Download as PDF, PPTX





















![33
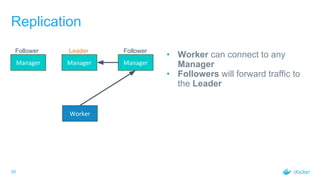
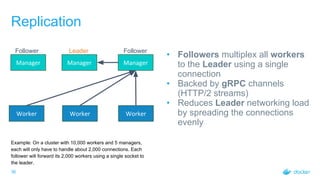
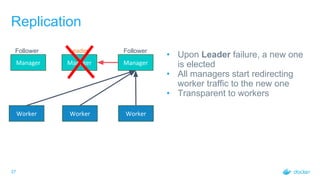
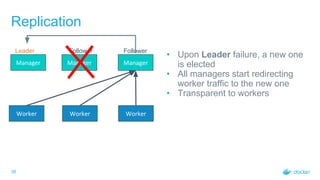
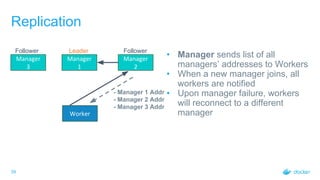
Rate Control: Workloads
• Worker opens a gRPC stream to
receive workloads
• Manager can send data whenever it
wants to
• Manager will send data in batches
• Changes are buffered and sent in
batches of 100 or every 100 ms,
whichever occurs first
• Adds little delay (at most 100ms) but
drastically reduces amount of
communication
Manager
Worker
Give me
work to do
100ms - [Batch of 12 ]
200ms - [Batch of 26 ]
300ms - [Batch of 32 ]
340ms - [Batch of 100]
360ms - [Batch of 100]
460ms - [Batch of 42 ]
560ms - [Batch of 23 ]](https://image.slidesharecdn.com/2017-08laura2fstephenswarmkitintheoryandpractice1-170912193037/85/SwarmKit-in-Theory-and-Practice-33-320.jpg)




















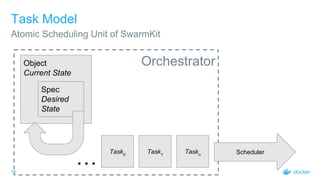
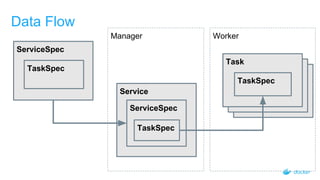
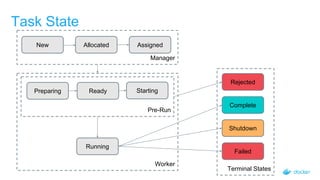
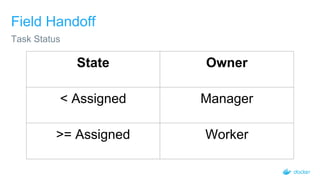
The document outlines the concepts and practices of container orchestration using SwarmKit, focusing on its object model, node topology, and distributed consensus with the Raft algorithm. It explains the orchestration process, including task management, worker communications, and the advantages of employing a pull model for operational simplicity. The presentation also highlights features like observability, data model requirements, and the robustness of SwarmKit in managing cluster states effectively.





































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)













