The model interacts with the environment seeking ways to maximize the reward. There is a feedback from the environment.
1.
Data Preprocessing
Master’s Degreein Data Science - Advanced Methods in Machine Learning
Ángela Fernández Pascual
Escuela Politécnica Superior
Universidad Autónoma de Madrid
Academic Year 2024–25
Data Preprocessing MachineLearning Systems
Machine Learning Systems
1 Collecting data: measuring devices, acquisition sensors, databases,...
2 Preprocessing mechanisms
• Data cleaning
• Data transformation
• Dimensionality reduction
3 Learning algorithms ⇒ Models
• Supervised models
• Unsupervised models
• Semi-supervised models
4 Model evaluation
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 1 / 18
5.
Data Preprocessing DataPreprocessing
Data Preprocessing
Data Preprocessing
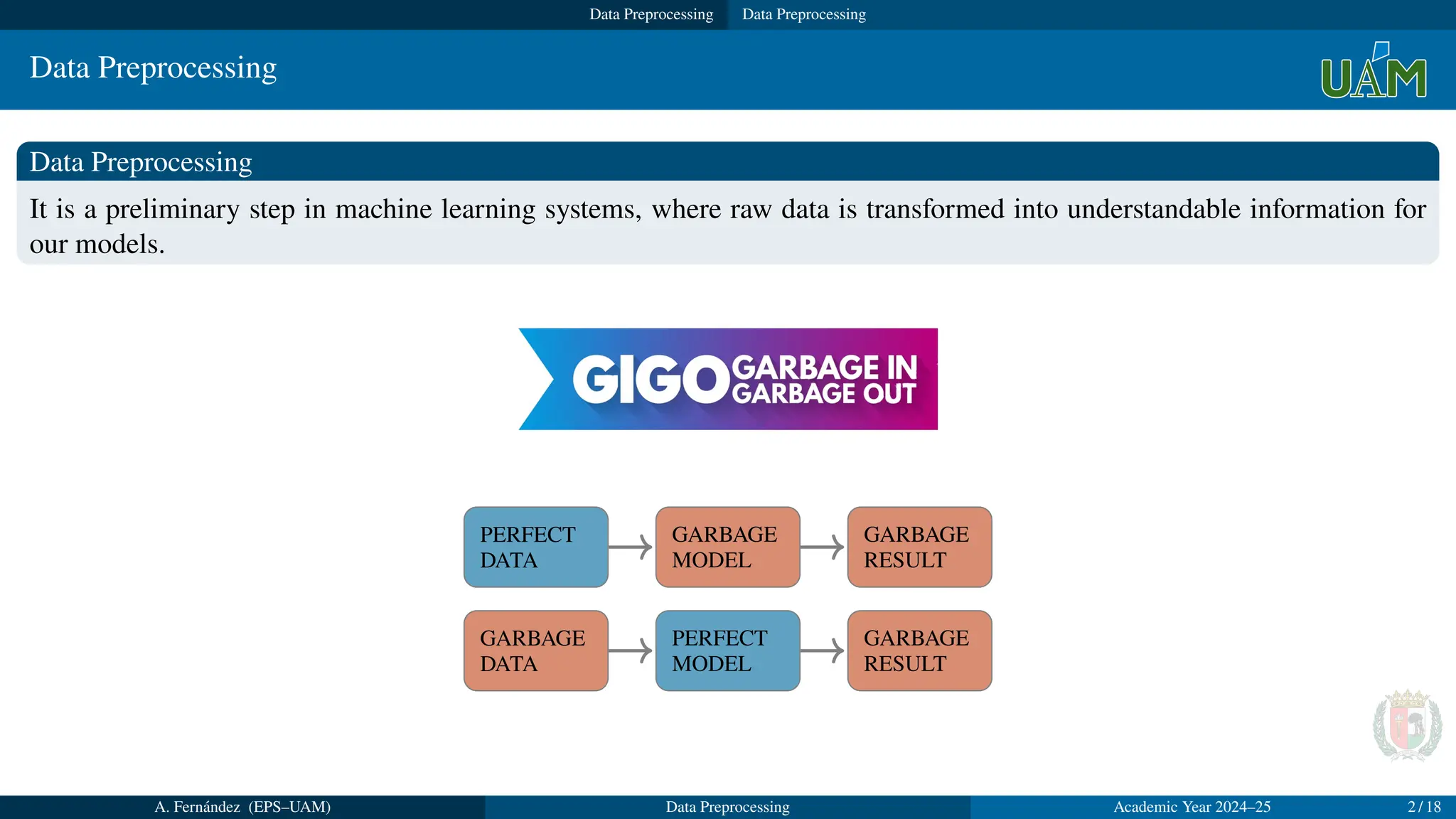
It is a preliminary step in machine learning systems, where raw data is transformed into understandable information for
our models.
PERFECT
DATA
GARBAGE
MODEL
GARBAGE
RESULT
GARBAGE
DATA
PERFECT
MODEL
GARBAGE
RESULT
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 2 / 18
6.
Data Preprocessing DataPreprocessing
Steps in Data Preprocessing
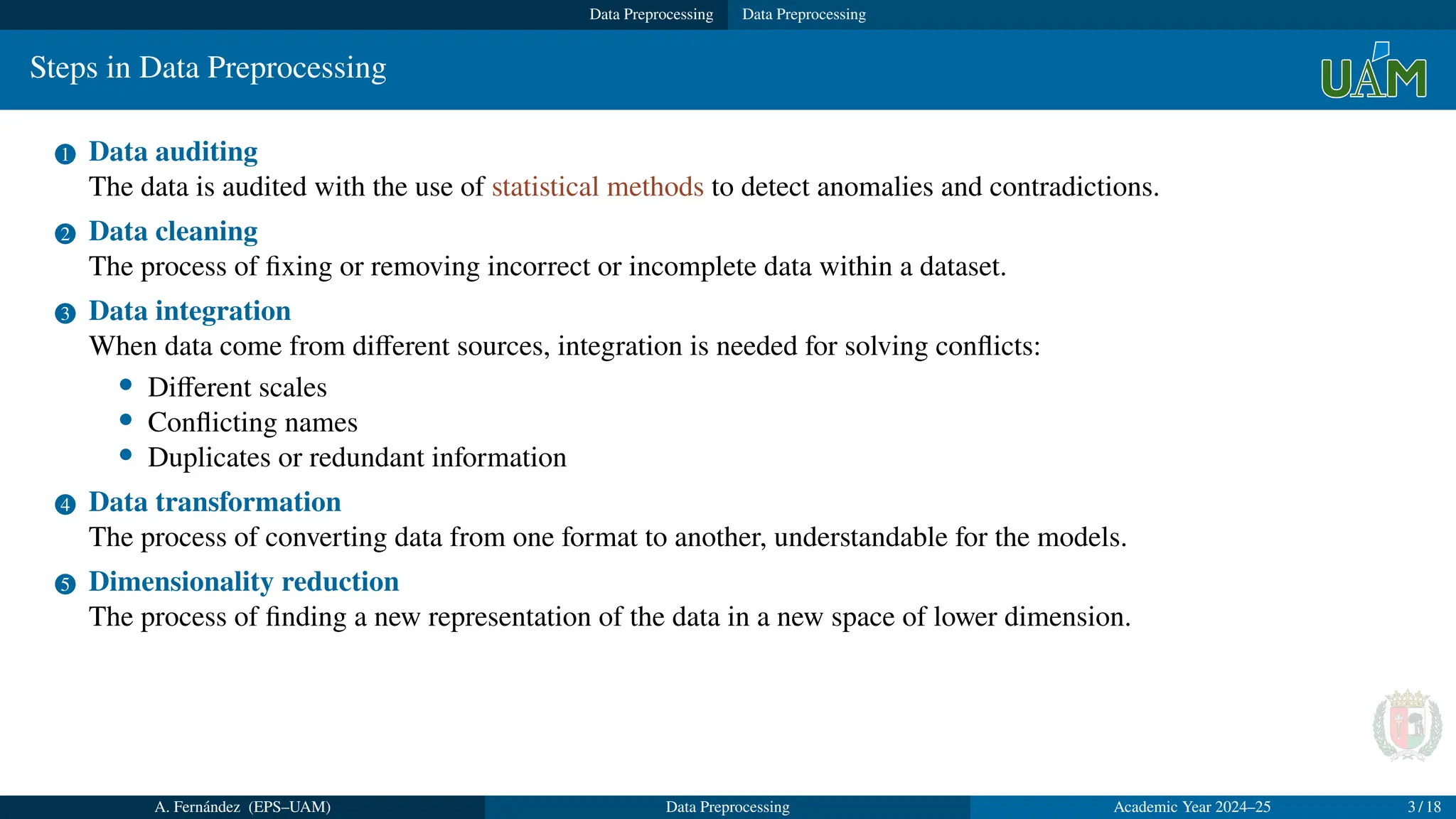
1 Data auditing
The data is audited with the use of statistical methods to detect anomalies and contradictions.
2 Data cleaning
The process of fixing or removing incorrect or incomplete data within a dataset.
3 Data integration
When data come from different sources, integration is needed for solving conflicts:
• Different scales
• Conflicting names
• Duplicates or redundant information
4 Data transformation
The process of converting data from one format to another, understandable for the models.
5 Dimensionality reduction
The process of finding a new representation of the data in a new space of lower dimension.
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 3 / 18
Data cleaning
Data Cleaning:Missing data (I)
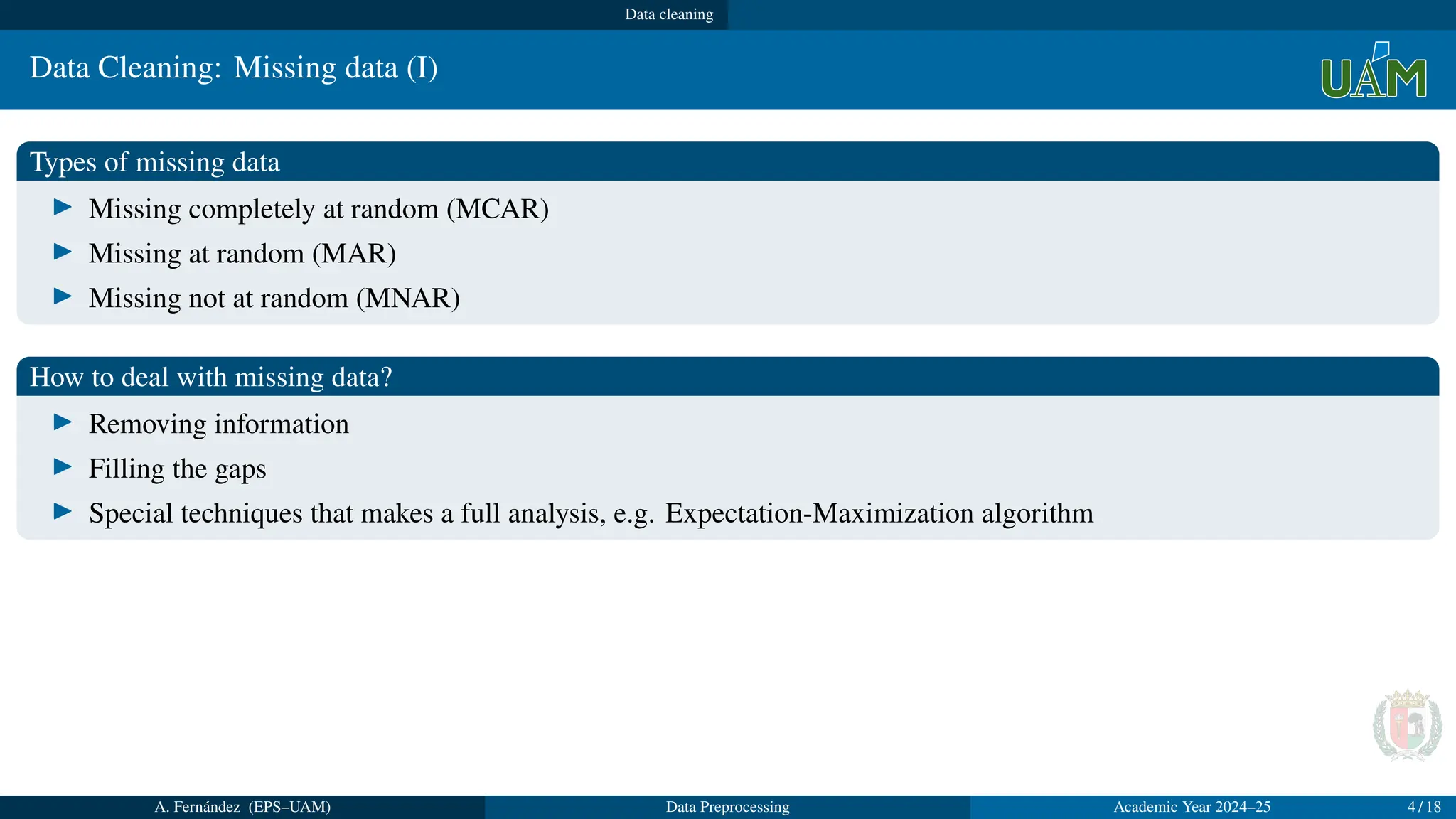
Types of missing data
▶ Missing completely at random (MCAR)
▶ Missing at random (MAR)
▶ Missing not at random (MNAR)
How to deal with missing data?
▶ Removing information
▶ Filling the gaps
▶ Special techniques that makes a full analysis, e.g. Expectation-Maximization algorithm
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 4 / 18
9.
Data cleaning
Missing data(II): removing information
▶ Delete the pattern
• When the target is missing
• Several attributes with missing values for that pattern
• Few data are missing
▶ Delete the complete attribute
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 5 / 18
10.
Data cleaning
Missing data(III): filling the gaps
▶ Use a global constant
▶ Use the attribute mean
▶ Use the attribute mean of the samples at the same class or with similar target
▶ Particular solutions for particular cases: e.g. for time series, interpolation is very typical
Be careful!
It can bias the data...
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 6 / 18
Data cleaning
Data Cleaning:Denoising
Noise: random error or variance in a measured variable
▶ Measurement tools noise
How to deal with noise?
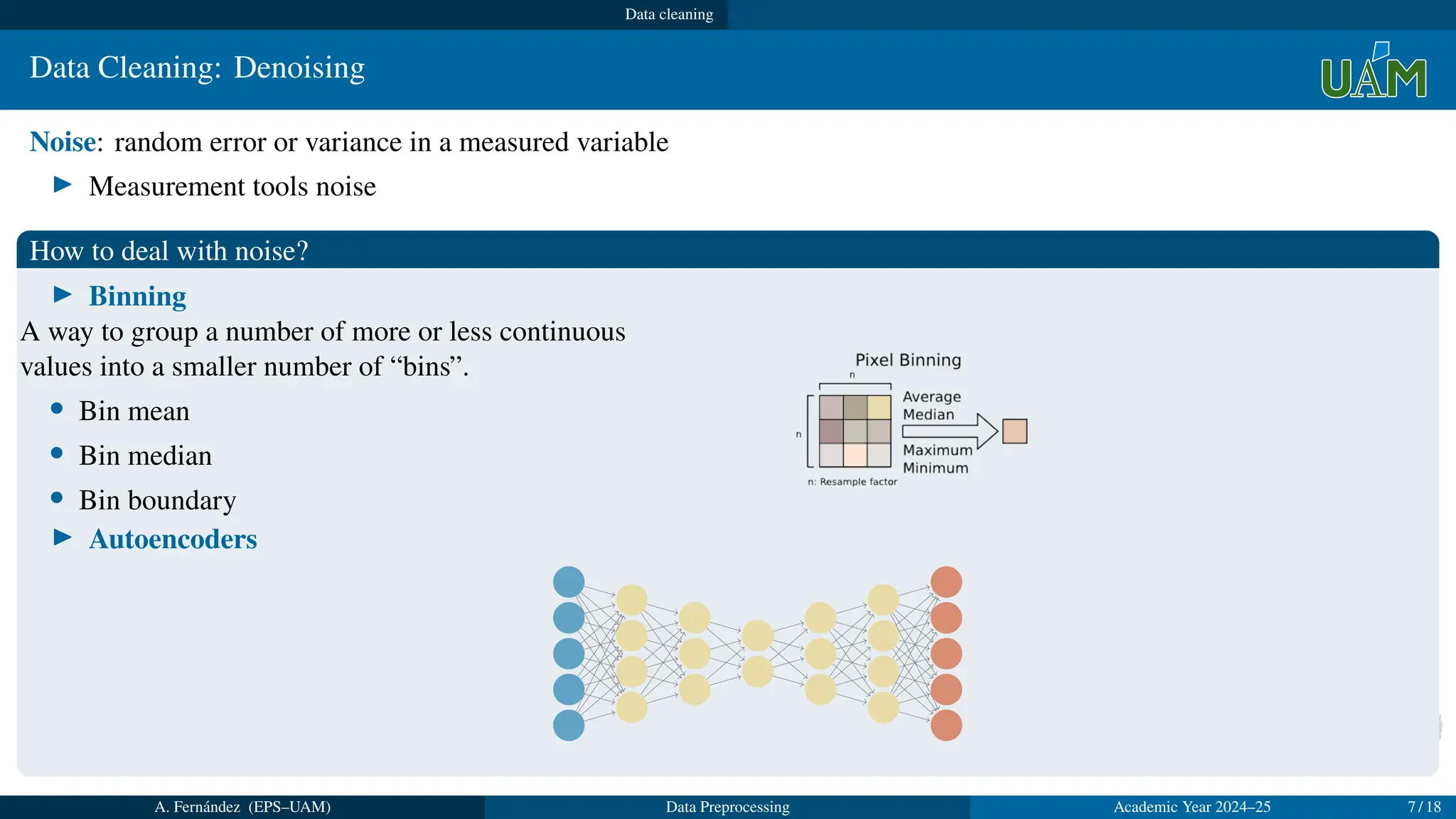
▶ Binning
A way to group a number of more or less continuous
values into a smaller number of “bins”.
• Bin mean
• Bin median
• Bin boundary
▶ Autoencoders
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 7 / 18
13.
Data cleaning
Data Cleaning:Outlier Detection
Outlier: a data point that differs significantly from other observations. It may indicate:
▶ the data may have been coded incorrectly
▶ an experiment may not have been run correctly
Methods
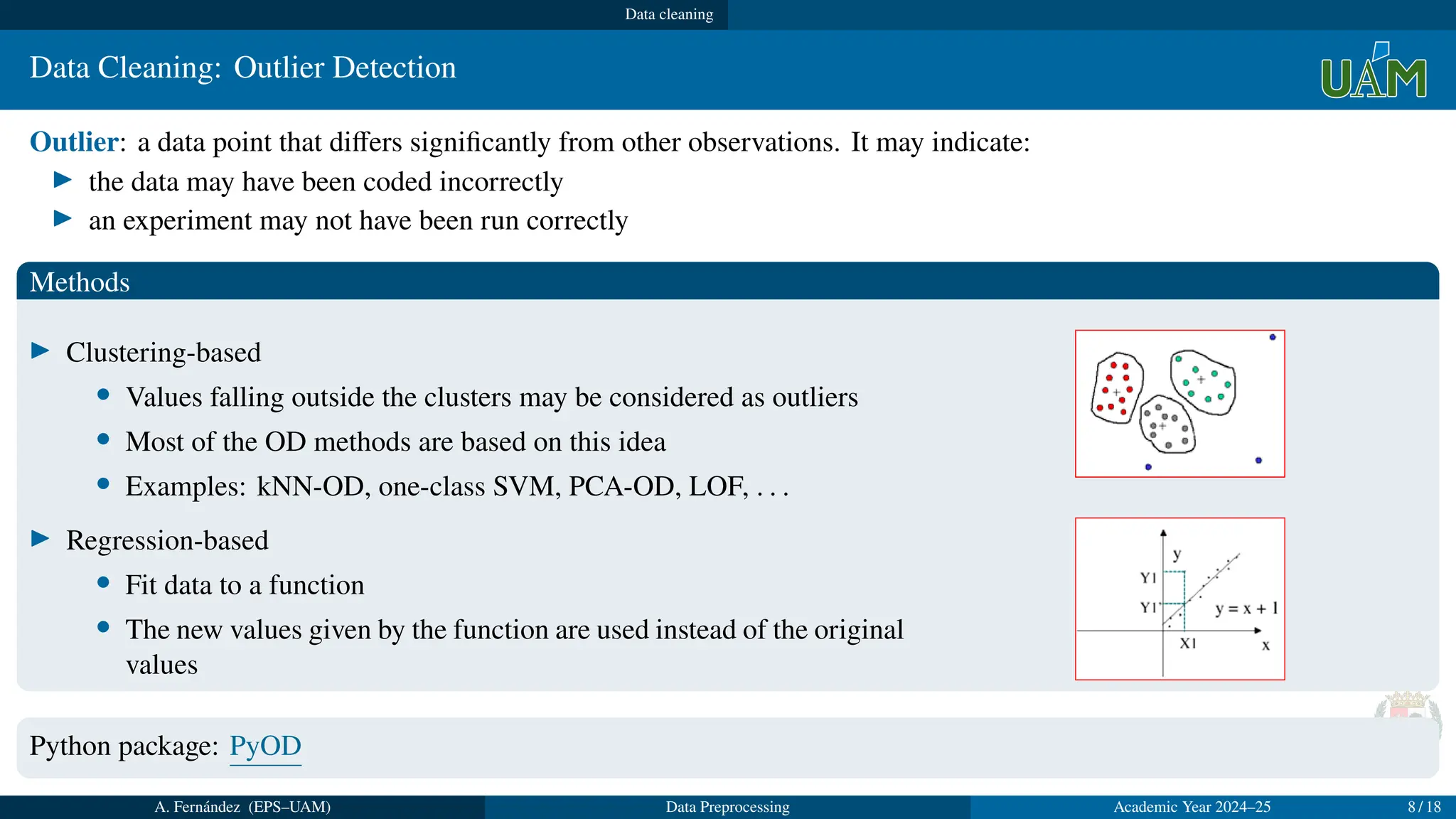
▶ Clustering-based
• Values falling outside the clusters may be considered as outliers
• Most of the OD methods are based on this idea
• Examples: kNN-OD, one-class SVM, PCA-OD, LOF, . . .
▶ Regression-based
• Fit data to a function
• The new values given by the function are used instead of the original
values
Python package: PyOD
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 8 / 18
14.
Data cleaning
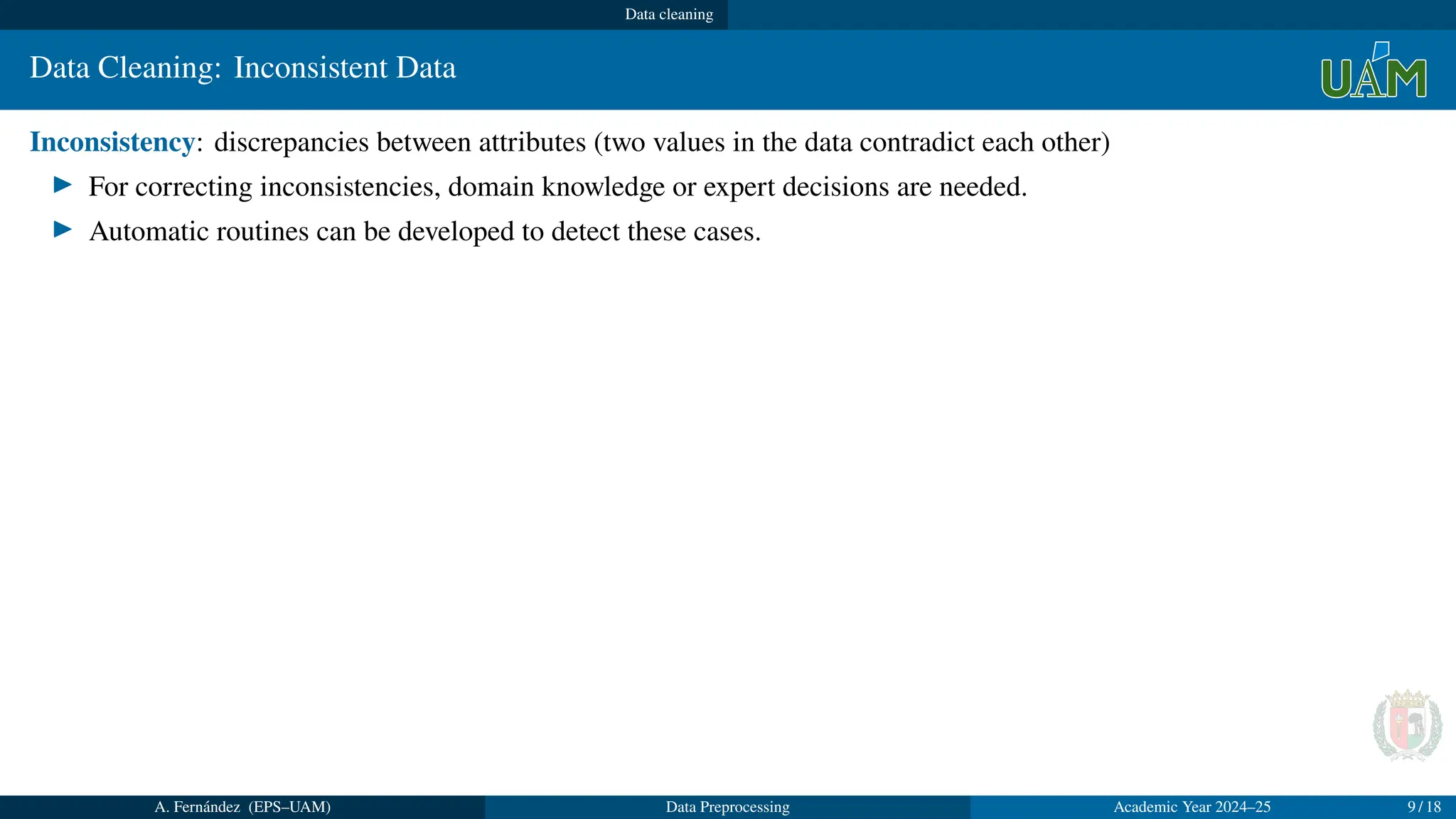
Data Cleaning:Inconsistent Data
Inconsistency: discrepancies between attributes (two values in the data contradict each other)
▶ For correcting inconsistencies, domain knowledge or expert decisions are needed.
▶ Automatic routines can be developed to detect these cases.
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 9 / 18
Data transformation
Data transformation:Categorical variables (I)
Categorical variable: a variable which can take one of a limited set of possible values.
▶ In general, models cannot deal with this type of data
Ordinal encoding
▶ To convert categorical features (words) into integer codes.
One-hot encoding
▶ We convert a categorical variable of n possible values in n dichotomous variables (binary).
▶ In this case, each possible value of the categorical variable is transformed into a new attribute, which takes value 1
for the patterns in that category.
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 10 / 18
17.
Data transformation
Data transformation:Categorical variables (II)
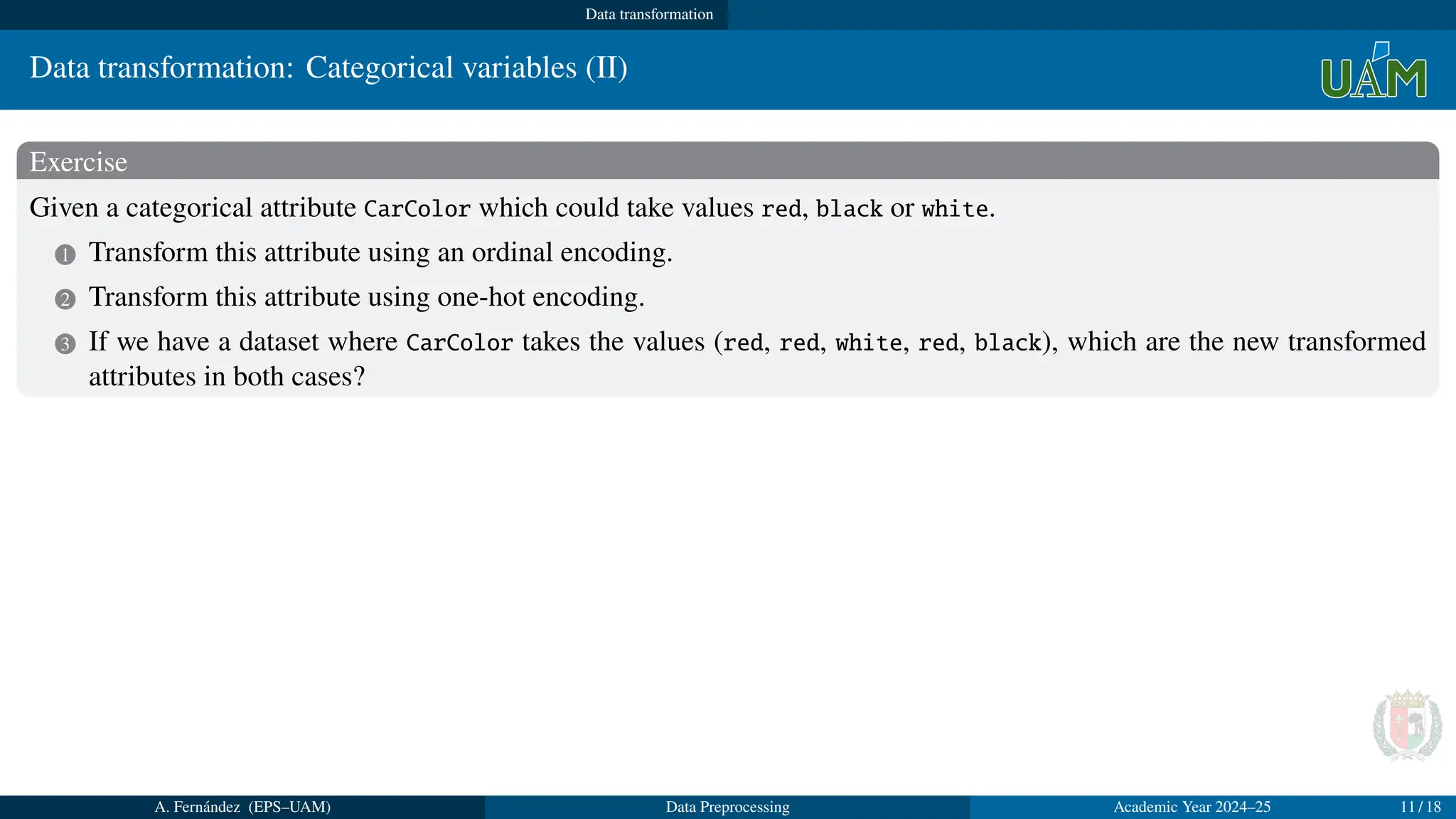
Exercise
Given a categorical attribute CarColor which could take values red, black or white.
1 Transform this attribute using an ordinal encoding.
2 Transform this attribute using one-hot encoding.
3 If we have a dataset where CarColor takes the values (red, red, white, red, black), which are the new transformed
attributes in both cases?
Solution
1 CarColor will now takes values 1, 2, 3 where 1 means red, 2 means black and 3 means white.
2 We substitute the attribute CarColor by three new binary attributes named, for example, red, black and white.
3 The transformed attributes will be:
1 Ordinal encoding: CarColor = (1, 1, 3, 1, 2)
2 One-hot encoding: red = (1, 1, 0, 1, 0); black = (0, 0, 0, 0, 1); white = (0, 0, 1, 0, 0)
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 11 / 18
Data transformation
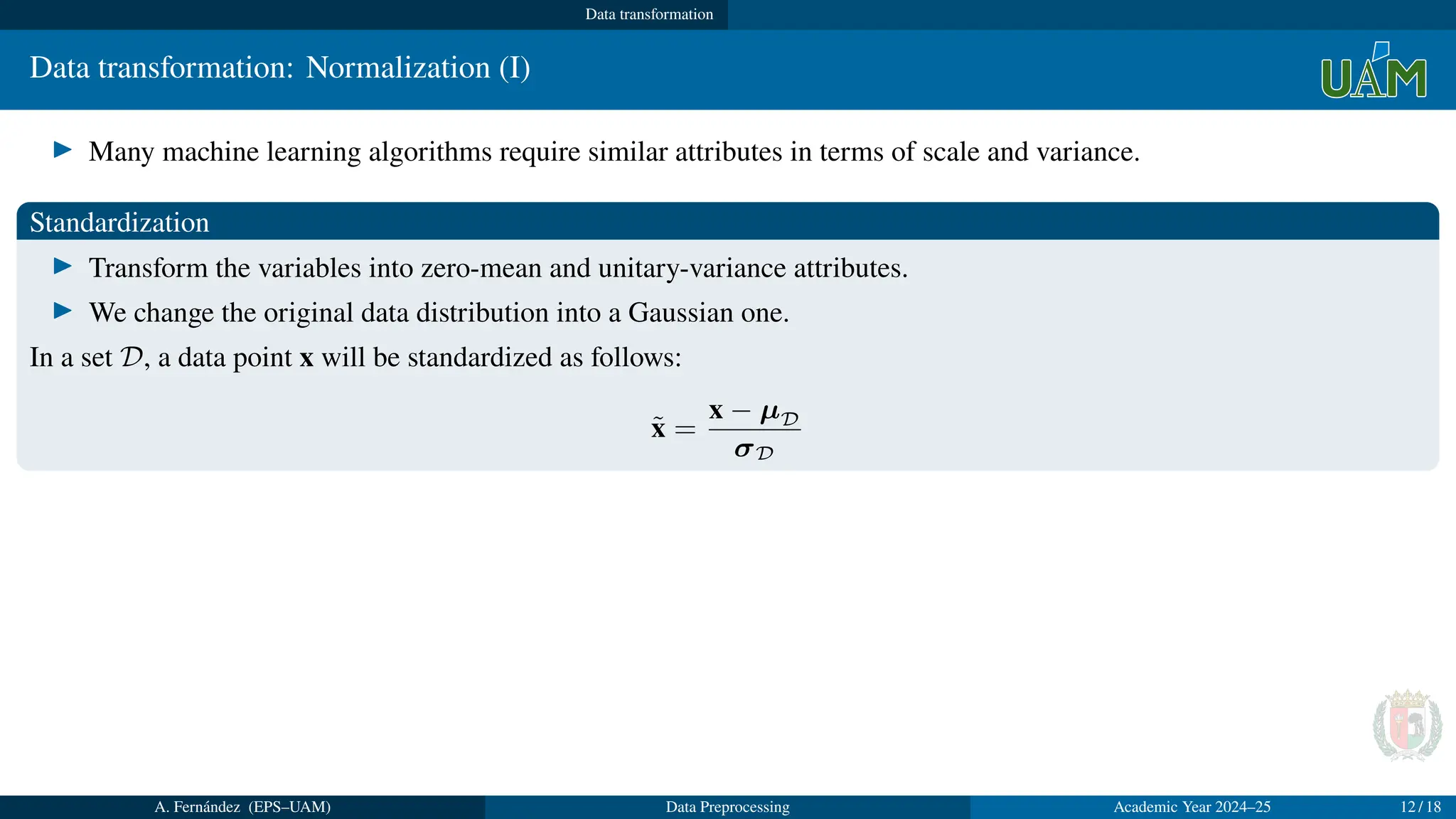
Data transformation:Normalization (I)
▶ Many machine learning algorithms require similar attributes in terms of scale and variance.
Standardization
▶ Transform the variables into zero-mean and unitary-variance attributes.
▶ We change the original data distribution into a Gaussian one.
In a set D, a data point x will be standardized as follows:
x̃ =
x − µD
σD
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 12 / 18
20.
Data transformation
Data transformation:Normalization (II)
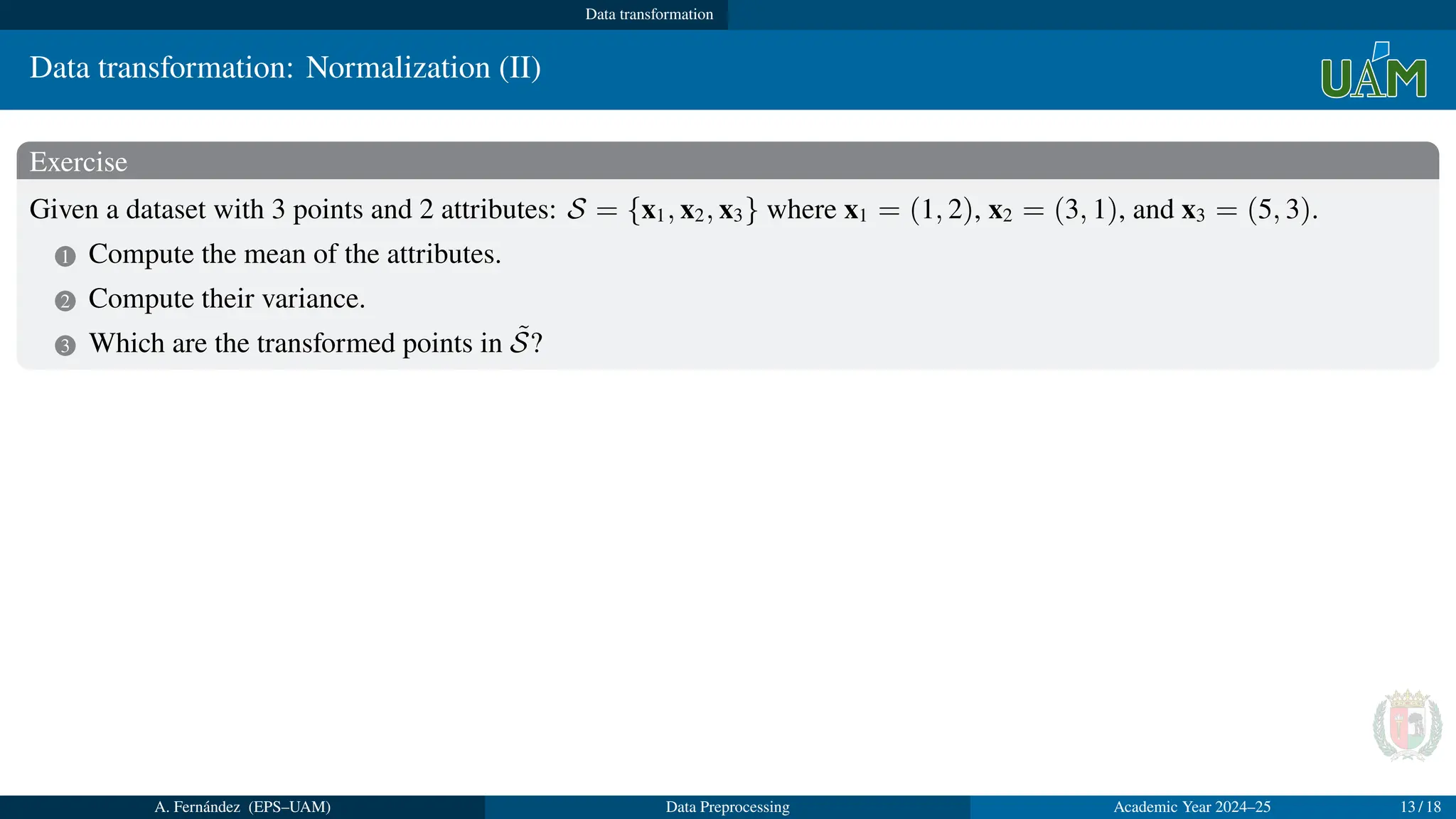
Exercise
Given a dataset with 3 points and 2 attributes: S = {x1, x2, x3} where x1 = (1, 2), x2 = (3, 1), and x3 = (5, 3).
1 Compute the mean of the attributes.
2 Compute their variance.
3 Which are the transformed points in S̃?
Solution
1 Mean: µa1 = 1+3+5
3
= 3; µa2 = 2+1+3
3
= 2.
2 Deviation: σa1 =
q
(1−3)2+(3−3)2+(5−3)2
3
= 1.63; σa2 =
q
(2−2)2+(1−2)2+(3−2)2
3
= 0.82
3 x̃1 = (
1−µa1
σa1
,
2−µa2
σa2
) = (1.23, 0); x̃2 = (
3−µa1
σa1
,
1−µa2
σa2
) = (0, −1.22); x̃3 = (
5−µa1
σa1
,
3−µa2
σa2
) = (1.23, 1.22)
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 13 / 18
21.
Data transformation
Data transformation:Normalization (III)
Scaling
▶ Transform the variables by scaling them to lie between a given minimum and maximum value.
▶ Typical intervals are [0, 1] or [−1, 1].
▶ In this case, the transformed data is more robust to very small standard deviations and preserves zero entries in sparse
data.
In a set D, a data point x will be scaled into a new interval [a, b] as follows:
x̃ = a + (b − a)
x − minD
maxD − minD
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 14 / 18
22.
Data transformation
Data transformation:Normalization (IV)
Exercise
Given the same dataset with 3 points and 2 attributes: S = x1, x2, x3 where x1 = (1, 2), x2 = (3, 1), and x3 = (5, 3).
1 Compute the min and max of the attributes.
2 Which are the transformed points S̃ in this case for scaling into the intervale [0, 1]?
Solution
1 min = (1, 1), max = (5, 3)
2 a + (b − a) = 0 + (1 − 0) = 1,
x̃1 = (1,2)−(1,1)
(5,3)−(1,1)
= (0, 1
2
), x̃2 = (3,1)−(1,1)
(5,3)−(1,1)
= (1
2
, 0), x̃3 = (5,3)−(1,1)
(5,3)−(1,1)
= (1, 1)
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 15 / 18
Data transformation
Data transformation:New features
▶ It can be useful to define synthetic variables.
▶ For example: combining attributes through some interesting expression.
▶ Expert knowledge is needed.
False predictors
A false predictor is a variable that is strongly correlated with the output class, but that is not available in a realistic
prediction scenario.
▶ It is necessary to eliminate them.
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 16 / 18
25.
Data transformation
Data transformation:Class balancing
Imbalanced data: data has imbalanced data distributions among classes, so the number of samples belonging to one
class (majority class) surpasses amply the number of samples of other class (minority class).
How to deal with class imbalance?
▶ Oversampling in the minority class.
• Generate more samples.
▶ Undersampling in the majority class.
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 17 / 18
Summary
Summing up...
▶ Preprocessingis an important step in a machine learning system.
▶ It is the first thing after collecting data and it can be very time consuming.
▶ Several phases:
• Data cleaning: missing values, denoising, outliers detection, inconsistencies
• Data integration: conflicting scales, names, duplicate information
• Data transformation: categorical attributes, normalization, class balancing
• Dimensionality reduction
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 18 / 18








![Data transformation
Data transformation: Normalization (III)
Scaling
▶ Transform the variables by scaling them to lie between a given minimum and maximum value.
▶ Typical intervals are [0, 1] or [−1, 1].
▶ In this case, the transformed data is more robust to very small standard deviations and preserves zero entries in sparse
data.
In a set D, a data point x will be scaled into a new interval [a, b] as follows:
x̃ = a + (b − a)
x − minD
maxD − minD
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 14 / 18](https://image.slidesharecdn.com/maaa-2425-02datapreprocessh-250429084736-9409077b/75/The-model-interacts-with-the-environment-seeking-ways-to-maximize-the-reward-There-is-a-feedback-from-the-environment-21-2048.jpg)
![Data transformation
Data transformation: Normalization (IV)
Exercise
Given the same dataset with 3 points and 2 attributes: S = x1, x2, x3 where x1 = (1, 2), x2 = (3, 1), and x3 = (5, 3).
1 Compute the min and max of the attributes.
2 Which are the transformed points S̃ in this case for scaling into the intervale [0, 1]?
Solution
1 min = (1, 1), max = (5, 3)
2 a + (b − a) = 0 + (1 − 0) = 1,
x̃1 = (1,2)−(1,1)
(5,3)−(1,1)
= (0, 1
2
), x̃2 = (3,1)−(1,1)
(5,3)−(1,1)
= (1
2
, 0), x̃3 = (5,3)−(1,1)
(5,3)−(1,1)
= (1, 1)
A. Fernández (EPS–UAM) Data Preprocessing Academic Year 2024–25 15 / 18](https://image.slidesharecdn.com/maaa-2425-02datapreprocessh-250429084736-9409077b/75/The-model-interacts-with-the-environment-seeking-ways-to-maximize-the-reward-There-is-a-feedback-from-the-environment-22-2048.jpg)






























![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)