Download to read offline



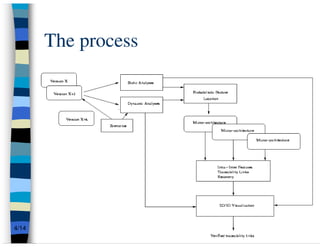




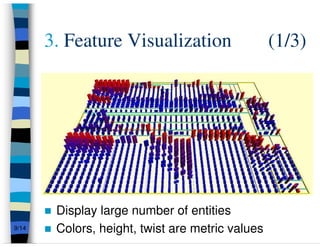
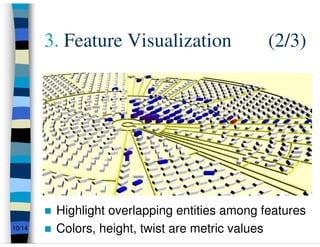
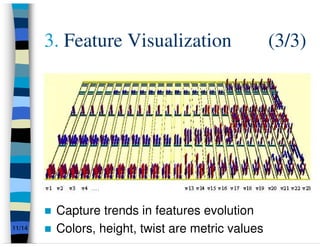

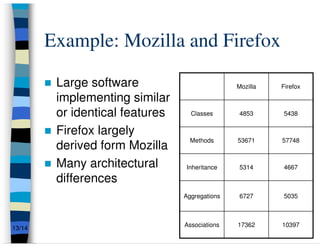


This presentation summarizes research on feature traceability in object-oriented programs. It was presented at TEFSE 2005 in Long Beach, USA on November 8th. The presentation discusses identifying features through static and dynamic code analysis, visualizing large numbers of program entities and features, and analyzing how features and architectures evolve across software releases using Mozilla and Firefox as an example.


















































































