Some examples ofsupervised learning are
• Predicting the results of a game
• Predicting whether a tumor is malignant or benign
• Predicting the price of domains like real estate, stocks, etc.
• Classifying texts such as classifying a set of emails as spam or non-
spam
6.
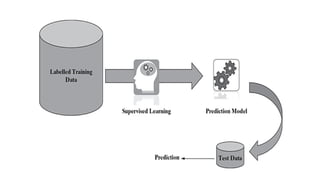
Supervised Learning
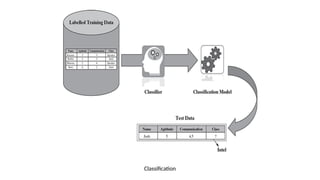
Classification
• Whenwe are trying to predict a
categorical or nominal variable
Regression
• Whereas when we are trying to
predict a real-valued variable
7.
Note:
Supervised machine learningis as good as the data used to train it. If the training
data is of poor quality, the prediction will also be far from being precise.
There are numberof popular machine learning algorithms which help
in solving classification problems. To name a few, k-Nearest Neighbour,
Naïve Bayes, Logistic Regression, Decision tree, and, SVM algorithms
are adopted by many machine learning practitioners.
10.
Some typical classificationproblems include:
• Image classification
• Prediction of disease
• Win–loss prediction of games
• Prediction of natural calamity like earthquake, flood, etc.
• Recognition of handwriting
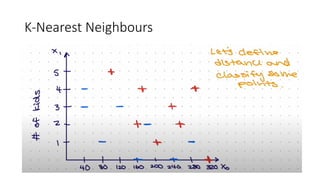
kNN
• kNN –i.e. people having similar background or mindset tend to stay
close to each other.
• In other words, neighbours in a locality have a similar background.
• In the same way, as a part of the kNN algorithm, the unknown and
unlabelled data which comes for a prediction problem is judged on
the basis of the training data set elements which are similar to the
unknown element.
13.
1. What isthe basis of this similarity or when can we say that two data
elements are similar?
Ans 1. Euclidean Distance: Considering a very simple data set having
two features (say f1 and f2 ), Euclidean distance between two data
elements d1 and d2 can be measured by
where f11 = value of feature f1 for data element d1
f12 = value of feature f1 for data element d1
f21= value of feature f2 for data element d2
f22= value of feature f2 for data element d2
14.
2. How manysimilar elements should be considered for deciding the
class label of each test data element?
Ans: The answer lies in the value of ‘k’ which is a user-defined
parameter given as an input to the algorithm.
15.
Homework
1. What isthe best value of k? What happens if its very large or very
small?
2. Find strategies to arrive at a value for k.
3. kNN is called a lazy learner. State the reason behind it.
4. Find strengths and weaknesses of kNN algorithm.