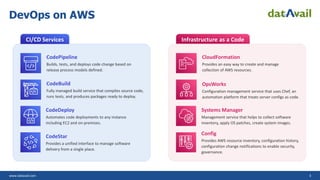
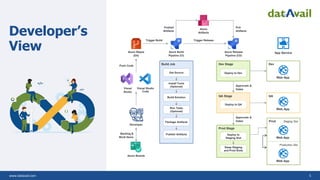
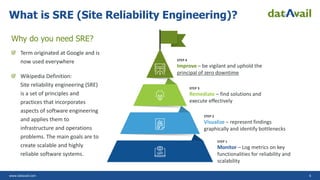
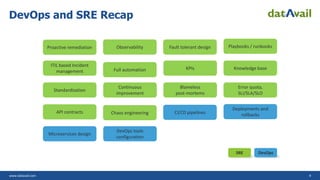
The document explains DevOps as a methodology that integrates software development and operations for enhanced collaboration and efficiency. It also discusses the application of DevOps on AWS and Azure, highlighting various tools and services for continuous integration, delivery, and deployment. Additionally, it introduces Site Reliability Engineering (SRE) and its role in creating reliable software systems while emphasizing the benefits and maturity model of SRE.










![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)










































