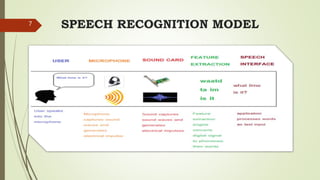
This document discusses speech user interfaces (SUI), which allow users to control computers using voice commands. It outlines the need for SUI to provide hands-free access for various users, including opportunities for illiterate populations. The document then covers an overview of speech recognition techniques like MFCC and HMM for feature extraction. It describes implementing an SUI, including recording speech, training models, and recognizing commands. Example applications are voice dialing, assistants, and accessibility tools. The document concludes by noting future areas like language learning and medical dictation, as well as challenges like vocabulary size and noise interference.