Download to read offline


















![Chi fa cosa?
• SQL Azure periodico mantenuto almeno 7 giorni
“as a safe guard against catastrophic software and system failures” !!!!
Backup Full settimanale, Differenziale giornaliero, Transaction Log ogni 5’
Storico 7gg (B), 14gg (S), 35gg (P)
Point in Time Restore, Restoring a Deleted Database, Geo-Restore
• Errori Utente (Business Continuity)
Usare SQL Data Sync (backup offline/remoto)
Copia di Database (CREATE DATABASE [destination] AS COPY OF [source])
Import/Export Service (Azure BLOB storage necessario, auto in preview)
Gruppo/Agente di sincronizzazione Azure (SQLDataSyncAgent solo x86 )
• Pianificare prima di iniziare ](https://image.slidesharecdn.com/implementareemantenereunprogettoazuresqldatabasev-141118182414-conversion-gate01/75/2014-11-14-Implementare-e-mantenere-un-progetto-Azure-SQL-Database-33-2048.jpg)






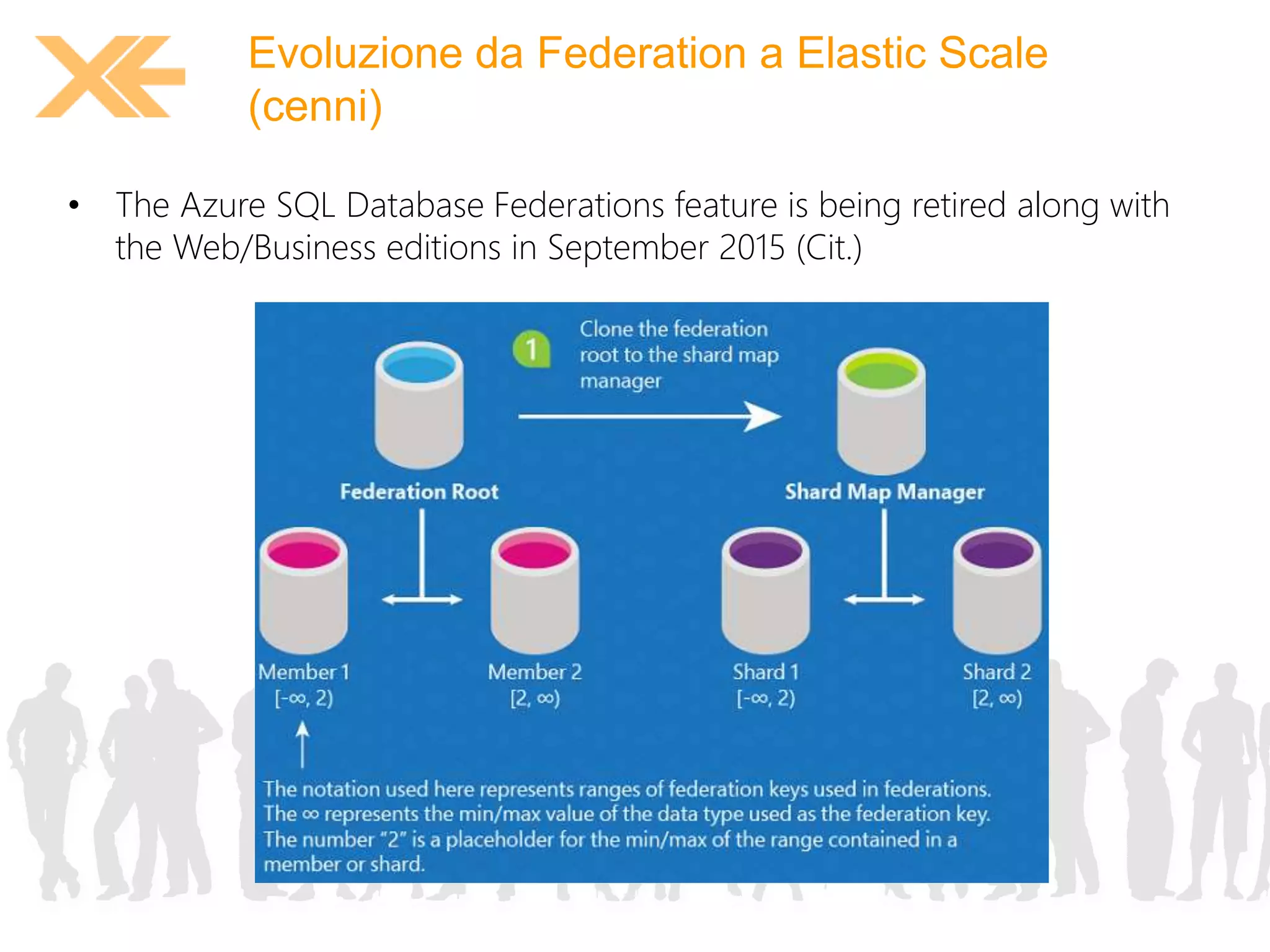
Il documento discute l'implementazione e la gestione di Azure SQL Database, coprendo argomenti quali l'architettura dell'infrastruttura, le strategie di backup e restore, e le varie opzioni di scalabilità. Viene evidenziato il passaggio da federazioni a elastic scale e le considerazioni per una migrazione efficace, oltre a dettagli sulle limitazioni e le funzionalità da tenere a mente. Infine, sono forniti dettagli sui service level agreement e strumenti per migrazione e gestione dei dati.






















































