Download as PDF, PPTX












![T-SQL Development
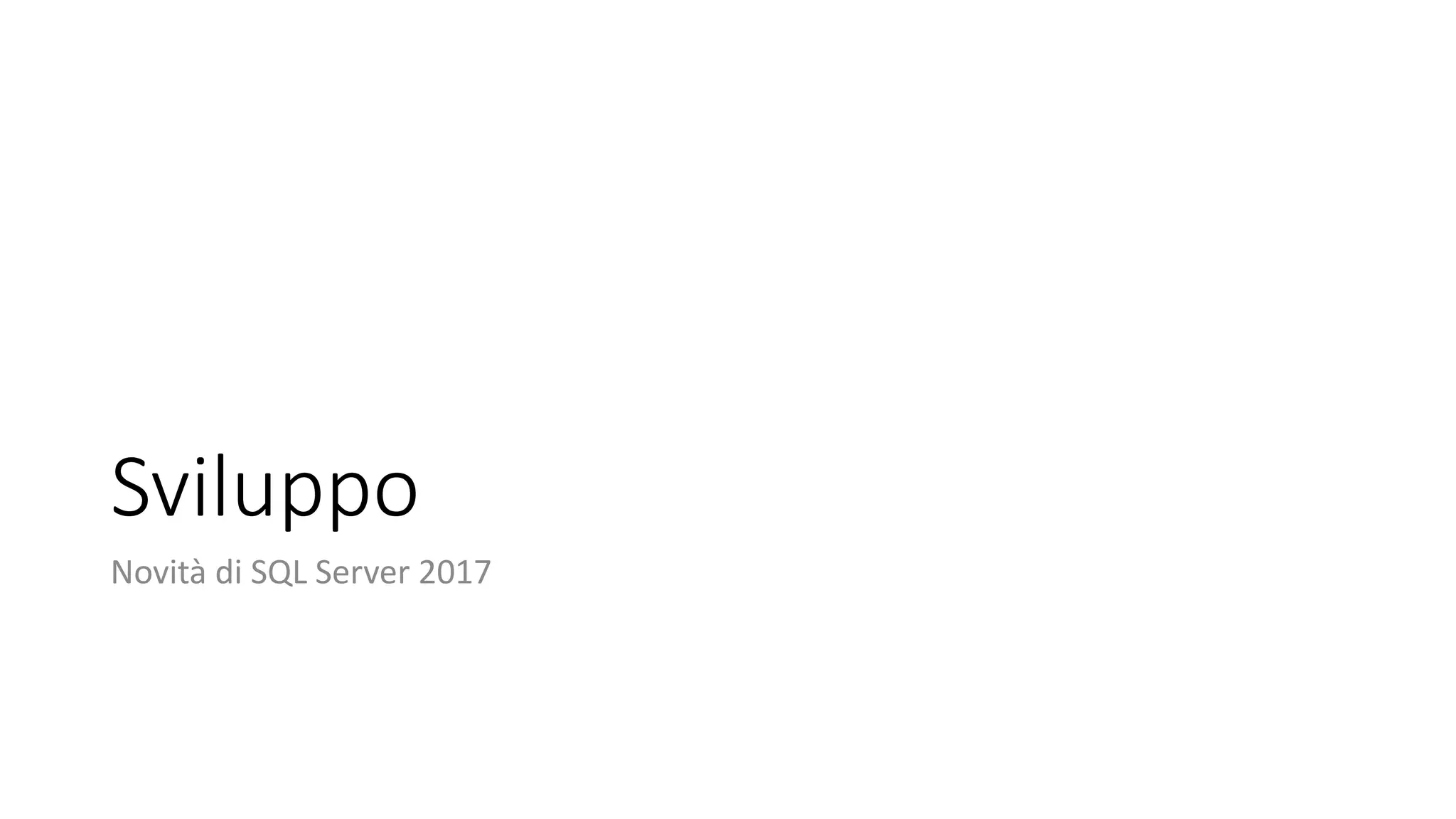
• CONCAT_WS
• Concatena stringhe (colonne/valori) usando primo valore come separatore
• TRANSLATE
• Sostituisce insieme di caratteri in stringa con altro insieme di caratteri
• e.g. SELECT TRANSLATE('2*[3+4]/{7-2}', '[]{}', '()()’);
• TRIM
• Finalmente!!!! ☺
• Taglia spazi in testa/coda oppure un set di caratteri
• STRING_AGG
• Concatena stringhe (valori per riga) usando un separatore](https://image.slidesharecdn.com/novitadisqlserver2017-it-full-181009222654/75/Novita-di-SQL-Server-2017-15-2048.jpg)
























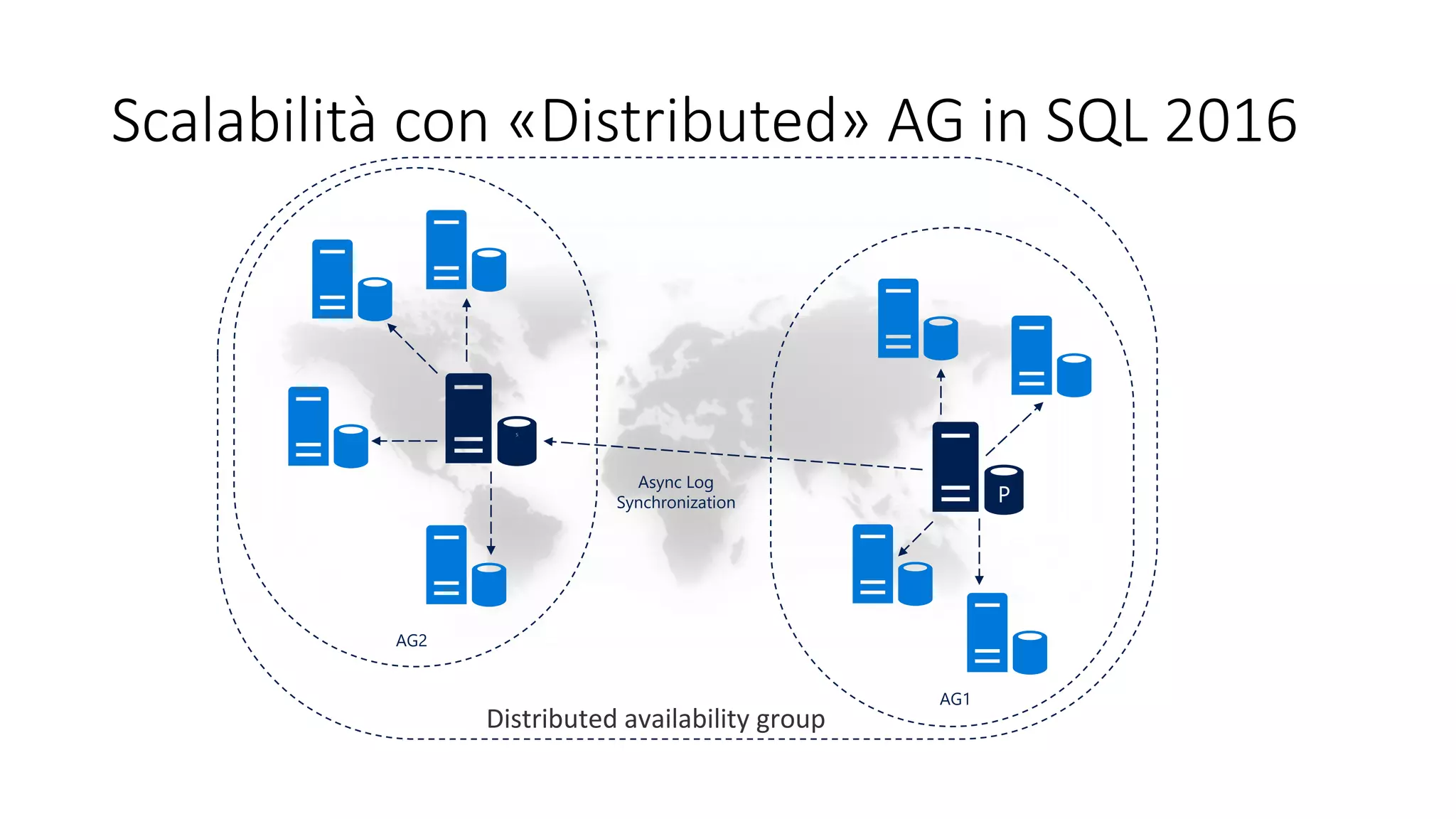


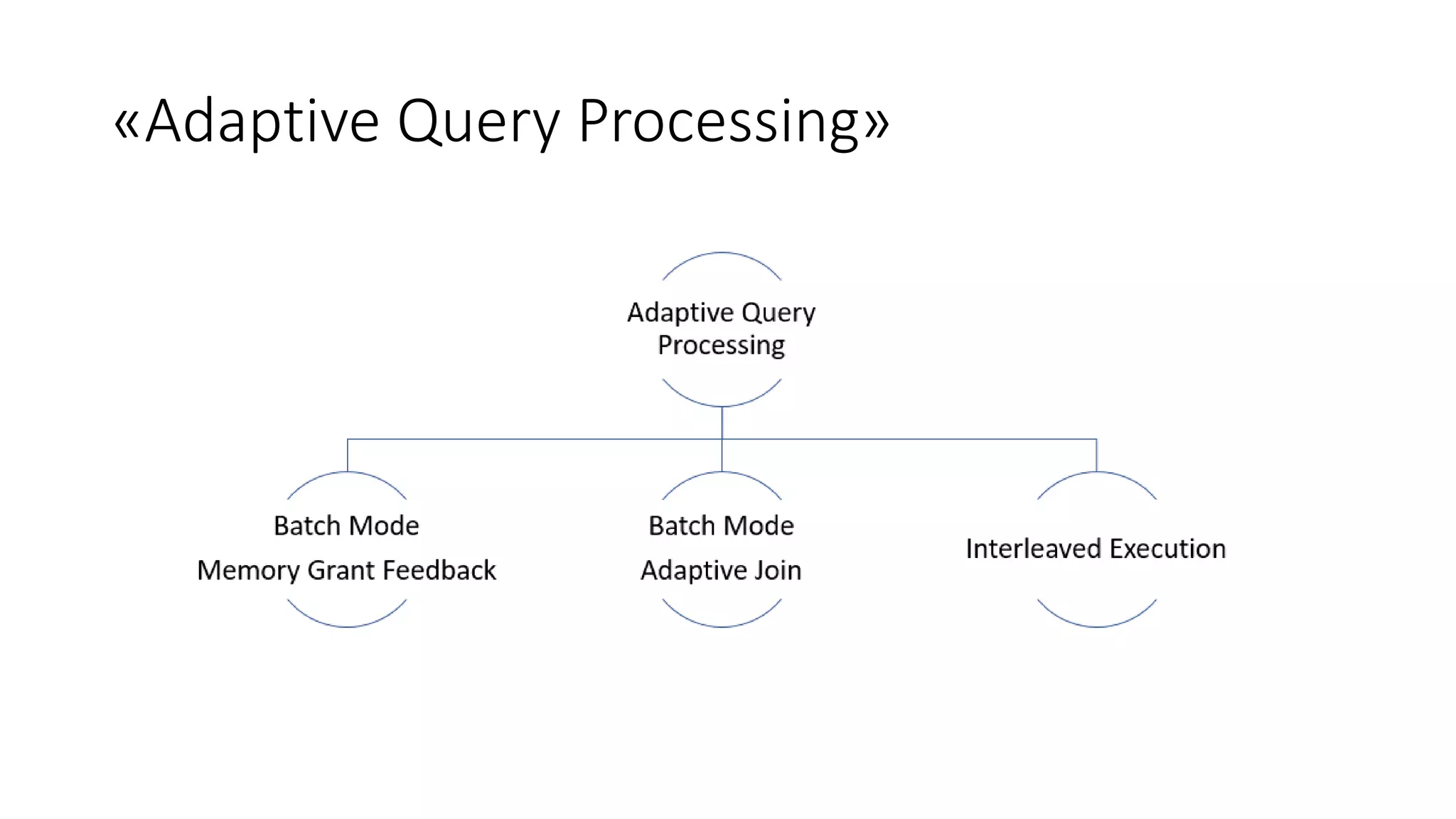


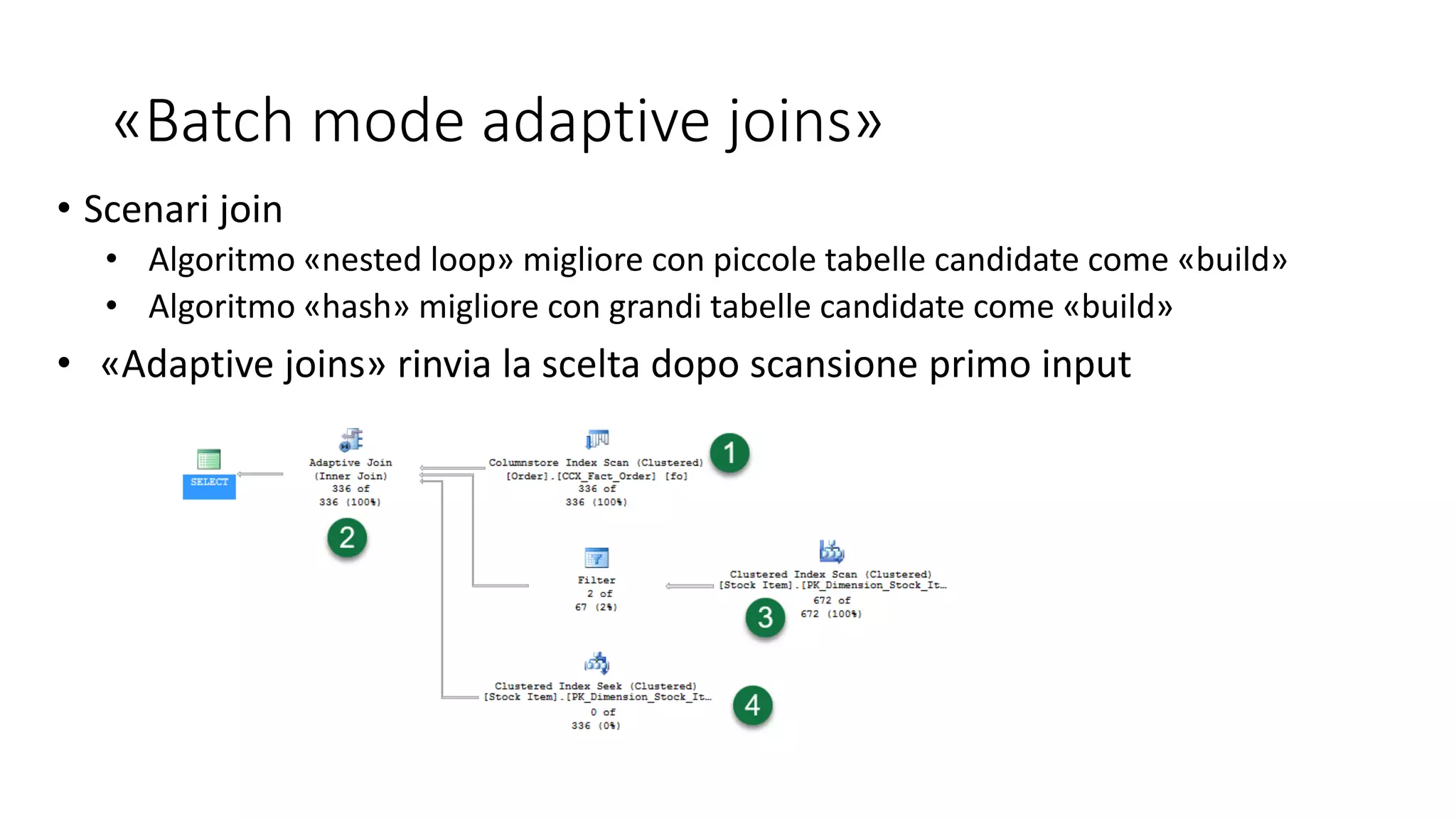



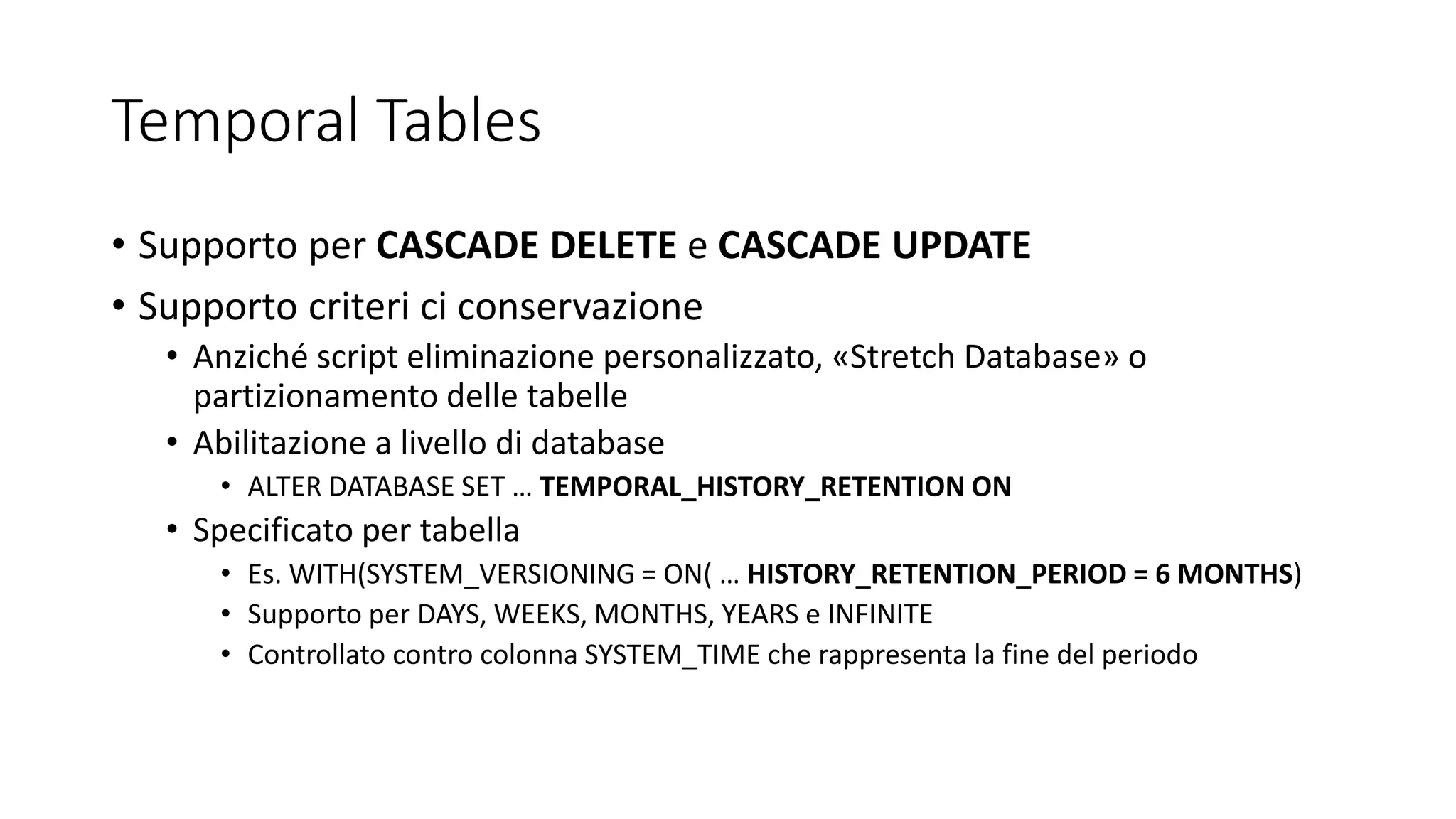
SQL Server 2017 introduce novità significative tra cui il supporto per Linux, una configurazione migliorata del tempdb e nuove funzionalità di query e sviluppo come il processamento dei grafi e l'elaborazione delle query adattiva. Inoltre, offre miglioramenti nei metadati di sistema, nella sicurezza CLR e nella gestione automatizzata degli indici. Le opzioni di high availability sono state ampliate e ottimizzate per supportare scenari di clustering e transazioni cross-database.































![noSQL La nuova frontiera dei Database [DB05-S]](https://cdn.slidesharecdn.com/ss_thumbnails/db05-ssiracusa05-03-2016-160304154822-thumbnail.jpg?width=640&height=640&fit=bounds)








![[ITA] Sql Saturday 355 in Parma - New SQL Server databases under source control](https://cdn.slidesharecdn.com/ss_thumbnails/itasqlsaturday355-sqlserverdatabasesundersourcecontrol-141124054202-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Ita] Sql Saturday 462 Parma - Sql Server 2016 JSON support](https://cdn.slidesharecdn.com/ss_thumbnails/itasqlsaturday462-sqlserver2016jsonsupport-151130112829-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


















