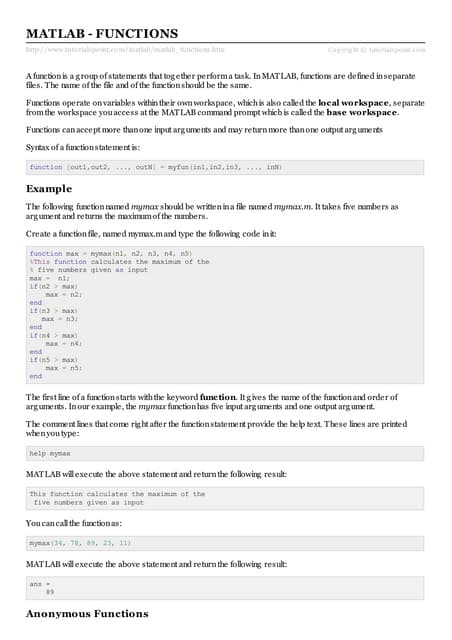
This document discusses collections in Oracle PL/SQL and provides examples of using different collection types such as index-by tables, nested tables, and varrays. It describes collection methods like EXISTS, COUNT, FIRST, LAST, etc. It also covers multiset operations on collections and creating multidimensional collections using record and nested table types. Triggers in Oracle are briefly introduced, including the different timing points of before/after statement and before/after each row triggers.







![o Compound Triggers
o Should you use triggers at all? (Facts, Thoughts and Opinions)
Non-DML (Event) Triggers
Enabling/Disabling Triggers
Related articles.
Mutating Table Exceptions
Trigger Enhancements in Oracle Database 11g Release 1
Cross-Edition Triggers: Edition-Based Redefinition in Oracle Database 11g Release 2
DML Triggers
The Basics
For a full syntax description of the CREATE TRIGGER statement, check out the documentation
shown here. The vast majority of the triggers I'm asked to look at use only the most basic syntax,
described below.
CREATE [OR REPLACE] TRIGGER schema.trigger-name
{BEFORE | AFTER} dml-event ON table-name
[FOR EACH ROW]
[DECLARE ...]
BEGIN
-- Your PL/SQL code goes here.
[EXCEPTION ...]
END;
/
The mandatory BEFORE or AFTER keyword and the optional FOR EACH ROW clause define the timing
point for the trigger, which is explained below. There are optional declaration and exception sections, like
any other PL/SQL block, if required.
The "dml-event" can be one or more of the following.
INSERT
UPDATE
UPDATE FOR column-name[, column-name ...]
DELETE
DML triggers can be defined for a combination of DML events by linking them together with
the OR keyword.
INSERT OR UPDATE OR DELETE
When a trigger is defined for multiple DML events, event-specific code can be defined using
the INSERTING, UPDATING, DELETING flags.
CREATE OR REPLACE TRIGGER my_test_trg
BEFORE INSERT OR UPDATE OR DELETE ON my_table
FOR EACH ROW](https://image.slidesharecdn.com/technical-170425030213/85/Technical-8-320.jpg)








![Should you use triggers at all? (Facts, Thoughts and Opinions)
I'm not a major fan of DML triggers, but I invariably use them on most systems. Here are a random
selection of facts, thoughts and opinions based on my experience. Feel free to disagree.
Adding DML triggers to tables affects the performance of DML statements on those tables. Lots
of sites disable triggers before data loads then run cleanup jobs to "fill in the gaps" once the data
loads are complete. If you care about performance, go easy on triggers.
Doing non-transactional work in triggers (autonomous transactions, package variables,
messaging and job creation) can cause problems when Oracle performs DML restarts. Be aware
that a single DML statement may be restarted by the server, causing any triggers to fire multiple
times for a single DML statement. If non-transactional code is included in triggers, it will not be
rolled back with the DML before the restart, so it will execute again when the DML is restarted.
If you must execute some large, or long-running, code from a trigger, consider decoupling the
process. Get your trigger to create a job or queue a message, so the work can by picked up and
done later.
Spreading functionality throughout several triggers can make it difficult for developers to see what
is really going on when they are coding, since their simple insert statement may actually be
triggering a large cascade of operations without their knowledge.
Triggers inevitably get disabled by accident and their "vital" functionality is lost so you have to
repair the data manually.
If something is complex enough to require one or more triggers, you should probably place that
functionality in a PL/SQL API and call that from your application, rather than issuing a DML
statement and relying on a trigger to do the extra work for you. PL/SQL doesn't have all the
restrictions associated with triggers, so it's a much nicer solution.
I've conveniently avoided mentioning INSTEAD OF triggers up until now. I'm not saying they have
no place and should be totally avoided, but if you find yourself using them a lot, you should
probably either redesign your system, or use PL/SQL APIs rather than triggers. One place I have
used them a lot was in a system with lots of object-relational functionality. Also another feature
whose usage should be questioned.
Non-DML (Event) Triggers
Non-DML triggers, also known as event and system triggers, are can be split into two categories: DDL
events and database events.
The syntax for both are similar, with the full syntax shown here and a summarized version below.
CREATE [OR REPLACE] TRIGGER trigger-name
{ BEFORE | AFTER } event [OR event]...
ON { [schema.] SCHEMA | DATABASE }
[DECLARE ...]
BEGIN
-- Your PL/SQL code goes here.
[EXCEPTION ...]
END;
/
A single trigger can be used for multiple events of the same type (DDL or database). The trigger can
target a single schema or the whole database. Granular information about triggering events can be
retrieved using event attribute functions.
Event Attribute Functions](https://image.slidesharecdn.com/technical-170425030213/85/Technical-17-320.jpg)































![The maximum size for an output record is 1023 bytes, unless you specify a larger value using the
overloaded version of FOPEN.
Syntax
UTL_FILE.PUT_LINE (
file IN FILE_TYPE,
buffer IN VARCHAR2);
Exceptions
INVALID_FILEHANDLE
INVALID_OPERATION
WRITE_ERROR
9. PUTF procedure
This procedure is a formatted PUT procedure. It works like a limited printf(). The format string can
contain any text, but the character sequences '%s' and 'n' have special meaning.
%s Substitute this sequence with the string value of the next argument in the argument list.
n Substitute with the appropriate platform-specific line terminator.
Syntax
UTL_FILE.PUTF (
file IN FILE_TYPE,
format IN VARCHAR2,
[arg1 IN VARCHAR2 DEFAULT NULL,
. . .
arg5 IN VARCHAR2 DEFAULT NULL]);
Exceptions
INVALID_FILEHANDLE
INVALID_OPERATION
WRITE_ERROR
UTL_FILE EXCEPTIONS
Exception Name Description
INVALID_PATH File location or filename was invalid.](https://image.slidesharecdn.com/technical-170425030213/85/Technical-49-320.jpg)

![1.Datafile-contains the information to be loaded.
2.Control file-contains information on the format of the data, the records and fields within the file, the
order in which they are to be loaded, and also the names of the
multiple files that will be used for data.
We can also combine the control file information into the datafile itself.
The two are usually separated to make it easier to reuse the control file.
When executed, SQL*Loader will automatically create a log file and a bad file.
The log file records the status of the load, such as the number of rows processed and the number of rows
committed.
The bad file will contain all the rows that were rejected during the load due to data errors, such as
nonunique values in primary key columns.
Within the control file, we can specify additional commands to govern the load criteria. If these criteria are
not met by a row, the row will be written to a discardfile.
The control,log, bad, and discard files will have the extensions .ctl, .log, . bad, and .dsc, respectively.
25. What is Flexfiled?
A flexfield is a field made up of segments. Each segment has a name you or your end users assign, and
a set of valid values.
There are two types of flexfields:
Key flexfields
Descriptive flexfields.
26. What is the use DFF, KFF and Range Flex Field?
A flexfield is a field made up of sub–fields, or segments. There are two types of flexfields: key flexfields
and descriptive flexfields. A key flexfield appears on your form as a normal text field with an appropriate
prompt. A descriptive flexfield appears on your form as a two–character–wide text field with square
brackets [ ] as its prompt. When opened, both types of flexfield appear as a pop–up window that contains
a separate field and prompt for each segment. Each segment has a name and a set of valid values. The
values may also have value descriptions.
Most organizations use ”codes” made up of meaningful segments (intelligent keys) to identify general
ledger accounts, part numbers, and other business entities. Each segment of the code can represent a
characteristic of the entity. The Oracle Applications store these ”codes” in key flexfields. Key
flexfields are flexible enough to let any organization use the code scheme they want, without
programming.](https://image.slidesharecdn.com/technical-170425030213/85/Technical-51-320.jpg)









![Ans : Temporary tables are used in Interface programs to hold the intermediate data. The data is loaded
into temporary tables first and then, after validating through the PL/SQL programs, the data is loaded into
the interface tables.
39. What are the steps to register concurrent programs in Apps?
Ans : The steps to register concurrent programs in apps are as follows :
Register the program as concurrent executable.
Define the concurrent program for the executable registered.
Add the concurrent program to the request group of the responsibility
40. How to pass parameters to a report? Do you have to register them with AOL ?
Ans: You can define parameters in the define concurrent program form. There is no need to register the
parameters with AOL. But you may have to register the value sets for those parameters.
41. Do you have to register feeder programs of interface to AOL ?
Ans : Yes ! you have to register the feeder programs as concurrent programs to Apps.
42. What are forms customization steps ?
Ans: The steps are as follows :
Copy the template.fmb and Appstand.fmb from AU_TOP/forms/us.Put it in custom directory. The libraries
(FNDSQF, APPCORE, APPDAYPK, GLOBE, CUSTOM, JE, JA, JL, VERT) are automatically attached .
Create or open new Forms. Then customize.
Save this Form in Corresponding Modules.
43. How to use Flexfieldsin reports?
Ans : There are two ways to use Flexfields in report. One way is to use the views (table name + ‘_KFV’ or
’_DFV’) created by apps, and use the concatenated_segments column which holds the concatenated
segments of the key or descriptive flexfields.
Or the other way is to use the FND user exits provided by oracle applications.
44. What is Key and Descriptive Flexfield.
Ans : Key Flexfield: #unique identifier, storing key information
# Used for entering and displaying key information.
For example Oracle General uses a key Flexfield called Accounting
Flexfield to uniquely identifies a general account.
Descriptive Flexfield: # To Capture additional information.
# to provide expansion space on your form
With the help of [] . [] Represents descriptive
Flexfield.](https://image.slidesharecdn.com/technical-170425030213/85/Technical-61-320.jpg)









![(Host, immediate,java stored procedures,java concurrent procedures,
pl/sql stored procedures,multilanguage functions, oracle report,Oracle report stage function)
[1] [2] [3] [4] [5]SpawnedYour concurrent program is a stand-alone program in C or Pro*C.[6] [7]
Host Your concurrent program is written in a script for your operating system.[8] [9]
Immediate Your concurrent program is a subroutine written in C or Pro*C. Immediate
programs are linked in with your concurrent manage and must be included in
the manager's program library.[10] [11]
Oracle Reports Your concurrent program is an Oracle Reports script.[12] [13]
PL/SQL Stored
Procedure
Your concurrent program is a stored procedure written in PL/SQL.[14][15]
Java Stored Procedure Your concurrent program is a Java stored procedure.[16] [17]
Java Concurrent
Program
Your concurrent program is a program written in Java.[18] [19]
Multi Language
Function
A multi-language support function (MLS function) is a function that supports
running concurrent programs in multiple languages. You should not choose a
multi-language function in the Executable: Name field. If you have an MLS
function for your program (in addition to an appropriate concurrent program
executable), you specify it in the MLS Function field.[20] [21]
SQL*Loader Your concurrent program is a SQL*Loader program.[22] [23]
SQL*Plus Your concurrent program is a SQL*Plus or PL/SQL script.[24] [25]
Request Set Stage
Function
PL/SQL Stored Function that can be used to calculate the completion statuses
of request set stages.[26] [27]
5.How will you get Set of Books Id Dynamically in reports.
Using user exits
6.How will you Capture AFF in reports.
Using user exits ( fnd flexsql and fnd flexidval)
7.What is dynamic insertions.
When enabled u can add new segments in existing FF .
8.Whats is Code Comination ID.](https://image.slidesharecdn.com/technical-170425030213/85/Technical-71-320.jpg)
![To idendify a particular FF stored in GL_CODECOMBINATION
9.CUSTOM.PLL. various event in CUStom,pll.
New form instance ,new block instance , new item instance,
new item instance, new record instance, when validate record
10.When u defined Concurrent Program u defined incompatibilities what is Meaning of incompatibilities
??
[28] [29] [30] [31] [32] Identify programs that should not run simultaneously with your concurrent program
because they might interfere with its execution. You can specify your program as being incompatible with
itself.[33]
11.What is hirerachy of multi_org..
BusinessGroup
Legal Entity/Chart of Accounting
Opertaing Unit
Inventory Organization
SubInventory Organization
Loactor
R/R/B
12.What is difference between org_id and organization id.
org_id is operating unit and organization id is operating unit as well as inventoryOrganization
13.What is Profile options.
By which application setting can be modified .
14.Value set. And Validation types.
Value set are Lovs (long list )
None,dependent,indepndent,table,special ,pair,
15.What is Flexfield Qualifier.
To match the segments (natural,balancing,intercompay, cost center)
16.What is your structure of AFF.](https://image.slidesharecdn.com/technical-170425030213/85/Technical-72-320.jpg)

![[34] [35] [36] [37] [38] Check this box to indicate that users can submit a request to run this program from
a Standard Request Submission window.[39]
[40] [41] If you check this box, you must register your program parameters, if any, in theParameters
window accessed from the button at the bottom of this window.
[42]
22.What are REPORT Trigger. What are their Firing Sequences.
23.What is difference between Request Group and Data Group.
Request Group : Collection of concurrent program.
Data Group :
24.What is CUSTOM _TOP.
Ans : Top level directory for customized files.
25.What is meaning of $FLEX$ Dollar.
And : It is used to fetch values from one value set to another.
26.How will you registered SQL LOADER in apps.
Ans : Res - Sysadmin
Concurrent > Program > Executable
(Execution Method = 'SQL *LOADER')
27.What is difference between Formula Column, Placeholder Column and Summary Column?
28.What is difference between bind Variable and Lexical variable?
29.What is Starting point for developing a form in APPS.
Ans : Use temalate.fmb
30.Syntax of SQL Loader.
Sqlldr control = file.ctl
31.Where Control file of SQL Loader Placed.
32.Where the TEMPLATE.FMB resides and all PLL files stored.
33.What is diff between function and Procedures?
Ans :](https://image.slidesharecdn.com/technical-170425030213/85/Technical-74-320.jpg)
![34.Where the Query is written in Oracle Reports.
Ans : Data Model
35.How will you Print Conditionally Printing in Layout.
Using format trigger.
36.How will u get the Report from server
37.Whats is methodology for designing a Interface.
38.Question on Various Interface like GL_INTERFACE, Payable invoice import,
Customer Inteface, AUTOLOCKBOX, AUTOINBVOICE.
Ans : Autolockbox : Box of the organization which is kept in bank
will keep the track of all the cheques and will give the file. With
autolock updates the organization account.
Autoinvoice : Invoice generated after shipping automatically.
39.What are interface table in GL ,AP and AR Interfaces.
40. What are different database Trigger.
41. Whats are various built in FORMS.
42. Whats is set of Books. How wiil u assign set of books to responsibility.
Ans :[43] [44] [45] [46] A set of books determines the functional currency, account structure, and
accounting calendar for each organization or group of organizations.[47]
43. What is FSG reports.
Ans : Financial Statement Generator.
It is a powerful and flexible tool available with GL, you can use to biuld
your custom reports without programming.
44. how will u register custom table in APPS>
Ans : Using package AD_DD.Register_Table(application_shortname, tablename,
table_type, next_extent, pct_increase, pct_used);
45.How will u register custom table's columns in apps?](https://image.slidesharecdn.com/technical-170425030213/85/Technical-75-320.jpg)

































![Data Structures - Lecture 7 [Linked List]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-7linkedlists-150121011916-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)