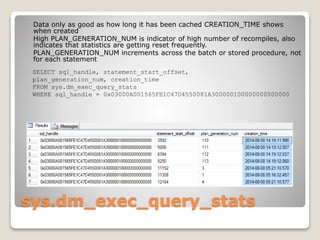
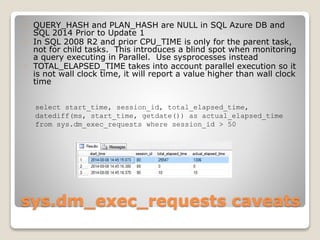
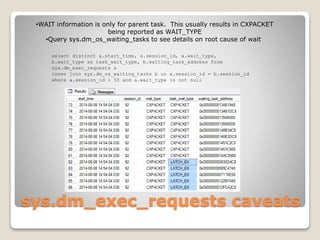
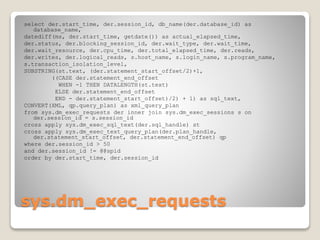
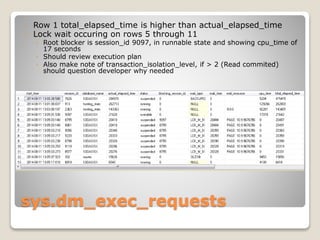
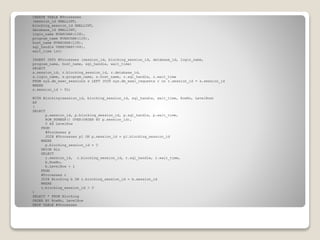
The document presents an overview of performance monitoring and tuning using Dynamic Management Views (DMVs) introduced in SQL Server 2005 and matured in SQL Server 2008. It details proactive and reactive tuning strategies, emphasizing the importance of understanding query statistics, execution plans, and specific DMVs like sys.dm_exec_query_stats to identify performance issues. Furthermore, it addresses various challenges in monitoring queries, such as handling dynamic SQL and wait types, while providing examples of SQL queries to analyze database performance effectively.