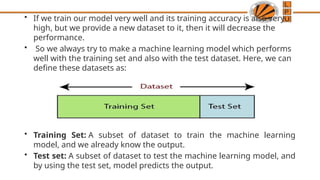
The document outlines the key steps in data preprocessing for machine learning, including data collection, exploration, preparation, model training, evaluation, and improvement. It emphasizes the importance of cleaning and formatting raw data to enhance model accuracy and efficiency. Additionally, it covers techniques for managing data in R, handling missing values, encoding categorical data, splitting datasets into training and test sets, and feature scaling.










![Exploring numeric variables
• summary(usedcars$year)
• summary(usedcars[c("price", "mileage")])](https://image.slidesharecdn.com/datapreprocessing-241027102744-8c092f6a/85/data_preprocessingknnnaiveandothera-pptx-10-320.jpg)