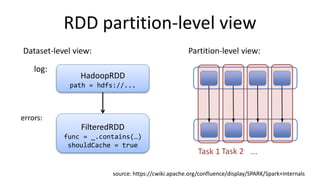
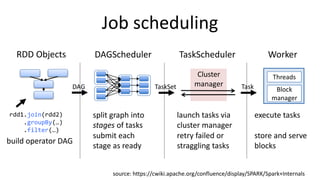
Spark is an expressive computing system that facilitates in-memory computing using resilient distributed datasets (RDDs) to avoid storing intermediate results on disk. RDDs can be cached in memory across partitions on a cluster and transformed through deterministic operations to build new RDDs, with actions then triggering execution. For example, a text file can be loaded as an RDD, filtered to extract error lines, cached, and have counts performed on error types.