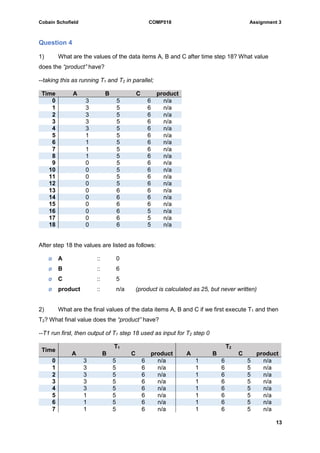
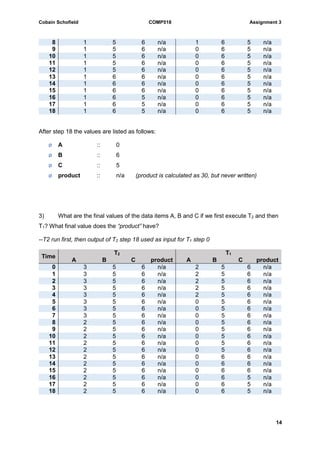
The document discusses a database creation assignment involving the creation of tables for books, authors, bookstores, and employees along with their relationships through queries using SQL. It explains the assumptions made during the database design, including data types and constraints, and provides various SQL queries to extract specific information from the created database. Additionally, it addresses transaction scheduling, discussing conflict serialization, the impact of locking mechanisms, and the resulting schedules.