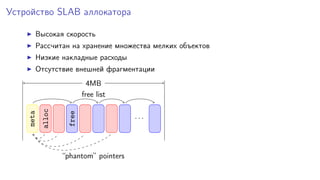
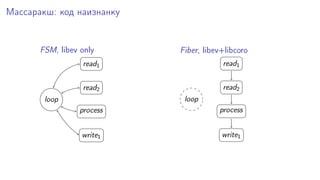
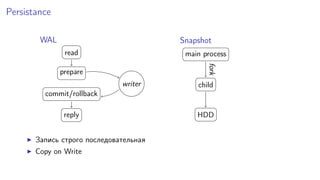
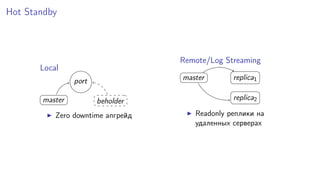
Документ рассматривает эффективное in-memory хранилище Silverbox от Tarantool, оптимизированное для работы с высоконагруженными плоскими таблицами. Он подчеркивает важность скорости доступа и производительности в сравнении с традиционными дисковыми системами, используя примеры атомарных операций и структур хранения. Также упоминается о возможностях эмуляции Memcached и Redis, а также о поддержке репликации и горячих резервов.




















![Обзор архитектуры [файловой] системы Ceph](https://cdn.slidesharecdn.com/ss_thumbnails/ceph-150618110935-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
































































