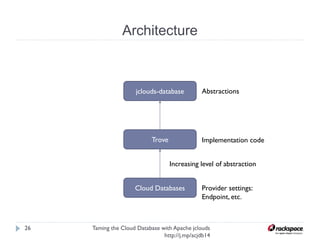
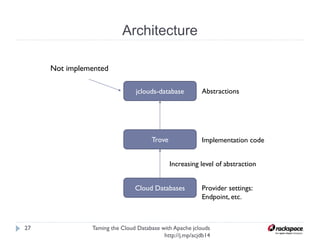
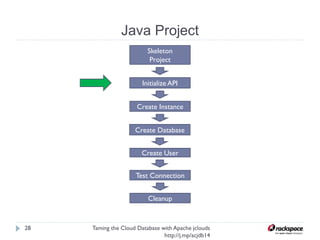
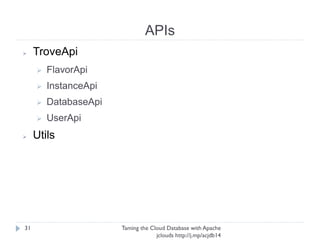
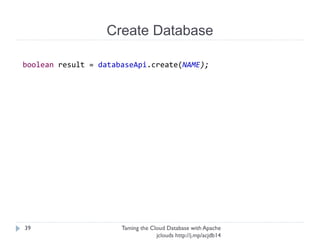
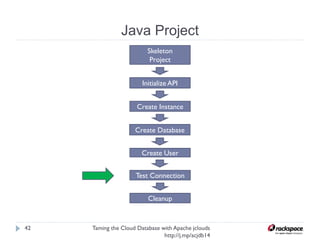
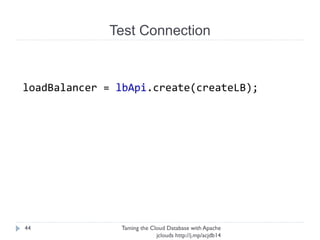
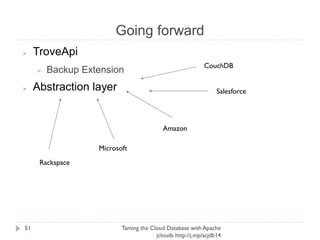
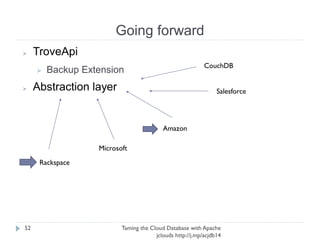
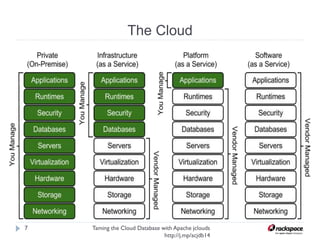
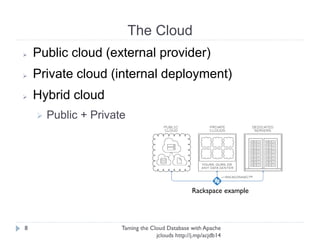
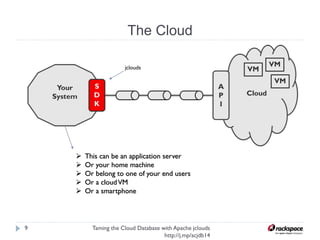
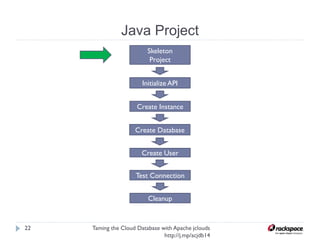
The document discusses using Apache jclouds to interact with cloud databases. It introduces jclouds as a cloud SDK that allows interacting with multiple cloud providers through a common API. It then demonstrates how to use the jclouds database API to create a database instance on Rackspace, create a database, and add a user, providing code examples for each step.















![Requirements
Taming the Cloud Database with Apache jclouds http://j.
mp/acjdb14
21
➢ Maven 3
➢ Java 6+
➢ jclouds
➢ Windows or Linux [etc..] (thanks Java!)](https://image.slidesharecdn.com/apacheconcdb-140324114615-phpapp01/85/Taming-the-Cloud-Database-with-Apache-jclouds-21-320.jpg)


![Logging
Taming the Cloud Database with Apache jclouds http://j.
mp/acjdb14
25
// This module is responsible for enabling logging
Iterable<Module> modules = ImmutableSet.<Module> of(new SLF4JLoggingModule());
ComputeServiceContext context = ContextBuilder.newBuilder(provider)
.credentials(username, apiKey)
.modules(modules) // don't forget to add the modules to your context!
.buildView(ComputeServiceContext.class);
logback.xml
<configuration scan="false">
…
<appender name="WIREFILE" class="ch.qos.logback.core.FileAppender">
<file>target/test-data/jclouds-wire.log</file>
<encoder>
<Pattern>%d %-5p [%c] [%thread] %m%n</Pattern>
</encoder>
</appender>](https://image.slidesharecdn.com/apacheconcdb-140324114615-phpapp01/85/Taming-the-Cloud-Database-with-Apache-jclouds-25-320.jpg)