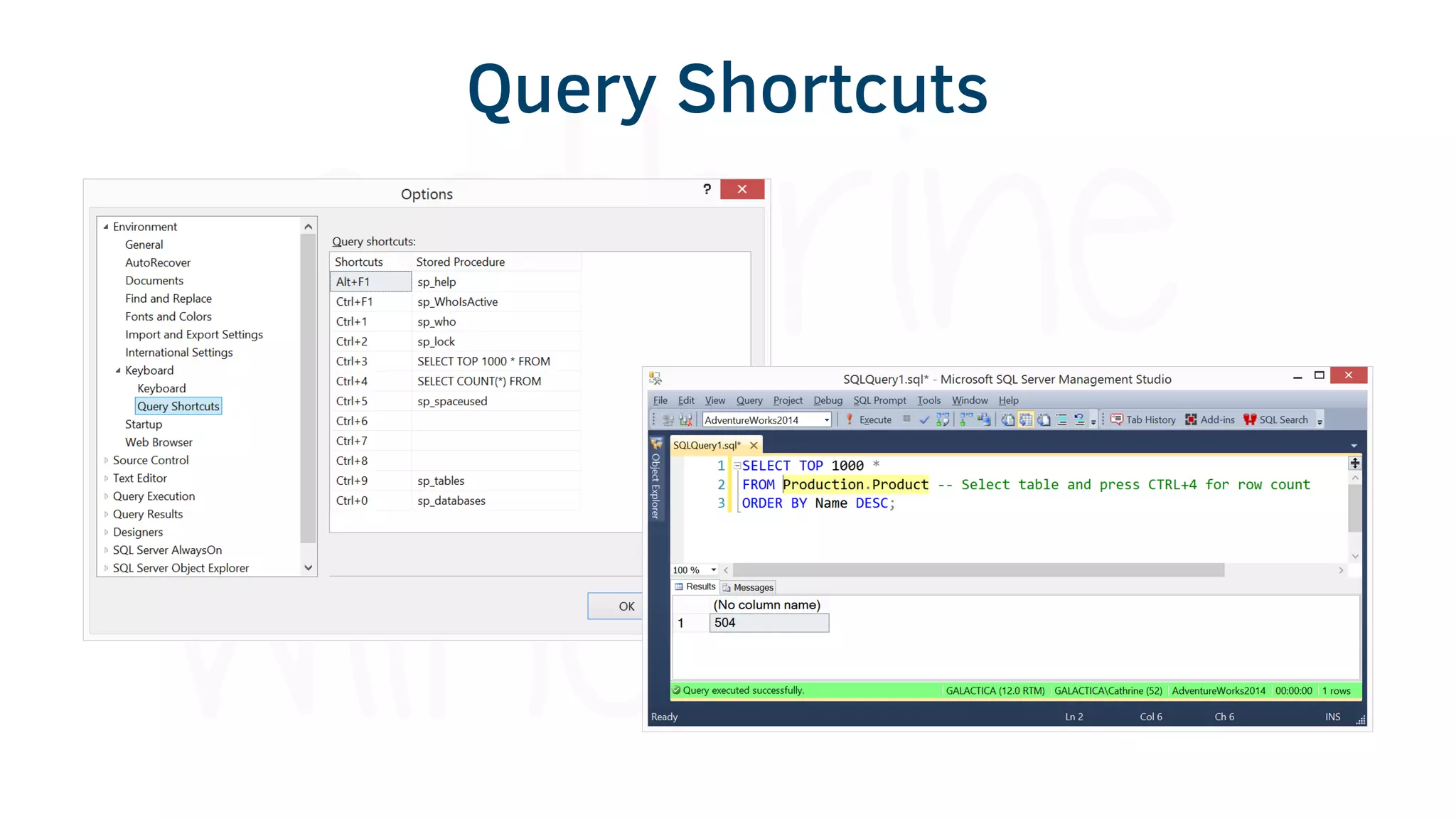
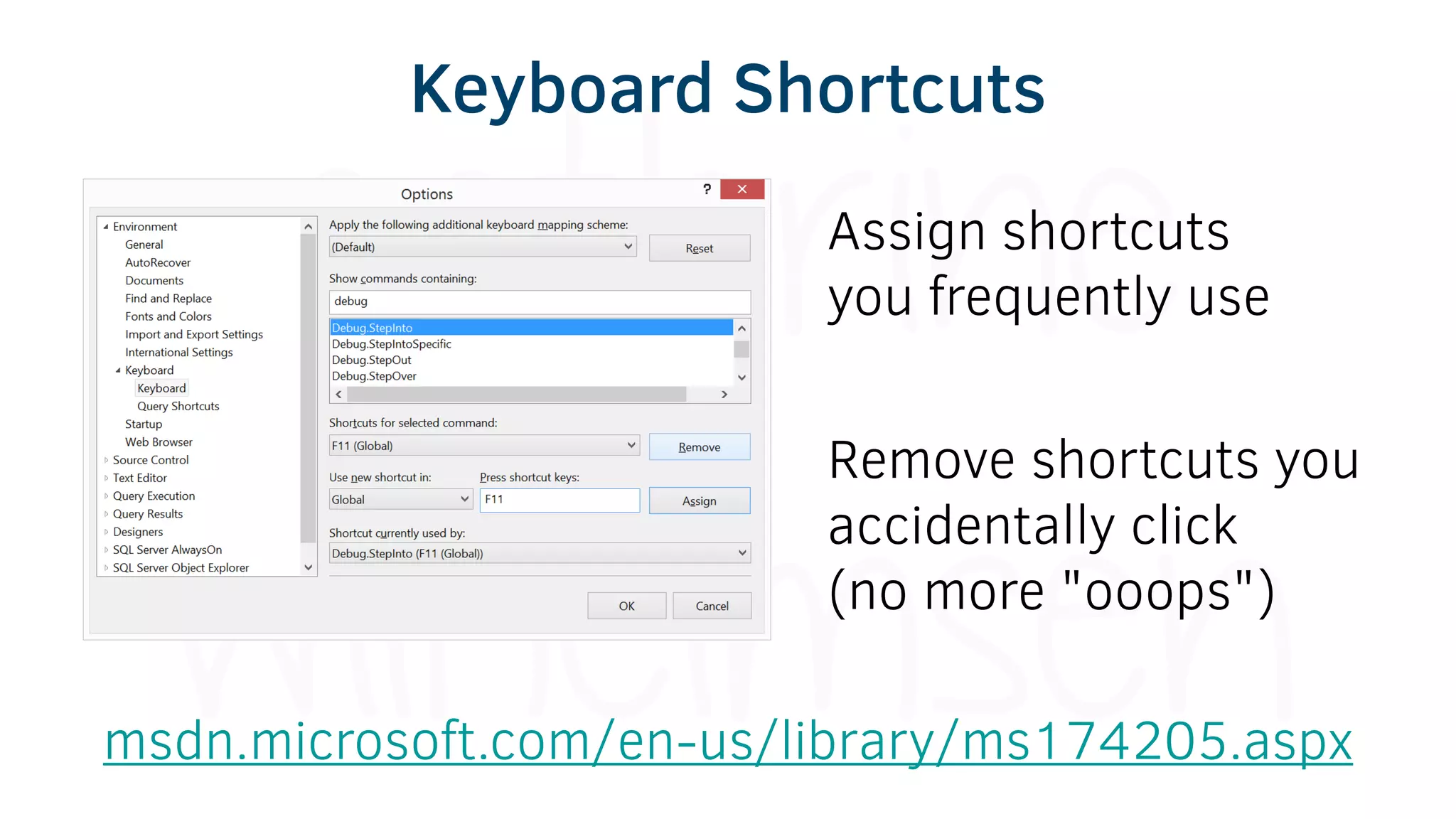
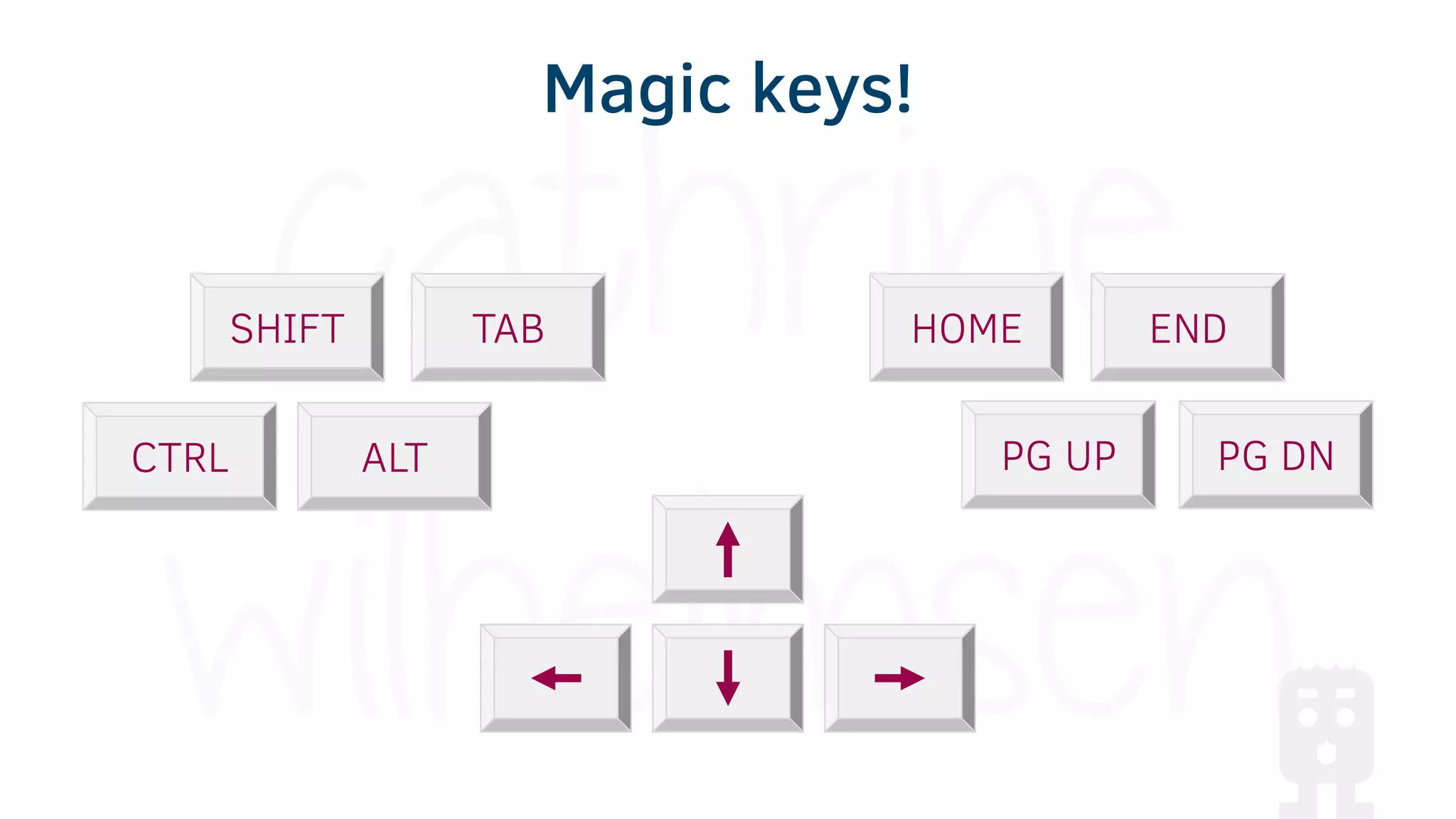



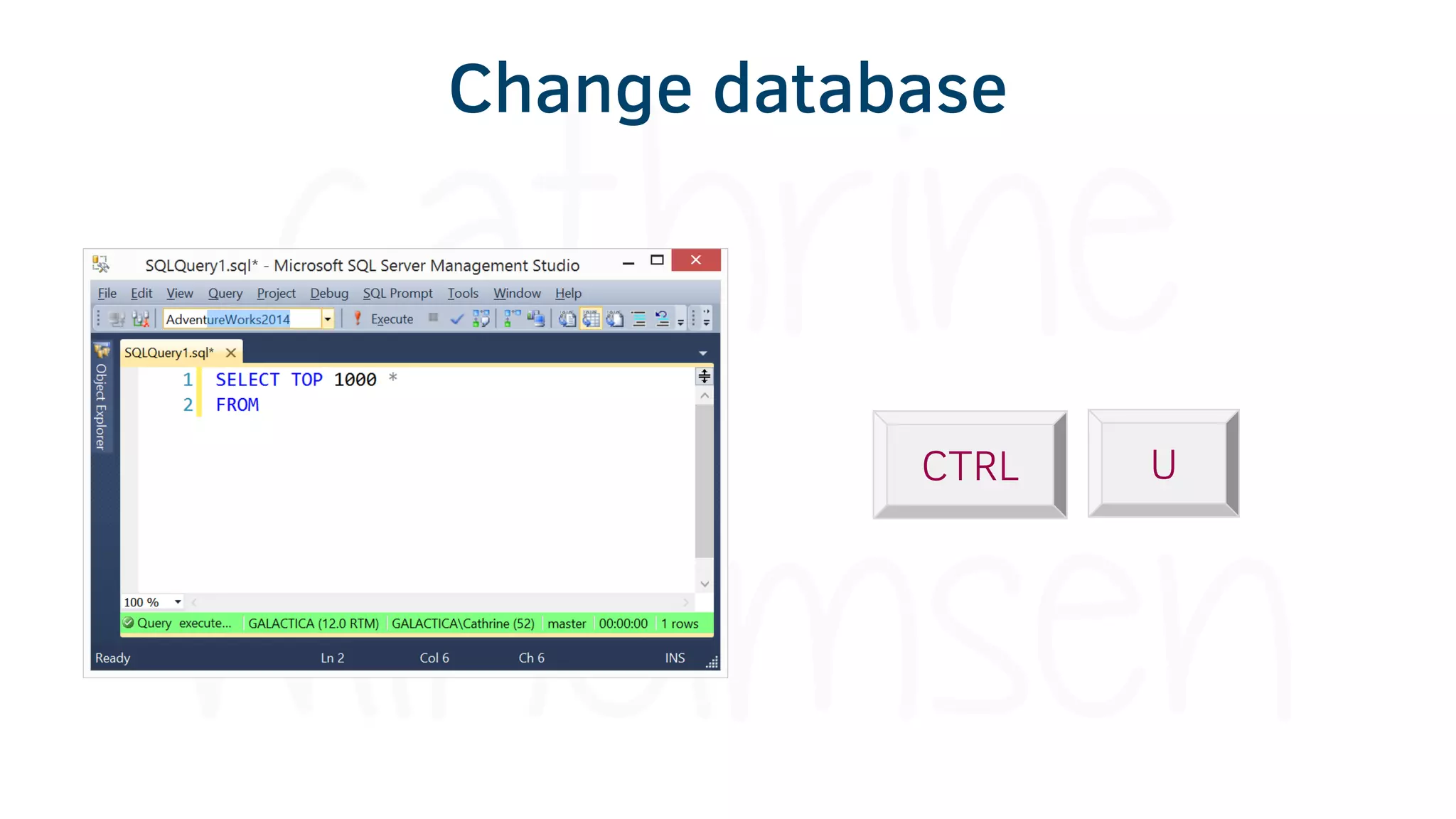
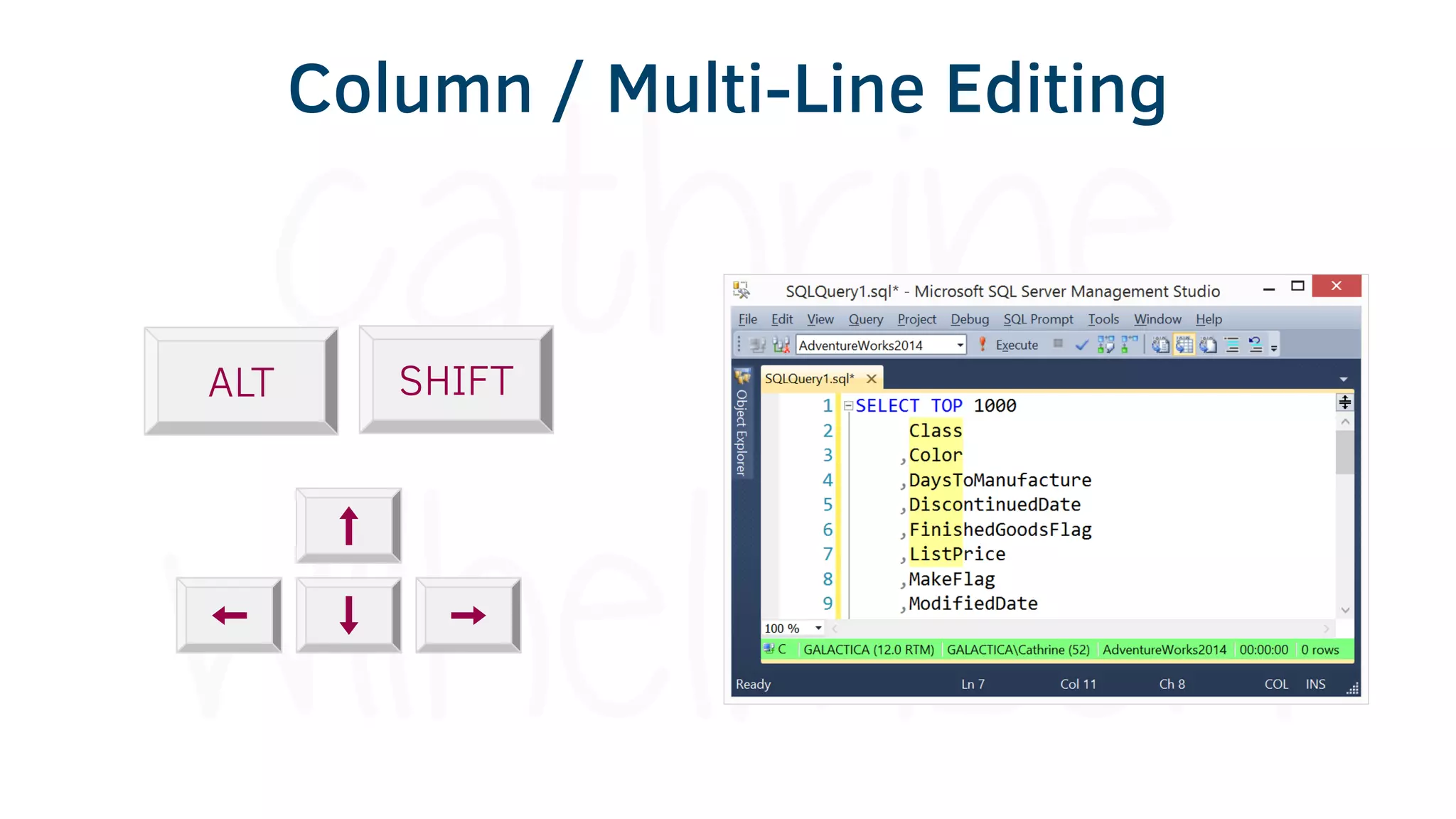
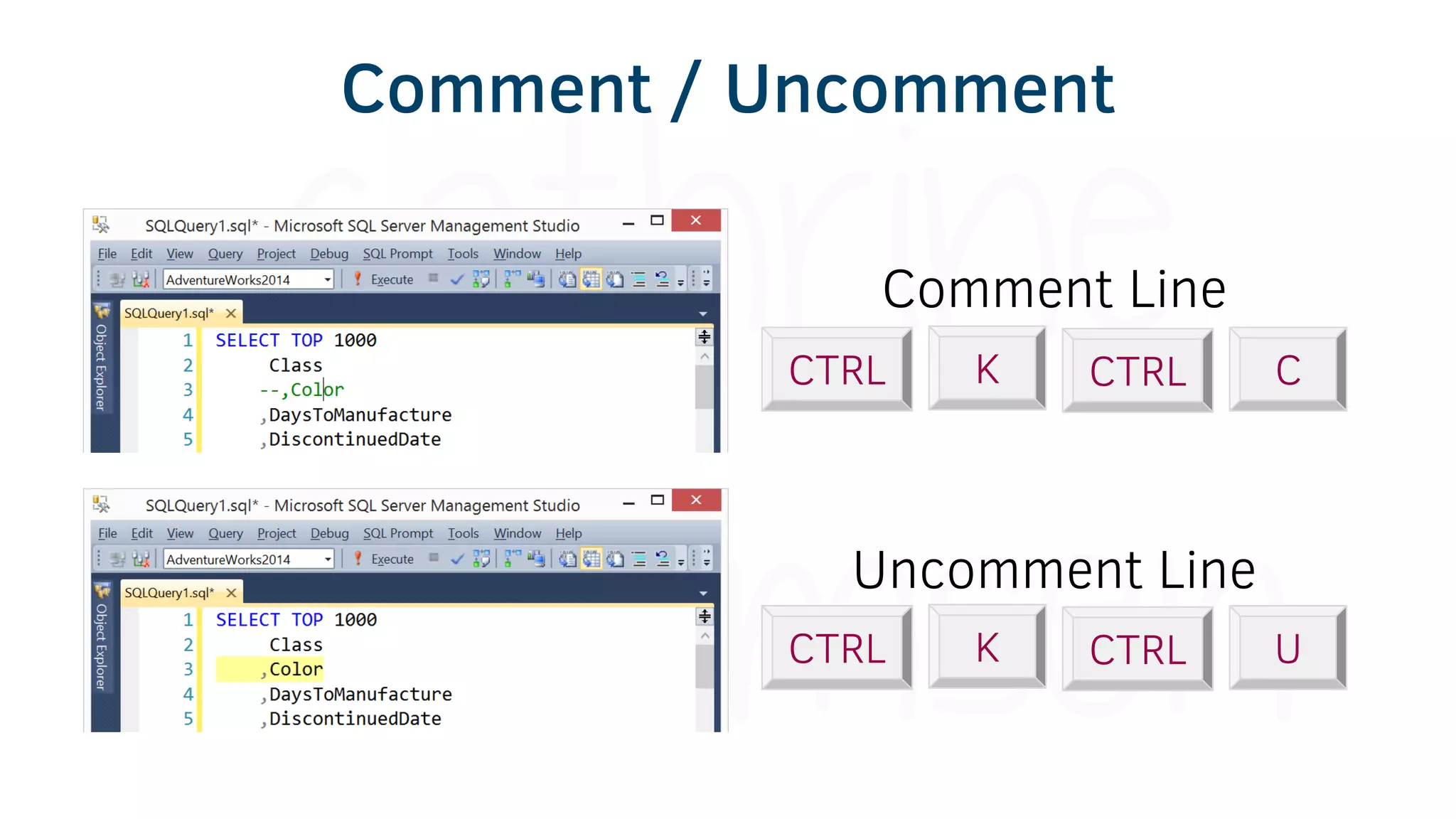
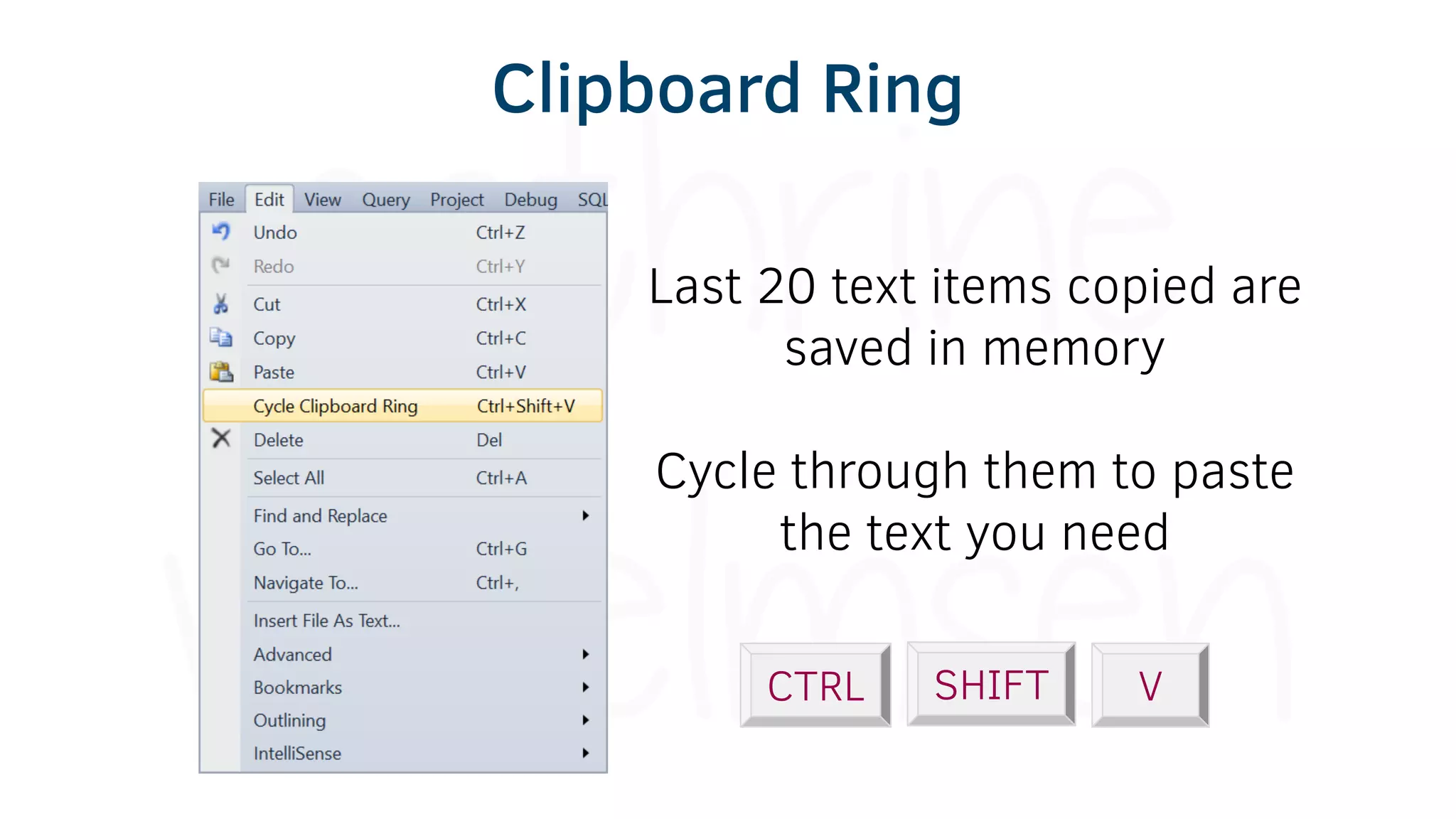

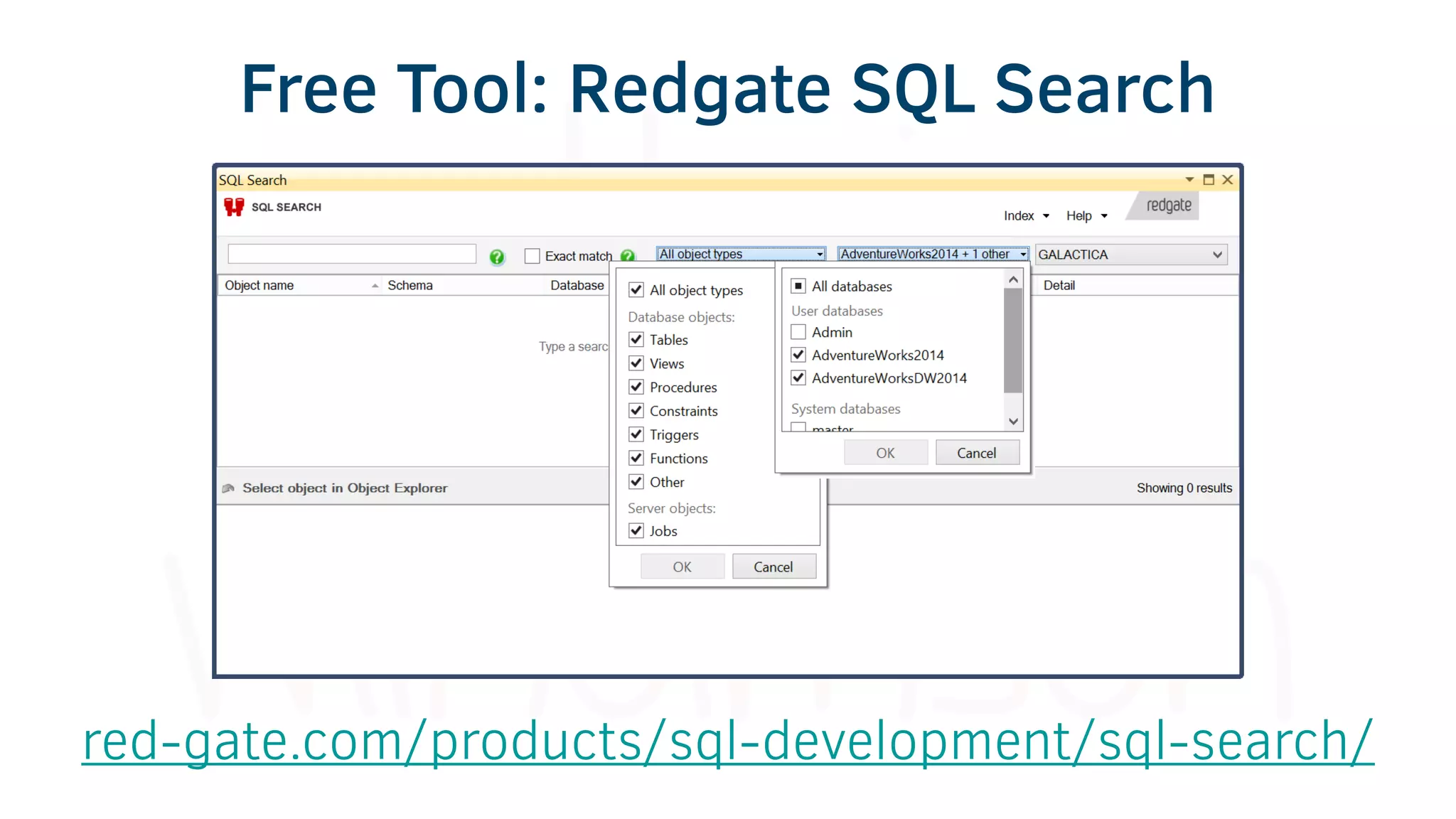
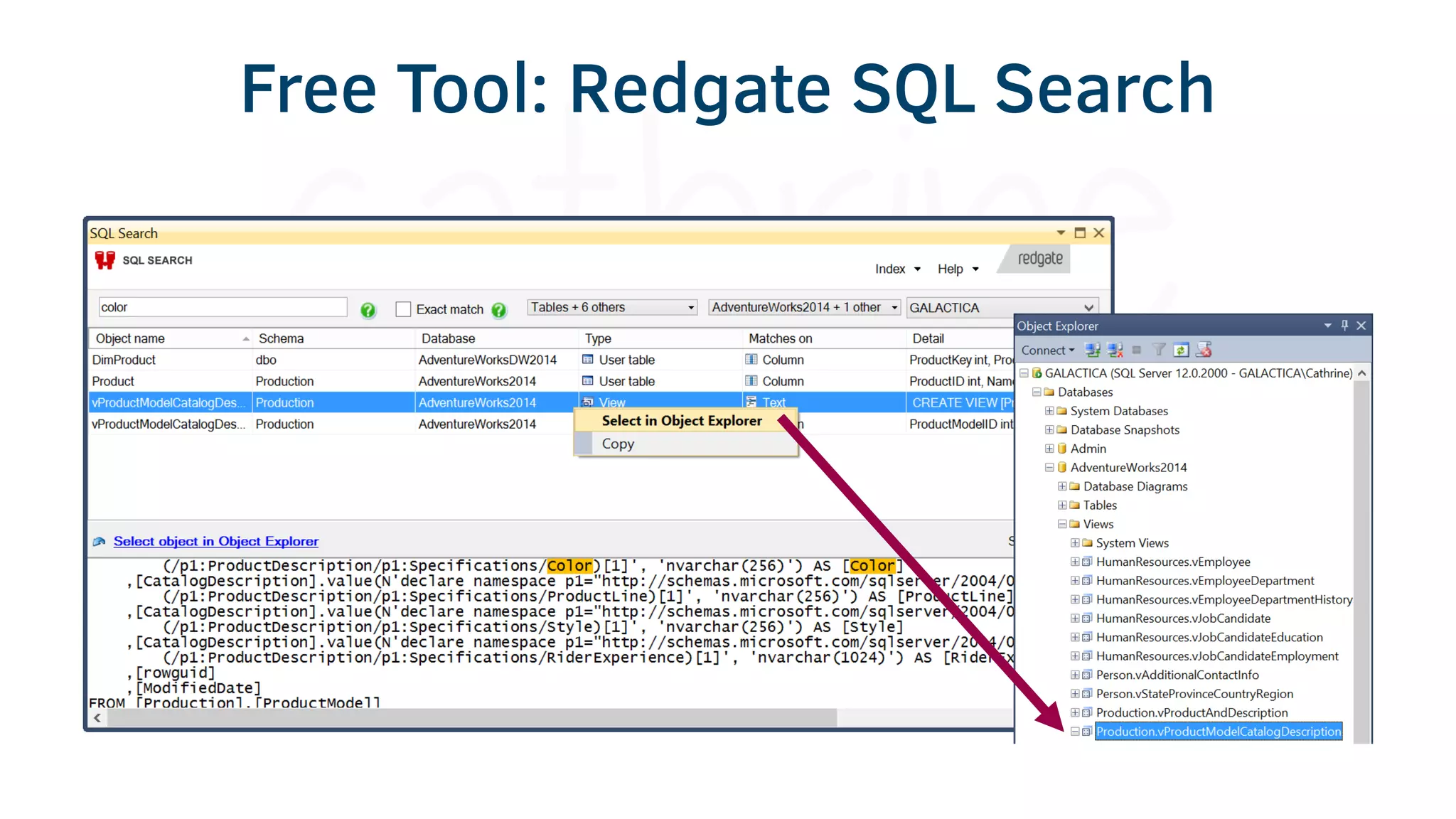


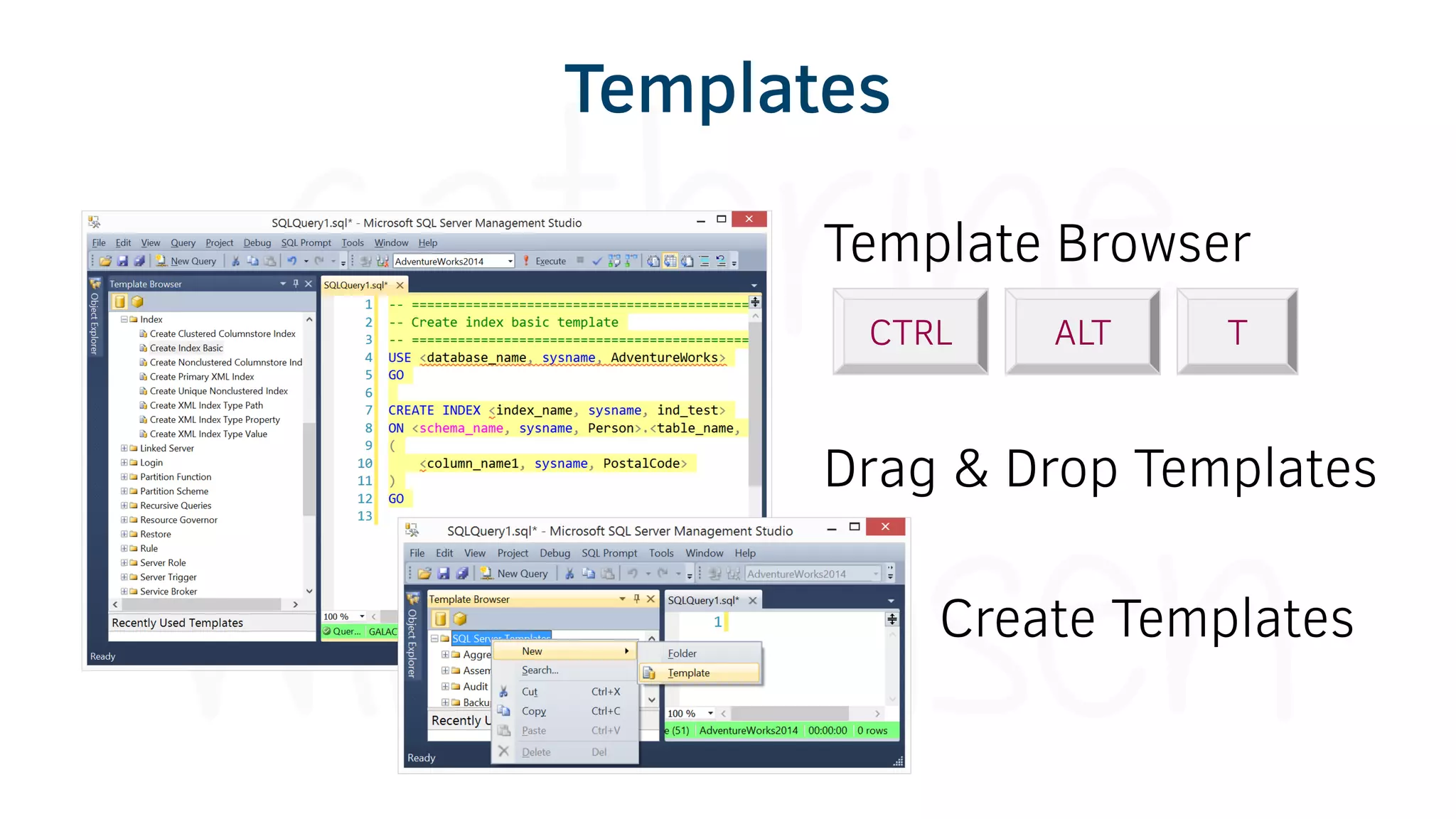
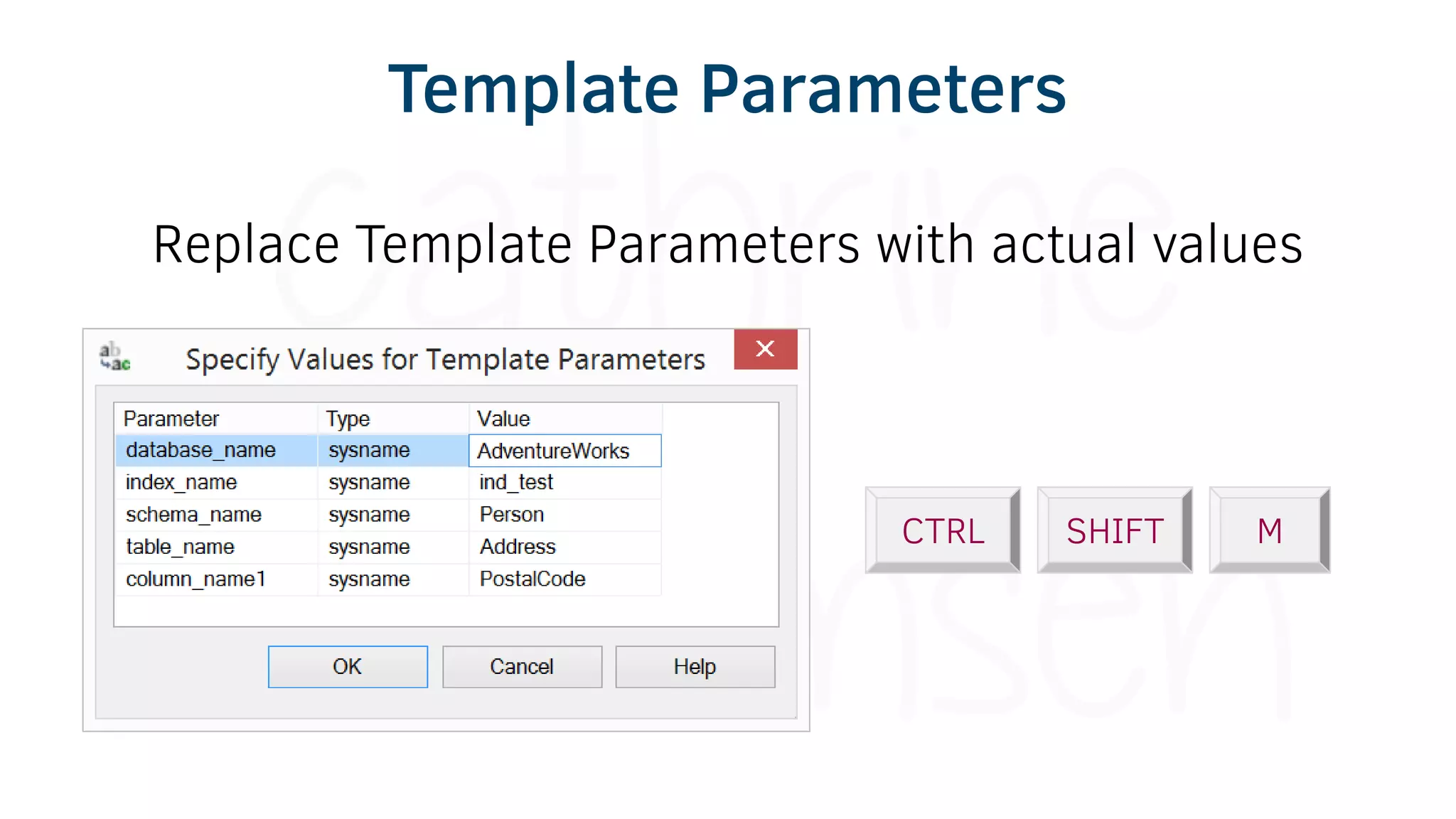
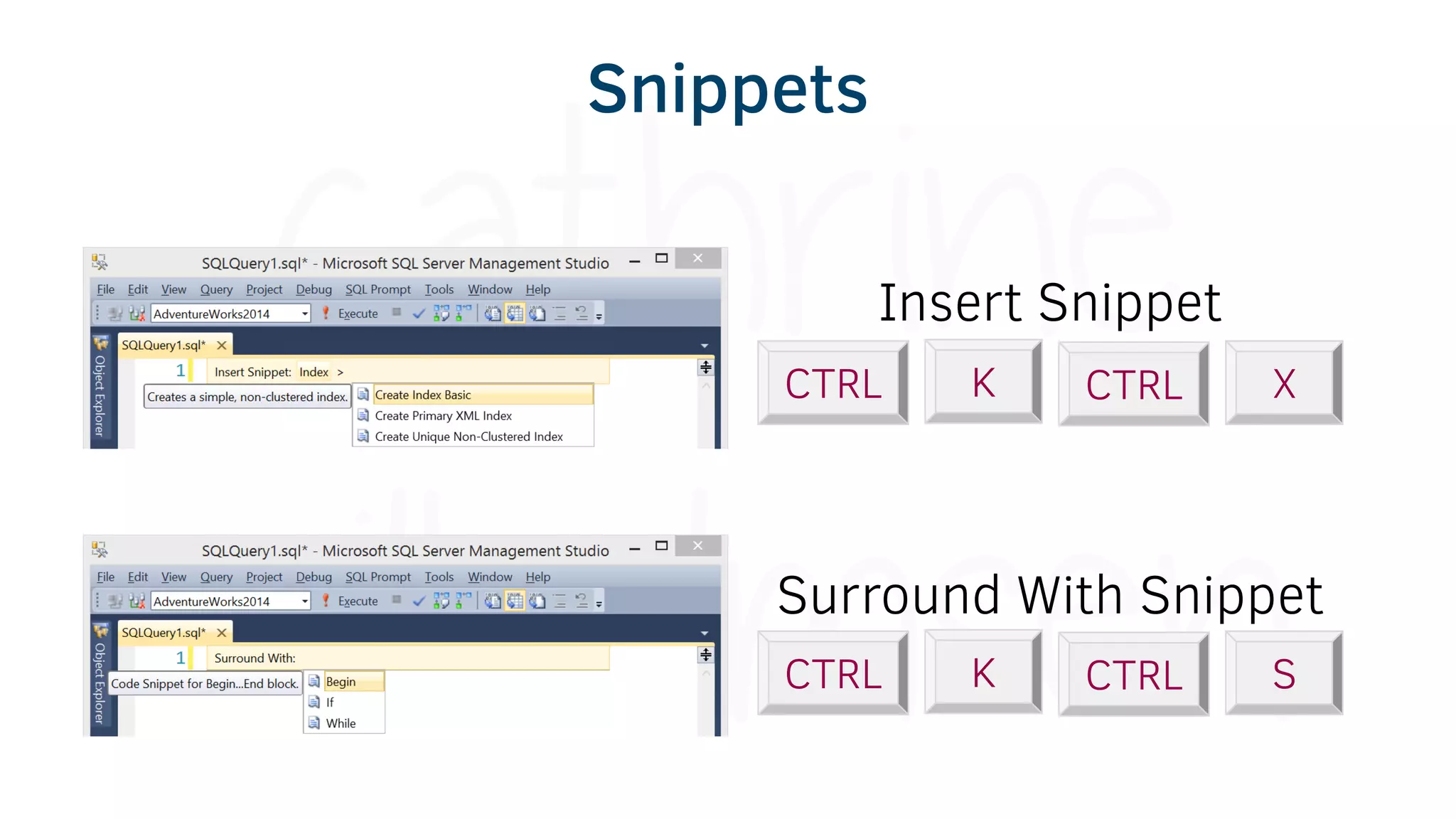



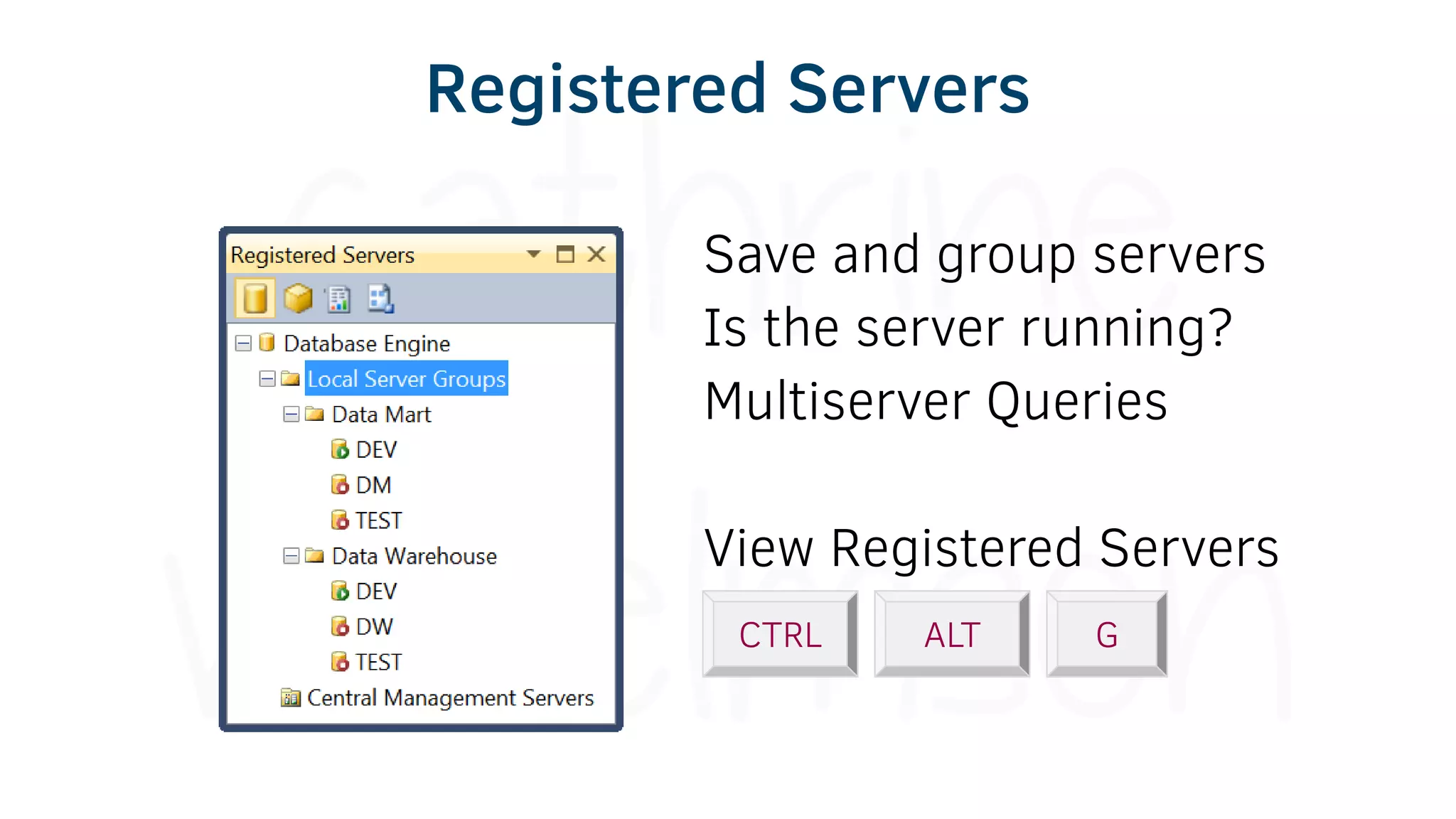
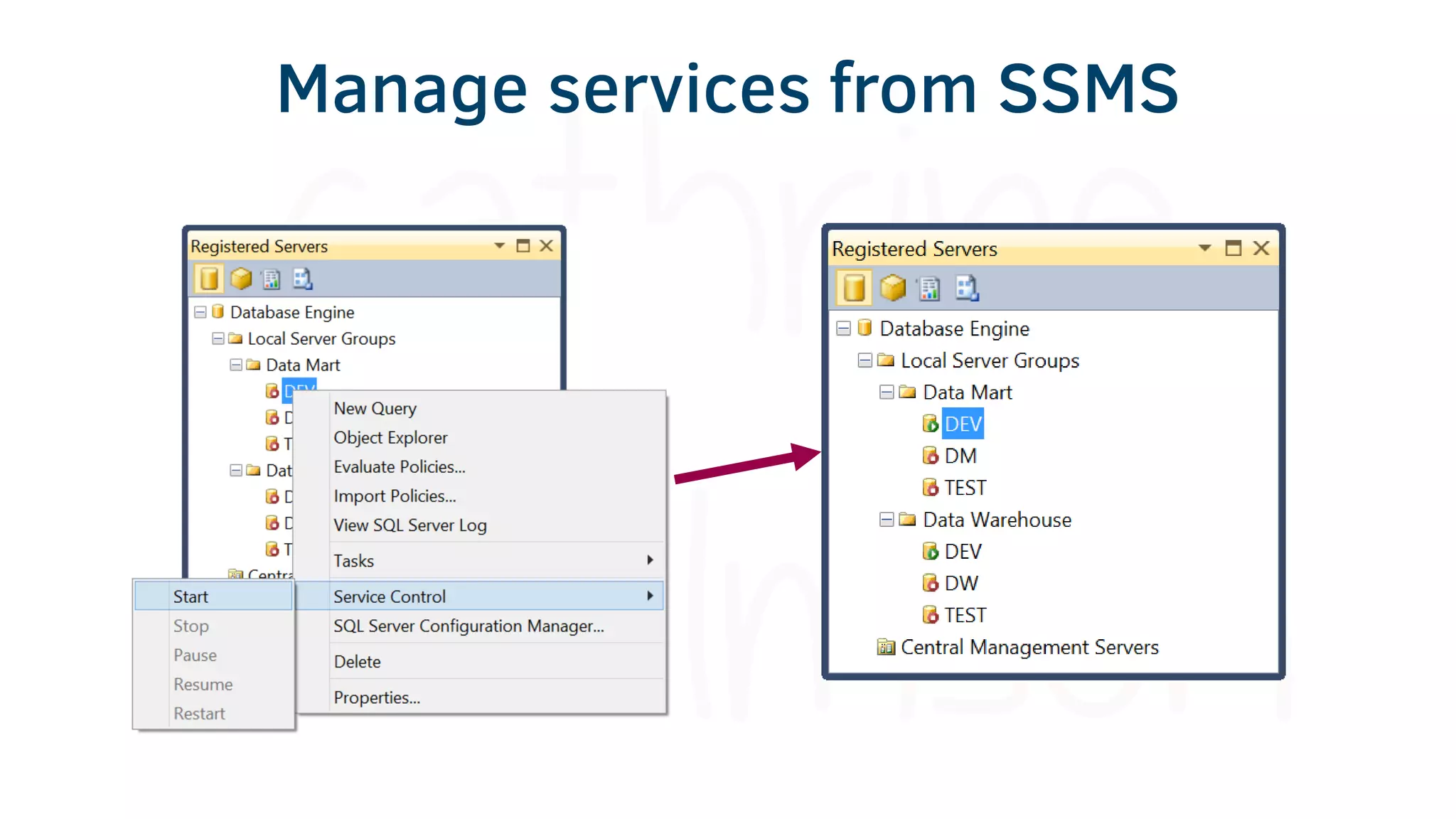
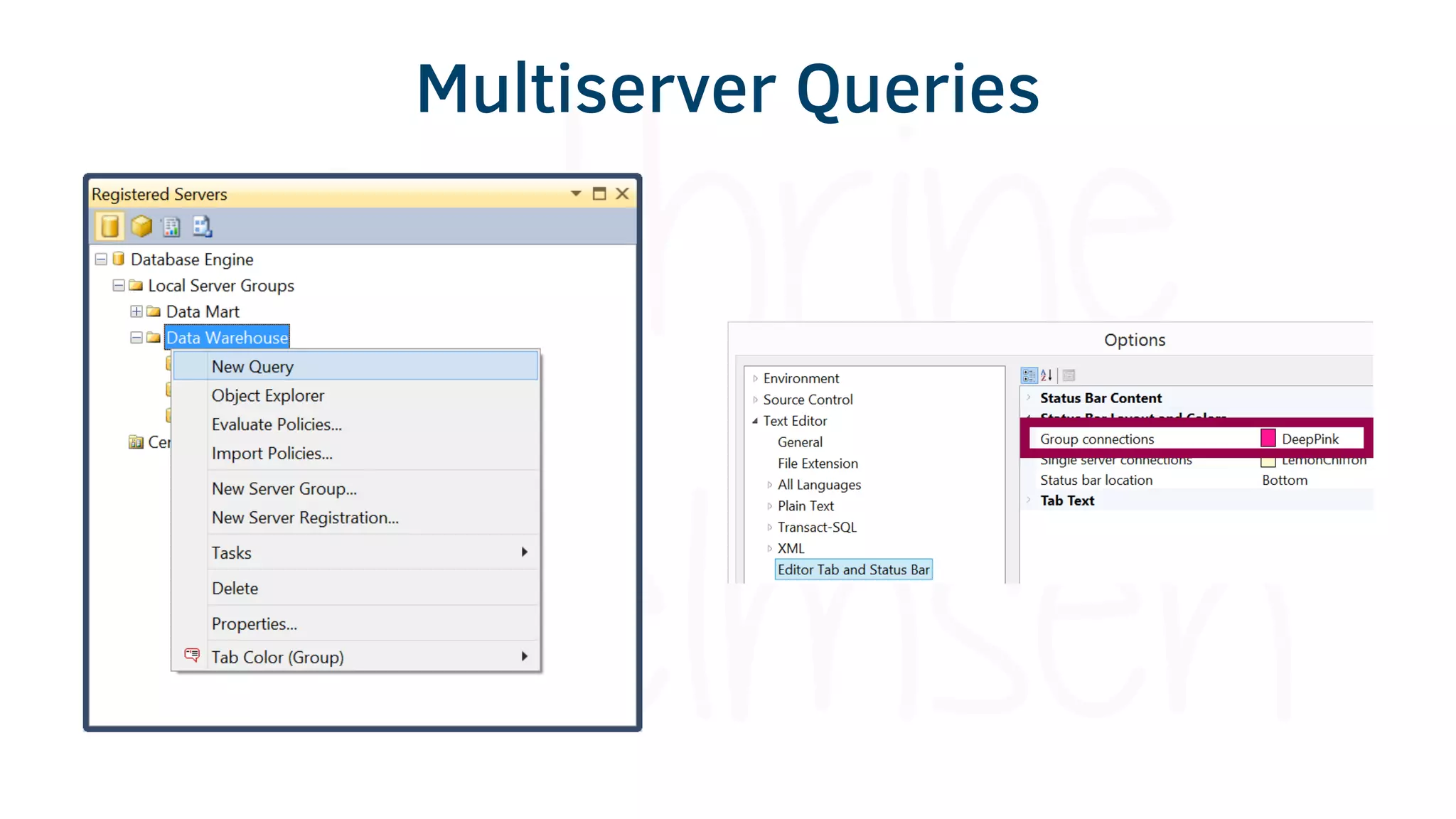
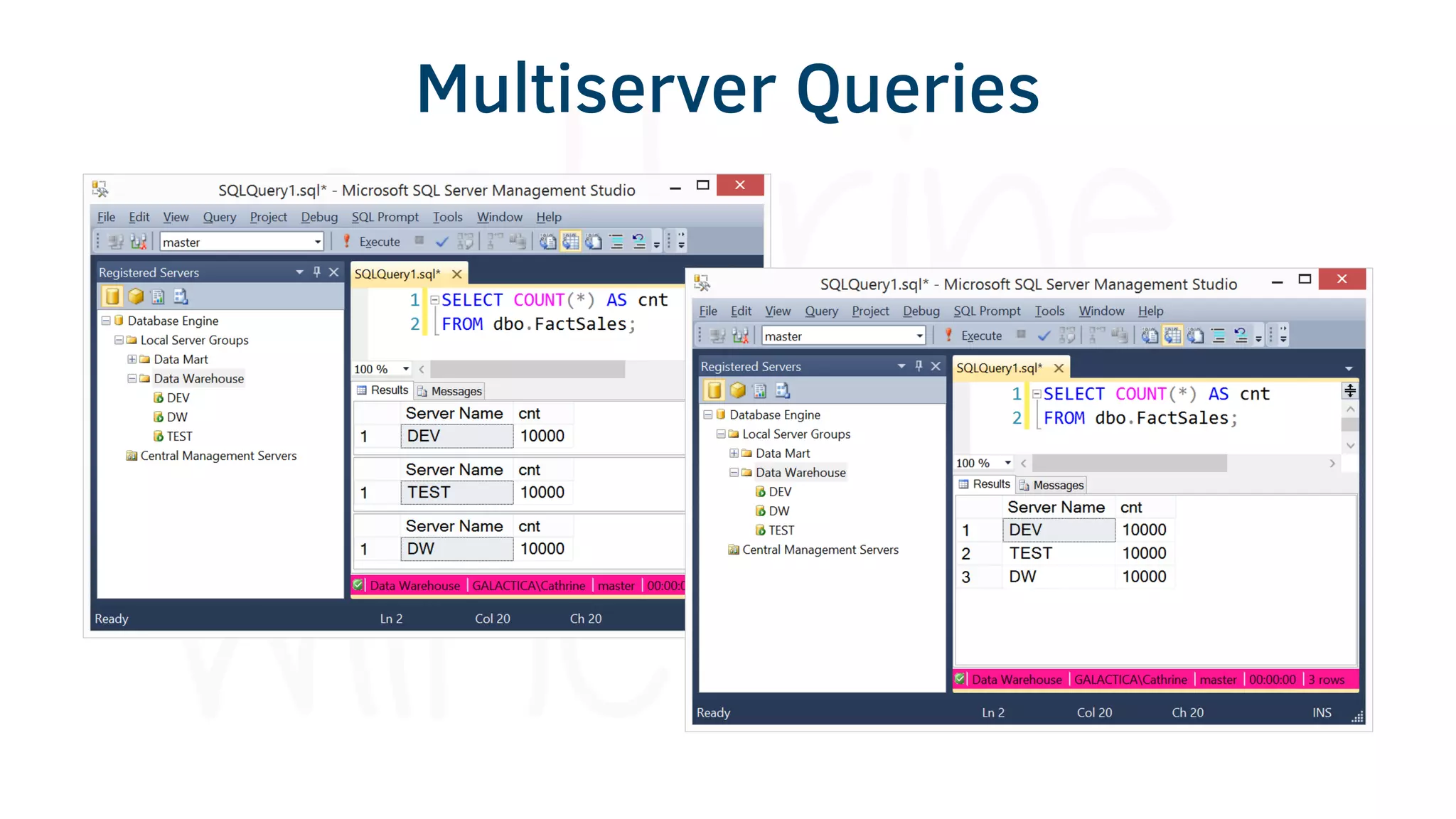

















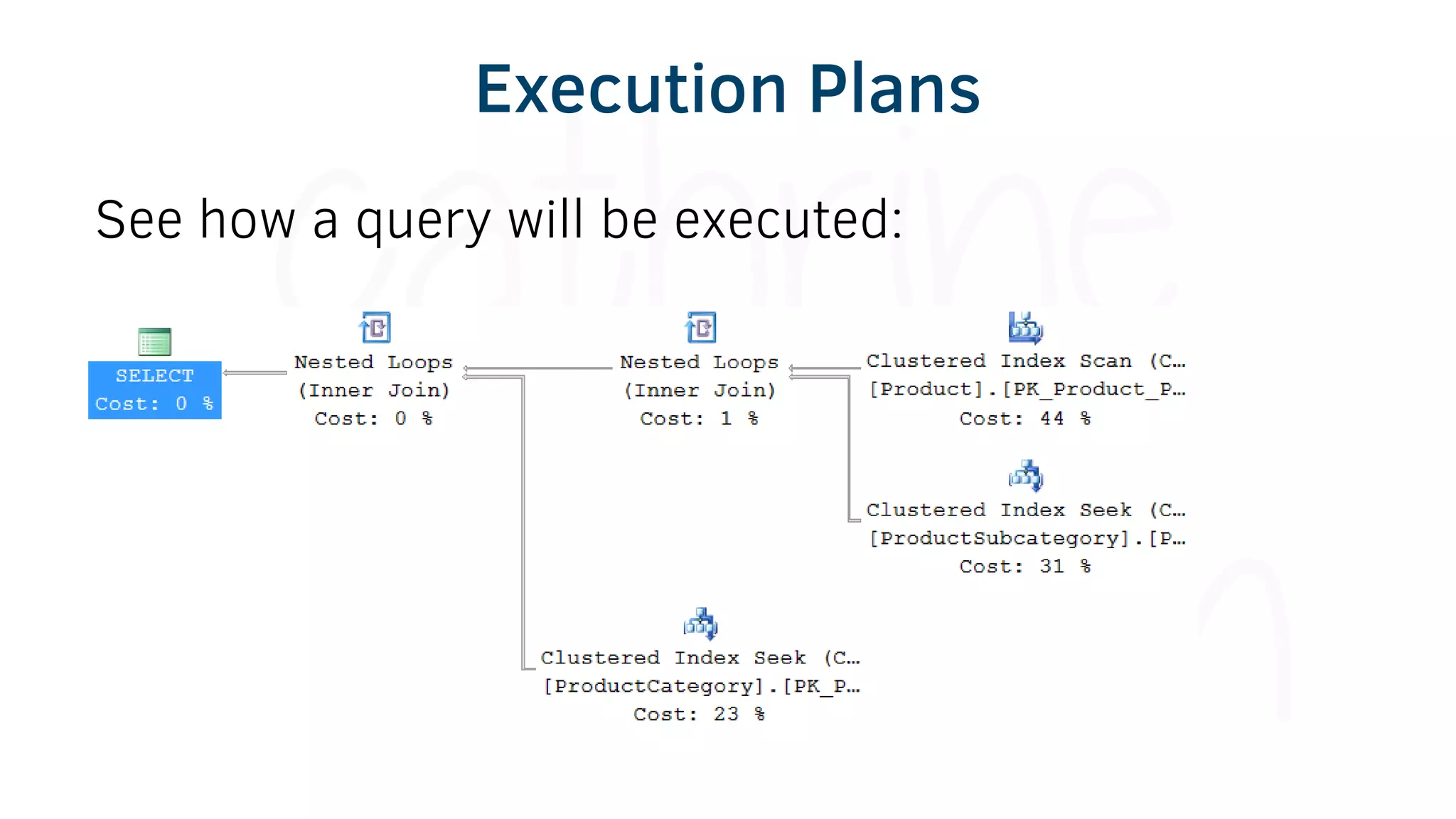
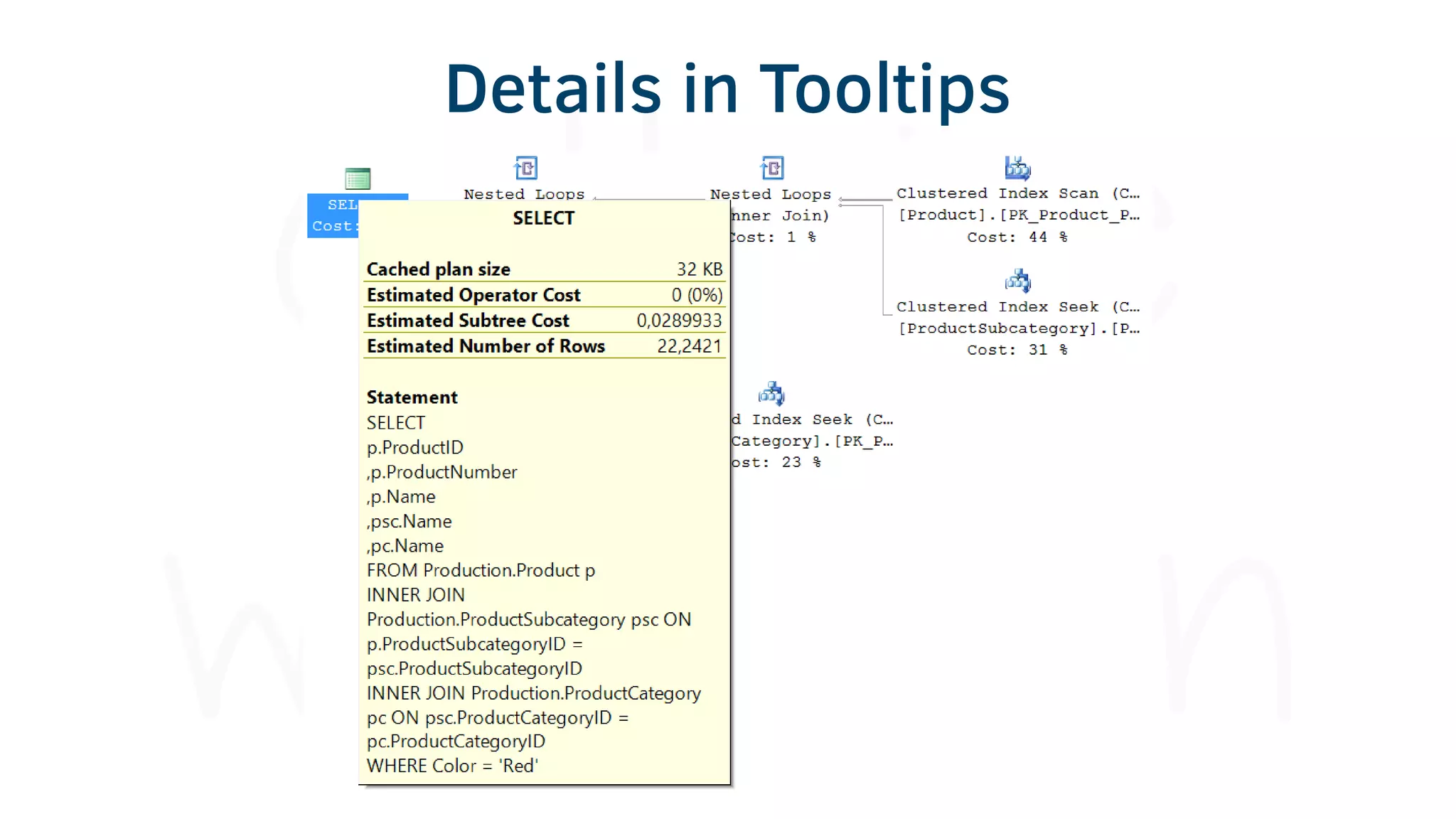
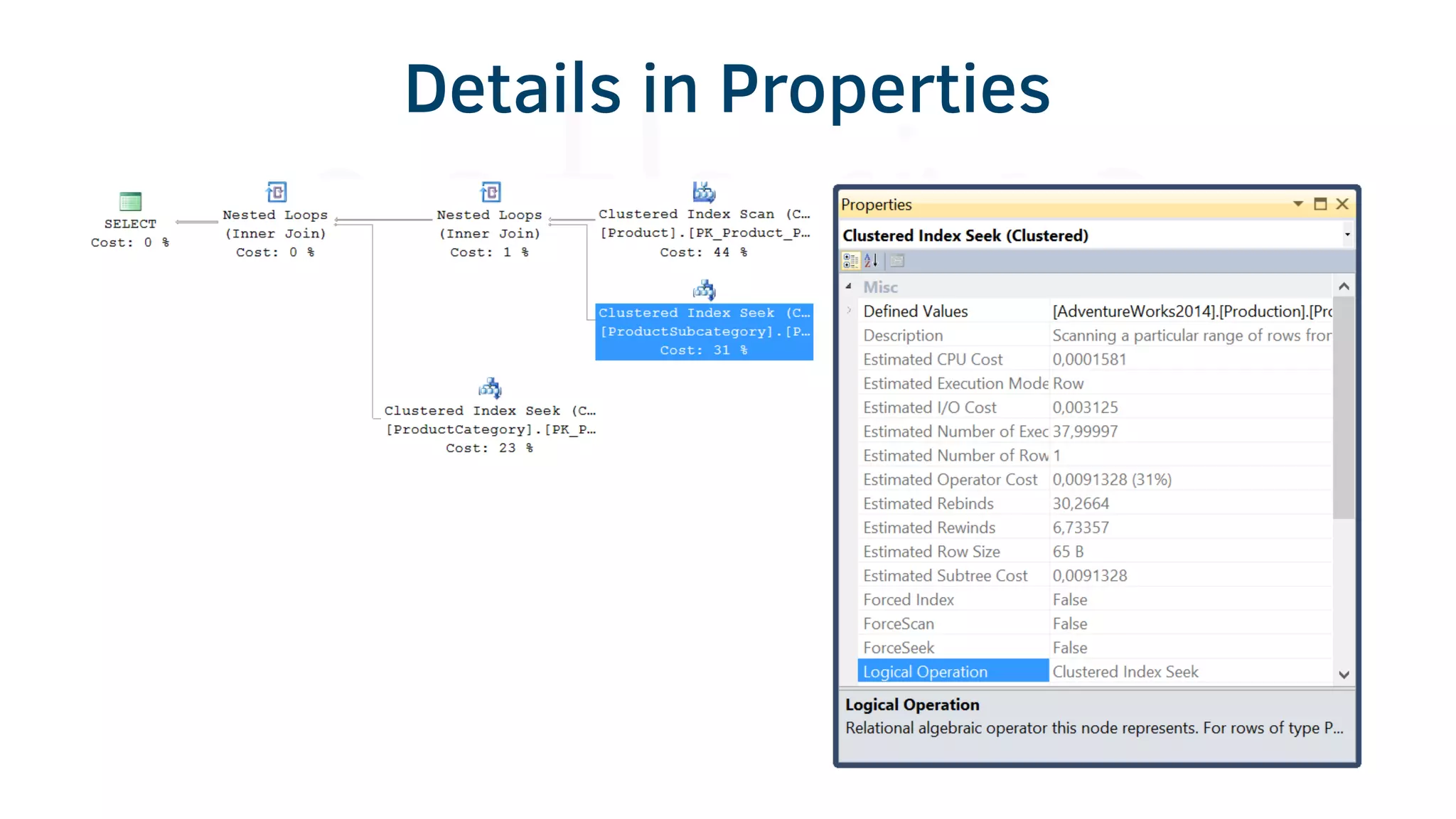
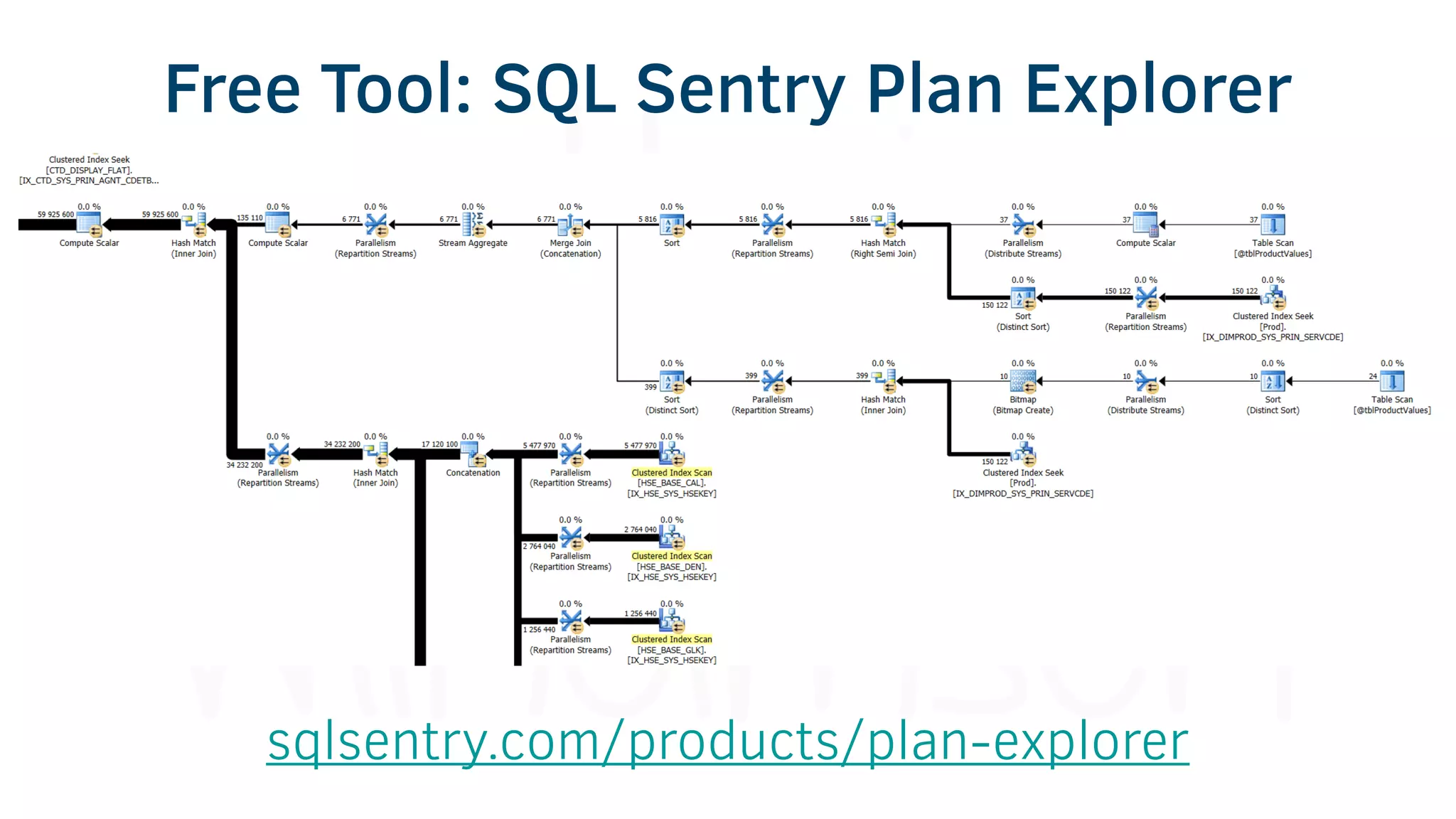
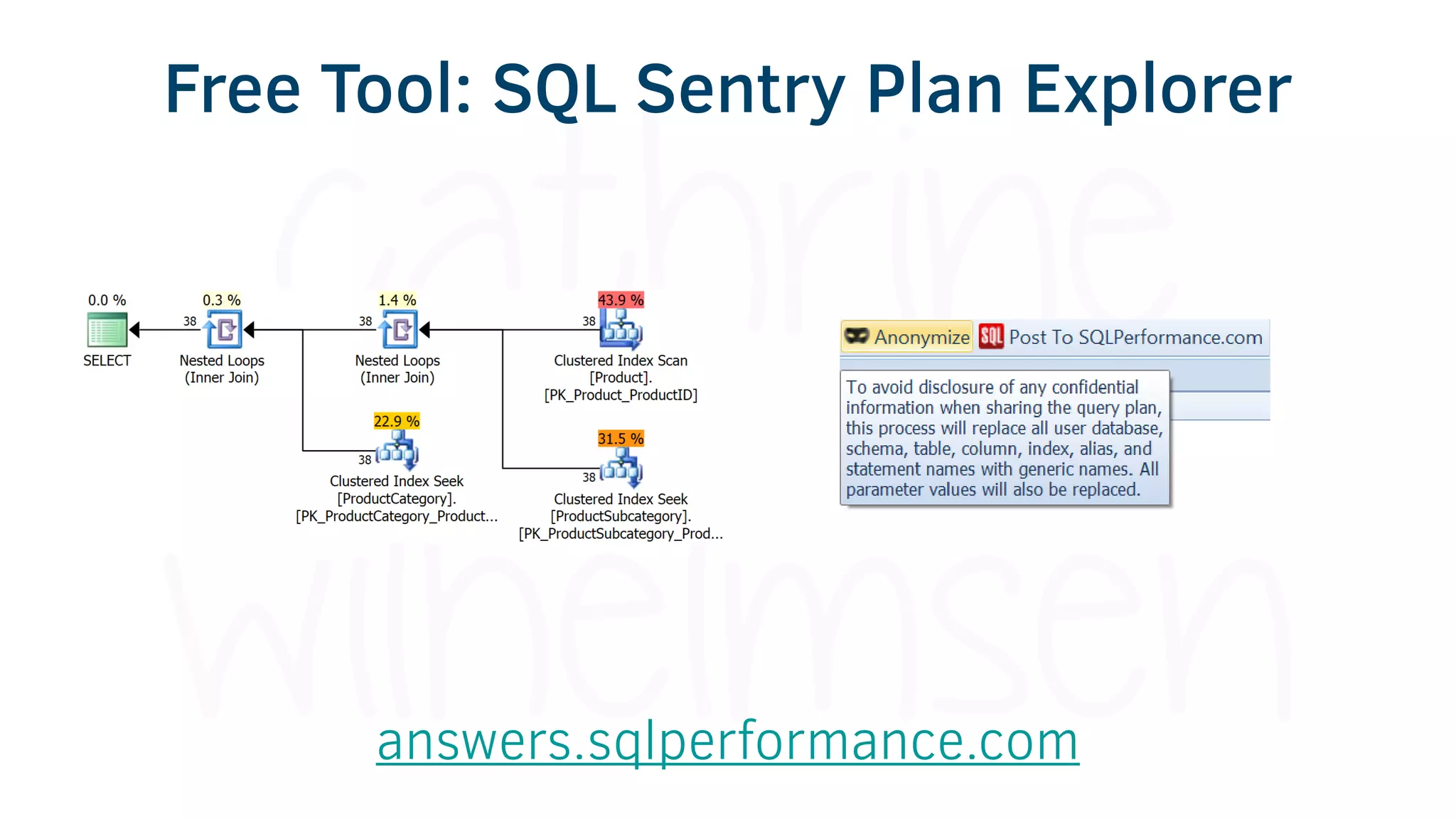

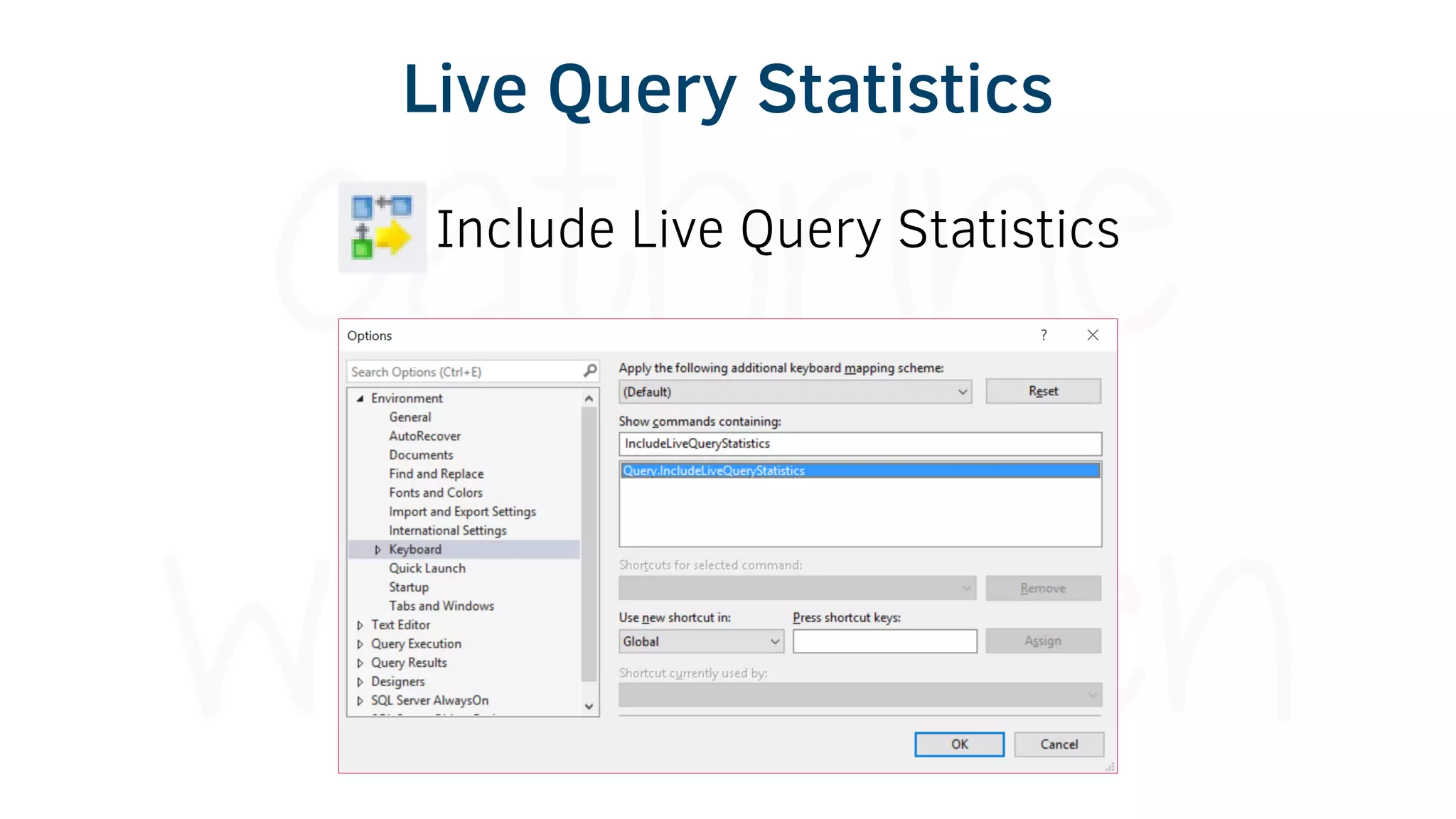
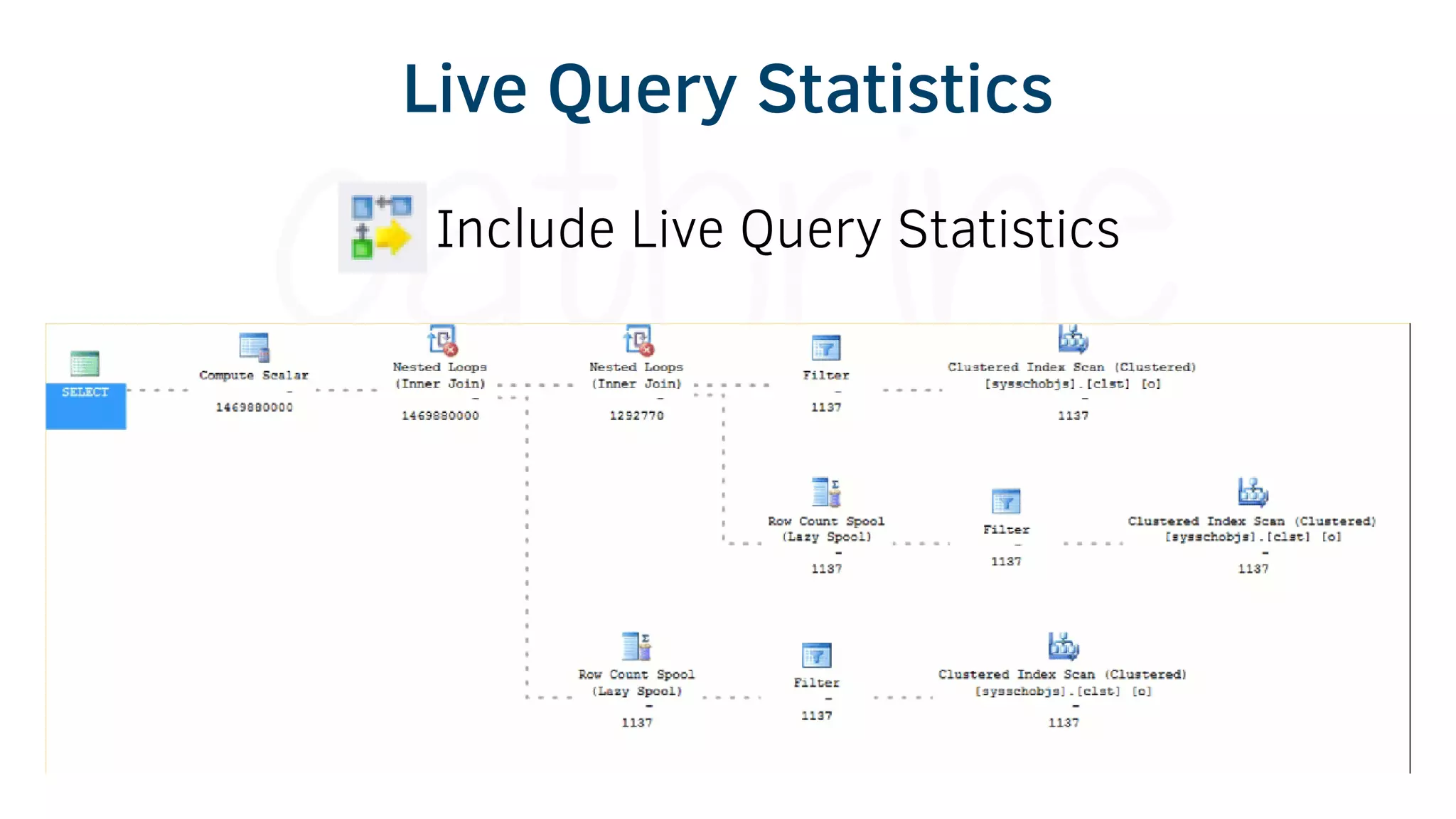





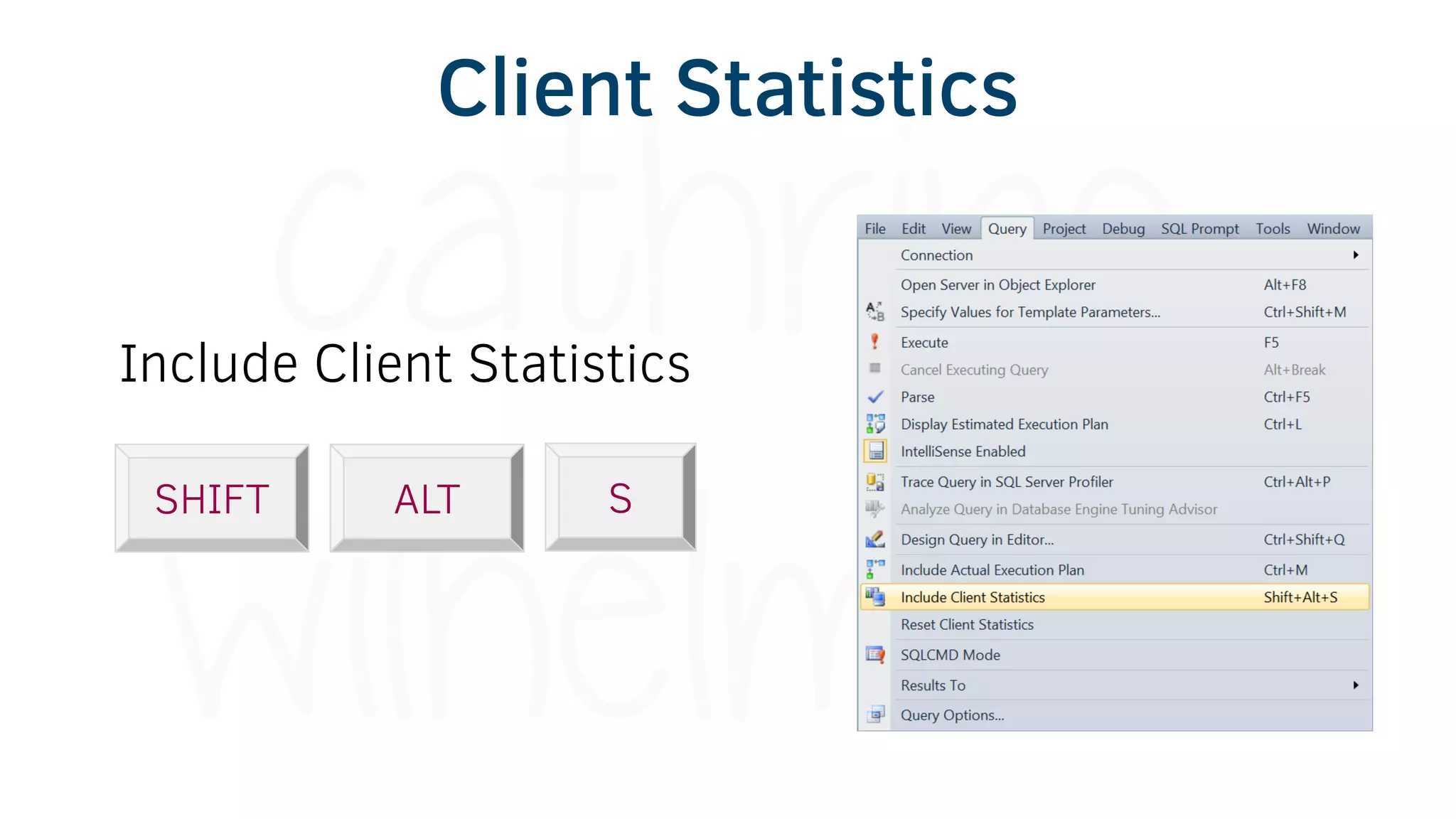
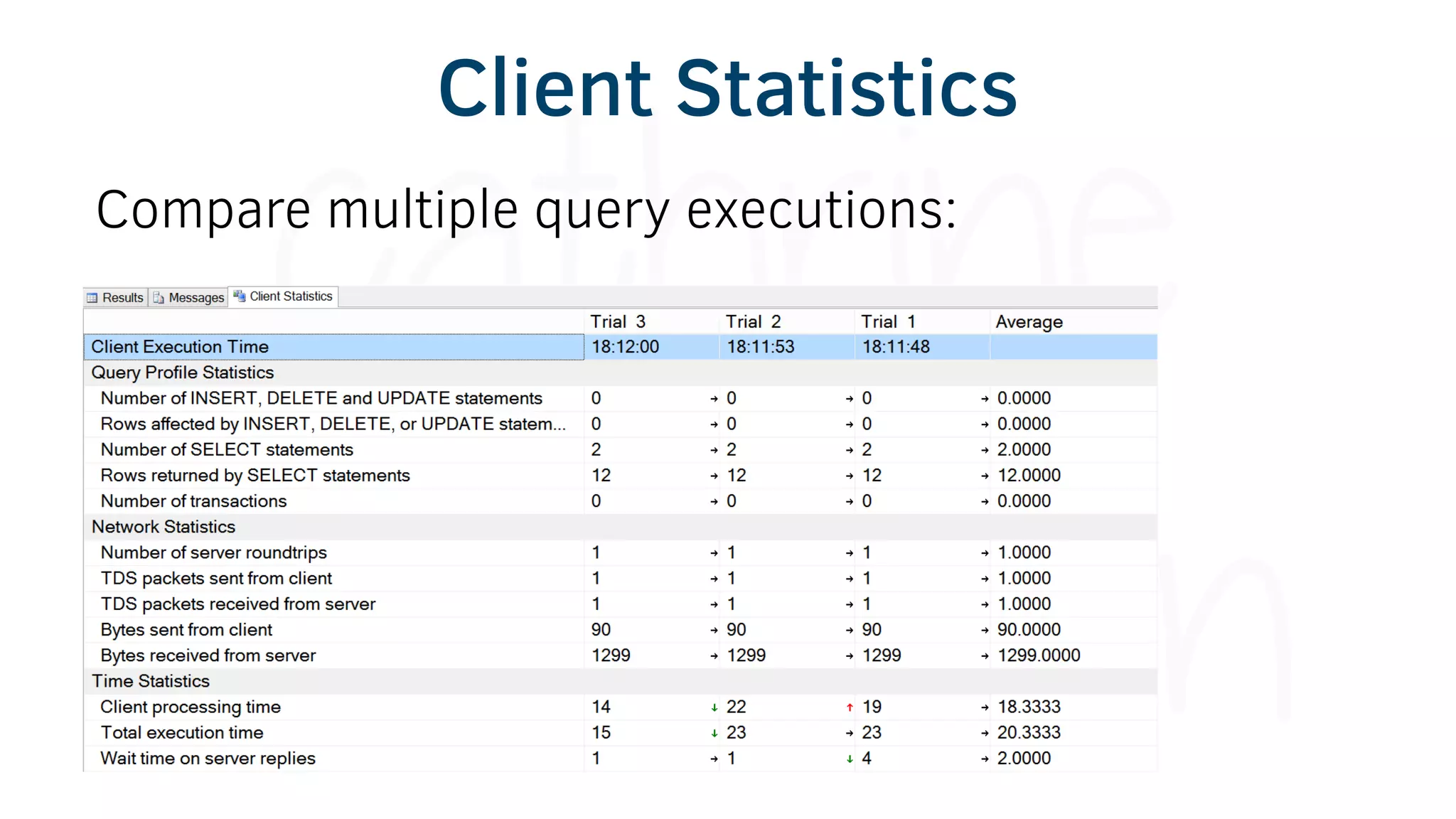















The document provides various tools and tips for becoming an efficient data warehouse developer, including shortcuts for SQL Server Management Studio (SSMS), search tools, and coding best practices. It emphasizes the importance of 'sargable' queries for performance and offers insights into query execution plans and monitoring. Additionally, it introduces Business Intelligence Markup Language (BIML) for automating SSIS package creation.
























































![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)