Downloaded 12 times


![Introduction
3
• Data means known facts that can be recorded and that have implicit meaning.[1]
• Database means a collection of related data. [1]
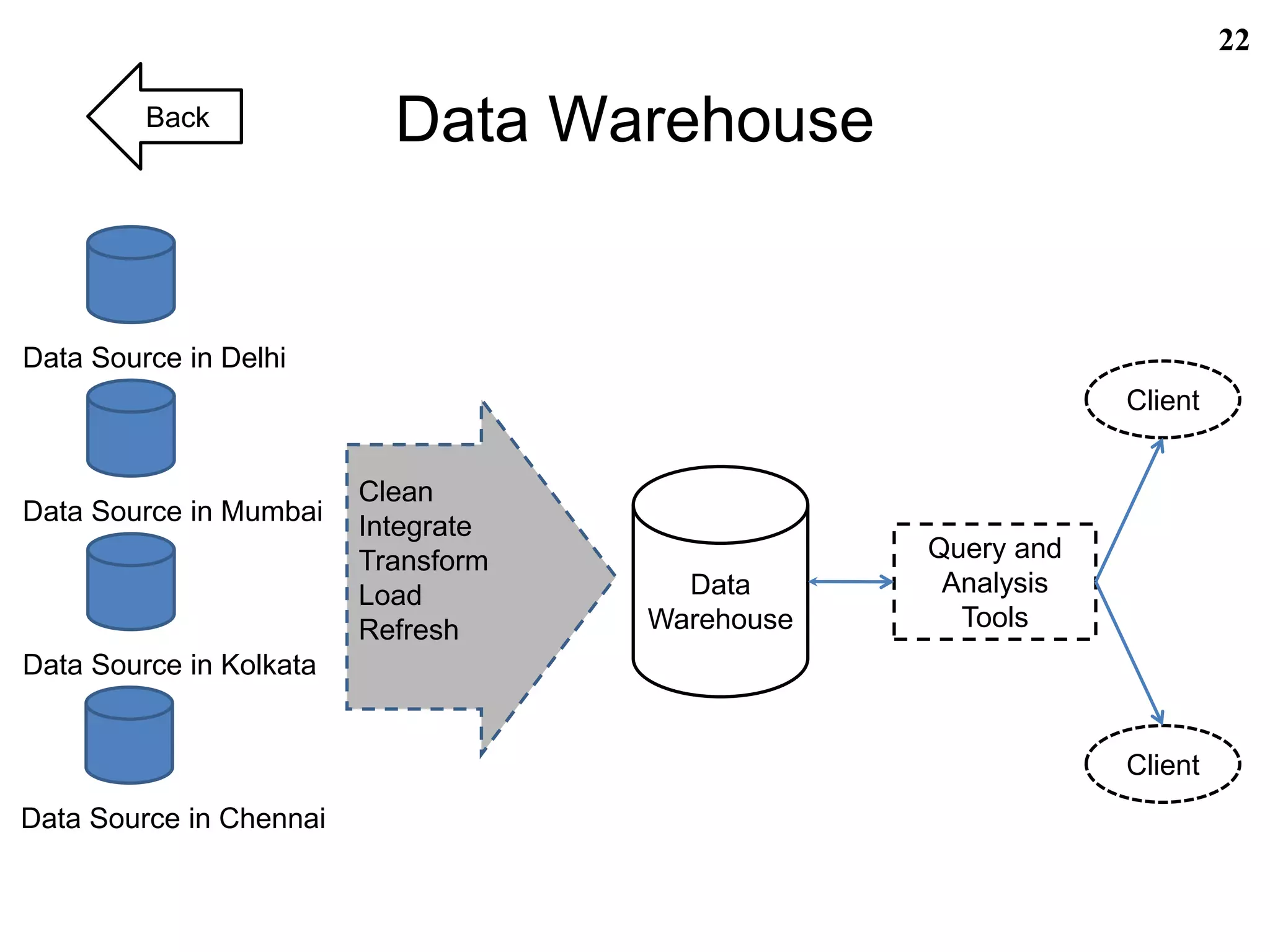
• Data Warehouse is a repository of information collected from multiple sources, stored under a
unified schema, and that usually resides at a single site.[2]
• Data Mining knowledge mining from data .[2]
(extracting knowledge from large amounts of data)
• Text databases(Document databases)
Large collections of documents from various sources:
news articles, research papers, books, digital libraries, e-mail messages, and web pages etc.
(unstructured, semi structured, structured)
• May be highly unstructured (some web pages on www)
• May be semi structured (email messages)
• May be structured ( Library catalogue database)
• Text databases with highly regular structures typically can be implemented
using relational database systems.
• Text Mining is the analysis of data contained in natural language text.
• Regular data mining Vs. Text mining:- in text mining the patterns are extracted from
natural language text rather than from structured databases of facts.[3]
Diagram](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-3-2048.jpg)


![Information Retrieval[2]
6
Information retrieval (IR) is a field that has been developing in parallel with database systems.
Concerned with retrieval of information from a large number of text based documents.
Precision and Recall are two basic measures for accessing the quality of text retrieval.
Precision is the percentage of retrieved documents
that are in fact relevant to the query.
Recall is the percentage of documents that are relevant
to the query and were, in fact, retrieved.
Where {Relevant} is set of documents relevant to a query,
{Retrieved} is the set of documents retrieved.](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-6-2048.jpg)
![Information Retrieval Methods[2]
7
Two Categories
IR
Methods
Document
Selection
Methods
Document
Ranking
Methods
• Document Selection
Problem
• Boolean retrieval model
• Document Ranking
Problem
• Vector space model](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-7-2048.jpg)
![Vector Space Model[2]
8
• Represent a document and a query both as vectors in a high-dimensional space
corresponding to all the keywords and use an appropriate similarity measure to
compute the similarity between the query vector and the document vector.
• The similarity values can then be used for ranking document.
• Let freq(d, t) = term frequency = no. of occurrences of term t in the document d
• TF(d, t) = term frequency matrix, measures the association of a term t with respect
to the given document d.
TF-IDF(d, t) = TF(d, t) X IDF(t)
0 if freq(d, t) = 0
TF(d, t) =
1+log(1+log(freq(d, t ))) OtherwiseTerm Frequency
Inverse Document Frequency
(represents scaling factor or the importance of term t)
Here, d is the document collection,
dt is the set of documents containing term t.](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-8-2048.jpg)
![Vector Space Model[2]
(Example)
9
d/t t1 t2 t3 t4 t5 t6 t7
d1 0 4 10 8 0 5 0
d2 5 19 7 16 0 0 32
d3 15 0 0 4 9 0 17
d4 22 3 12 0 5 15 0
d5 0 7 0 9 2 4 12
A Term Frequency Matrix
For t6 in, d4 we have
TF(d4, t6 ) = 1 + log(1+log(15)) = 1.3374
IDF(t6 ) = log (1+5)/3 = 0.301
TF-IDF(d4, t6) = 1.3377 X 0.301 = 0.403
0 if freq(d, t) = 0
TF(d, t) =
1+log(1+log(freq(d, t ))) Otherwise
d/t t1 t2 t3 t4 t5 t6 t7
d1 0 4 10 8 0 5 0
d2 5 19 7 16 0 0 32
d3 15 0 0 4 9 0 17
d4 22 3 12 0 5 15 0
d5 0 7 0 9 2 4 12
A Term Frequency Matrix](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-9-2048.jpg)
![Text Mining Approaches[2]
10
Text Mining
Approaches
Keyword based
approach Tagging approach
Information
extraction
approach
• set of keywords or
terms in the documents
• may only discover relationship
e.g “database” & “system”,
“terrorist” & “explosion”
• may not bring deep
understanding to the text
Input
• set of tags
• may rely on
manual tagging
(costly & not feasible
for large collection of
documents)
• semantic information
(events, facts etc.)
• more advanced
• may lead to the discovery of
some deep knowledge](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-10-2048.jpg)
![Text Mining Process[4]
11
Preprocessing
Text Mining
Technique is
applied
Analysis of Text
Text document from
different sources
Discovery of
knowledge
The technologies like
Information extraction, categorization, Clustering, Visualization, Summarization
are used in the text mining process](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-11-2048.jpg)
![Techniques Used in Text Mining[4]
1. Information Extraction:
tokenization, identification of named entities, sentence segmentation, and part-of-
speech assignment.
2. Text categorization
procedure of assigning a category to the text among categories predefined by users.
3. Text clustering
procedure of segmenting texts into several clusters, depending on the substantial
relevance.
4. Visualization
improve and simplify the discovery of relevant information.
5. Text summarization
procedure to extract its partial content reflecting its whole contents automatically.
12](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-12-2048.jpg)
![Merits and Demerits of Text mining[4]
Merits:
i) The names of different entities and relationship between them can easily be
found from the corpus of documents set (using the technique such as
information extraction. )
ii) The challenging problem of managing great amount of unstructured
information for extracting pattern is solved by text mining.
Demerits:
i) The information which is initially needed is no where written.
ii) To mine the text for information or knowledge no programs can be made in
order to analyze the unstructured text directly.
13](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-13-2048.jpg)

![Text Mining Applications[5]
15
1. Security applications
(monitoring and analysis of online plain text sources such as Internet news, blogs, etc.
for national security purposes.)
2. Biomedical applications
(studies in protein docking, protein interactions, and protein-disease associations)
3. Software applications
(Within public sector much effort has been concentrated on creating software for
tracking and monitoring terrorist activities.)
4. Online media applications
(The Tribune Company, uses text mining to clarify information and to provide readers
with greater search experiences, which in turn increases site "stickiness" and revenue. )
5. Business and marketing applications
(CRM, to improve predictive analytics models for customer, stock returns prediction)
6. Sentiment analysis
(analysis of movie reviews, used to detect emotions, etc.)
7. Scientific literature mining and academic applications](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-15-2048.jpg)
![Text Mining Computer Programs[5]
16](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-16-2048.jpg)

![Latest Research work on Text Mining[6]
1. Sunil Kumar ; Maninder Singh, “Big data analytics for healthcare industry: impact,
applications, and tools”, DOI: 10.26599/BDMA.2018.9020031
2. Bing Li, Xiaochun Yang, Rui Zhou, Bin Wang, Chengfei Liu, Yanchun Zhang, “An
Efficient Method for High Quality and Cohesive Topical Phrase Mining”, DOI:
0.1109/TKDE.2018.2823758
3. Steven H. H. Ding, Benjamin C. M. Fung, Farkhund Iqbal, William K. Cheung,
“Learning Stylometric Representations for Authorship Analysis”, DOI:
10.1109/TCYB.2017.2766189
4. Mohammed Nasri, Younes Jaafar, Karim Bouzoubaa, “Semantic Analysis of Arabic
Texts Within SAFAR Framework”, DOI: 10.1109/CIST.2018.8596491
5. Jayesh Choudhari, Anirban Dasgupta, Indrajit Bhattacharya, Srikanta Bedathur,
“Discovering Topical Interactions in Text-Based Cascades Using Hidden Markov
Hawkes Processes”, DOI: 10.1109/ICDM.2018.00112
6. Yong Luo, Huaizheng Zhang, Yongjie Wang, Yonggang Wen, Xinwen Zhang,
“ResumeNet: A Learning-Based Framework for Automatic Resume Quality
Assessment”, DOI: 10.1109/ICDM.2018.00046
7. Si-Yu Ding, Xu-Ying Liu, Min-Ling Zhang, “Imbalanced Augmented Class Learning with
Unlabeled Data by Label Confidence Propagation”, DOI: 10.1109/ICDM.2018.00023
18](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-18-2048.jpg)
![References
[1] Ramez Elmasri and Shamkant B. Navathe, “Fundamentals of database systems”, 6th
edition.
[2] Jiawei Han and Micheline Kamber, “Data Mining, Concepts and Techniques”, 2nd
edition.
[3] http://people.ischool.berkeley.edu/~hearst/text-mining.html
[4] Sonali Vijay Gaikwad, Archana Chaugule, Pramod Patil, “Text Mining Methods and
Techniques”, International Journal of Computer Applications (0975 – 8887),
International Journal of Computer Applications (0975 – 8887), Volume 85 – No 17,
January 2014
[5] http://www.wikipedia.org
[6] https://ieeexplore.org
19](https://image.slidesharecdn.com/textmining-190109164502/75/Text-mining-19-2048.jpg)



The document provides an overview of text mining, including: 1. Text mining analyzes unstructured text data through techniques like information extraction, text categorization, clustering, and summarization. 2. It differs from regular data mining as it works with natural language text rather than structured databases. 3. Text mining has various applications including security, biomedicine, software, media, business and more. It faces challenges in representing meaning and context from unstructured text.
Introduction of text mining, its need, and contents overview including aspects like information retrieval.
Explains data, databases, and text databases with definitions, highlighting the necessity for text mining.
Introduction to information retrieval, its precision & recall measures, along with methods like the vector space model.
Details various approaches and processes in text mining including techniques like information extraction, categorization, and clustering.
Outlines the advantages and disadvantages of text mining, addressing representation issues and challenges during text analysis.
Discusses diverse applications of text mining across sectors such as security, biomedical, business, and sentiment analysis.
Overview of text mining software, a demo using Python, and the latest research with cited works on text mining.
References cited in the presentation along with a final Q&A and appreciation slide for the audience.



































































