Download to read offline


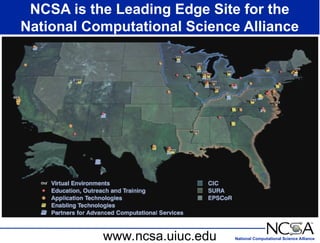

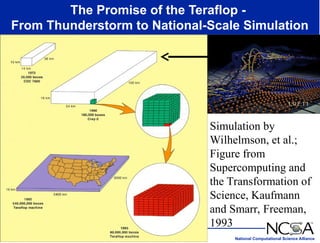
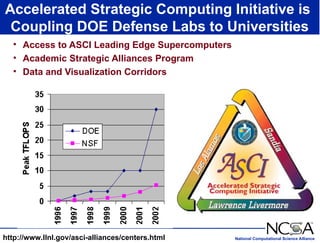
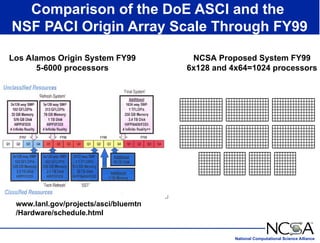
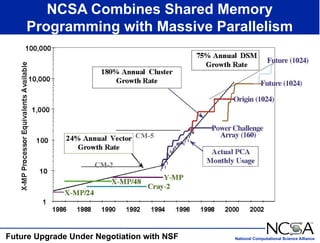
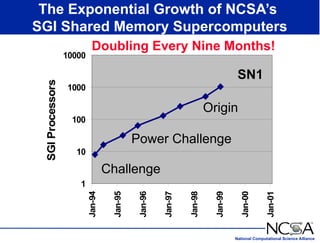
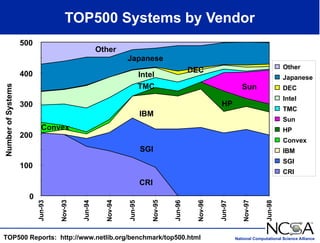
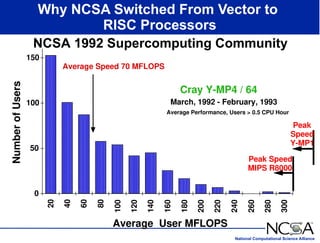
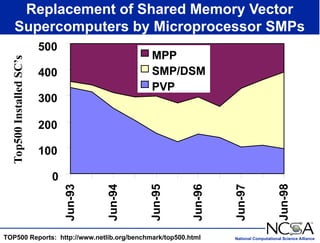
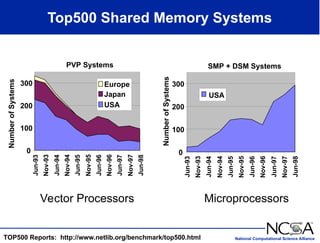
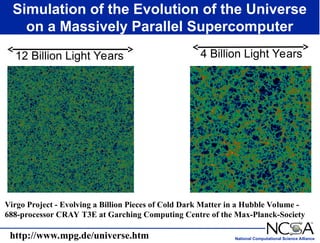


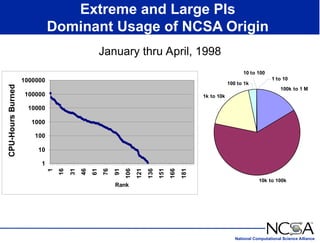
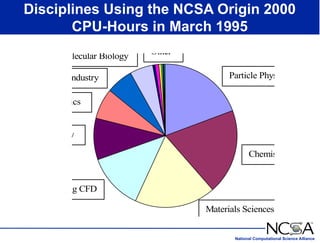
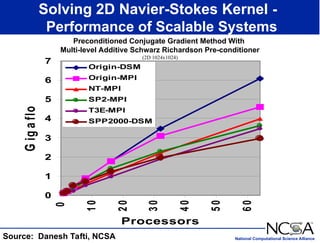
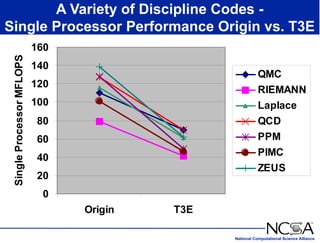



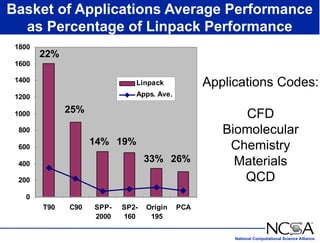
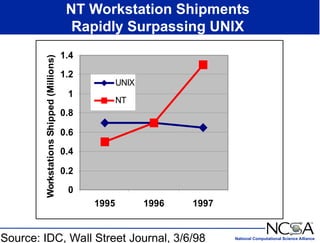
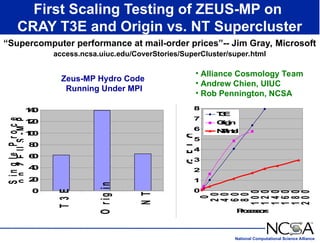
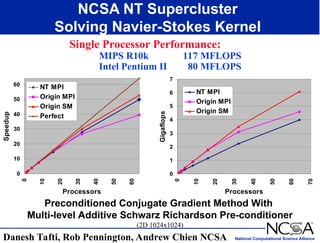
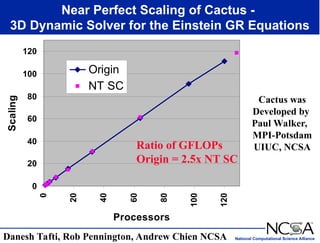



The keynote presentation by Dr. Larry Smarr at the Supercomputer '98 conference discusses the advances and future directions in supercomputing technology, architecture, and applications, highlighting the National Computational Science Alliance's role in driving computing capacity growth for scientific applications. It details the exponential increase in computational power required for simulations in various fields, such as molecular dynamics and cosmology, and the transition from vector to RISC processors in supercomputing. The presentation emphasizes the importance of collaborative efforts between academic and governmental research institutions to achieve breakthroughs in computational science.















































