


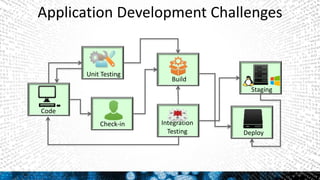

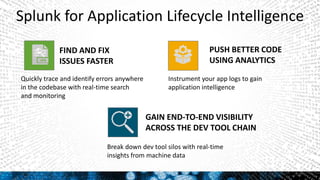



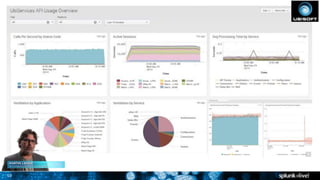

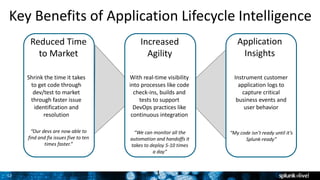


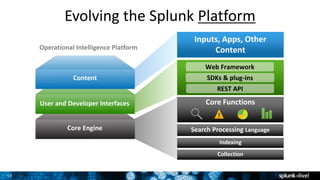
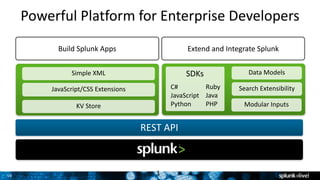
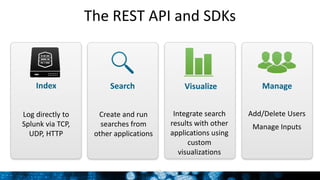















This document discusses Splunk for developers. It provides an overview of empowering developers with Splunk, building Splunk apps, and gaining application intelligence across the development lifecycle. Key points include instrumenting application logs for insights, integrating and extending Splunk, building unit testing and code integration, and gaining end-to-end visibility across development tools. The document also discusses resources for Splunk developers including tutorials, code samples, SDKs, and developer licenses.











































































































