Downloaded 10 times

















![CALMS (John Willis, Damon Edwards, Jez Humble)
Culture
Automation
Lean (management or continuous improvement)
Metrics
Sharing
[The first SRE book] explicitly
references Culture, Automation,
Metrics, and Sharing alongside
anecdotes about Google’s journey to
continuously improve.
Andrew Clay Shafer: The Site Reliability Workbook.](https://image.slidesharecdn.com/codomotionberlin2018-181213081326/75/Bjorn-Rabenstein-About-SRE-and-how-not-to-apply-it-Codemotion-Berlin-2018-21-2048.jpg)











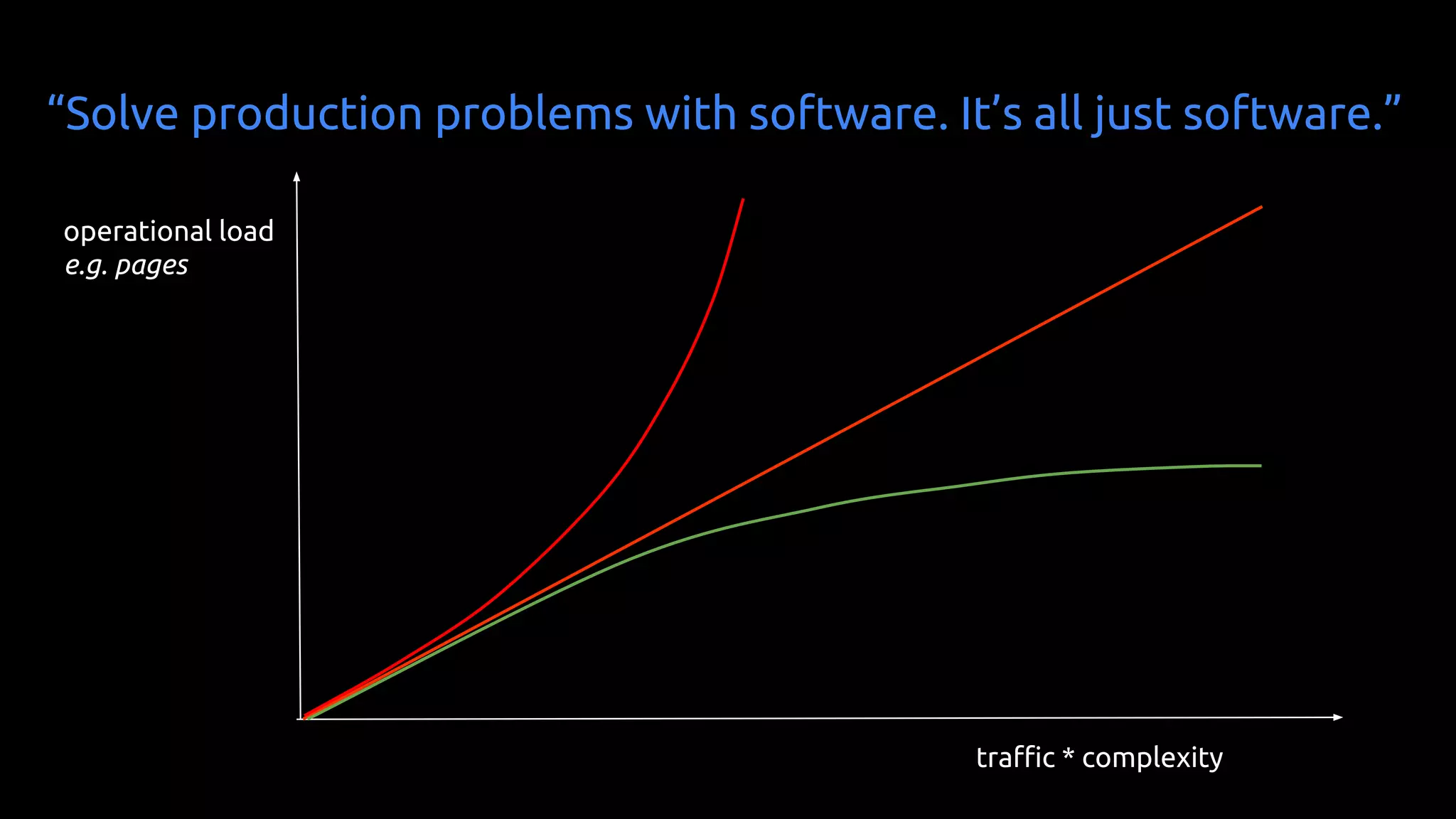
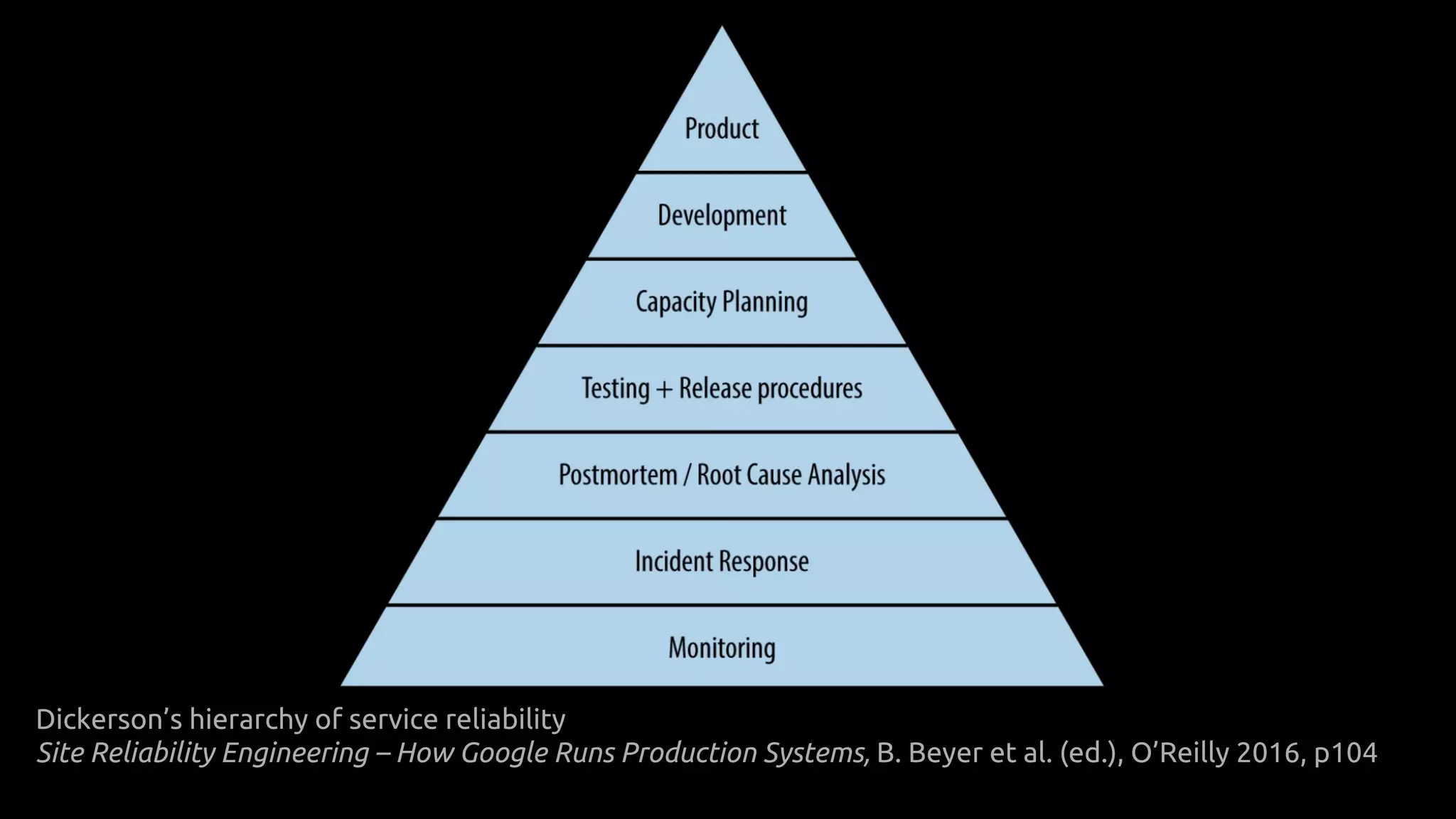
The document discusses the principles and practices of Site Reliability Engineering (SRE) as it relates to DevOps, emphasizing the importance of culture, automation, and metrics. It outlines key aspects of SRE, including operational loads, alerting, and the relationship between engineering teams and operations. The author reflects on the experience at SoundCloud while drawing parallels to Google's implementation of SRE and cautions against treating SRE guidelines as absolute rules.



























![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)













































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












