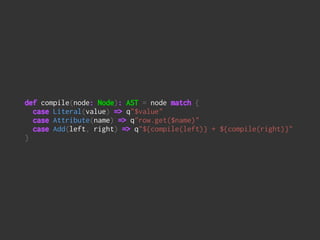
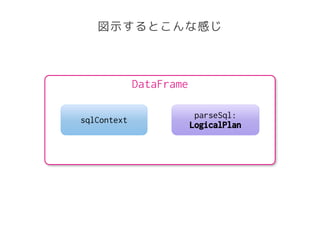
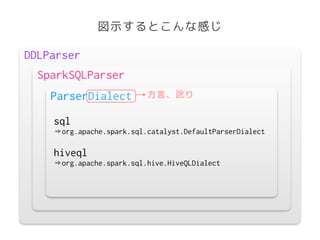
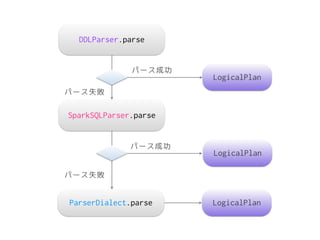
The document discusses Spark SQL's SQL parsing process. It explains that sqlContext.sql() uses a DDLParser and SparkSQLParser to parse the SQL string into a LogicalPlan using a ParserDialect. It then shows the classes involved in more detail, including the AbstractSparkSQLParser which is extended by SqlParser to define the parsing rules and parse the SQL into a LogicalPlan. It also mentions that Project Tungsten changed parts of the parsing from parser combinators to runtime code generation for performance.






![protected[sql] def parseSql(sql: String): LogicalPlan =
ddlParser.parse(sql, false)
!
@transient
protected[sql] val ddlParser =
new DDLParser(sqlParser.parse(_))
!
@transient
protected[sql] val sqlParser =
new SparkSQLParser(getSQLDialect().parse(_))
!
!
protected[sql] def getSQLDialect(): ParserDialect = {
try {
val clazz = Utils.classForName(dialectClassName)
clazz.newInstance().asInstanceOf[ParserDialect]
} catch {
case NonFatal(e) =>
:
}
}](https://image.slidesharecdn.com/sparksql-150623115659-lva1-app6892/85/SparkSQL-7-320.jpg)

![private[sql] abstract class AbstractSparkSQLParser
extends StandardTokenParsers with PackratParsers {
def parse(input: String): LogicalPlan = {
// Initialize the Keywords.
lexical.initialize(reservedWords)
phrase(start)(new lexical.Scanner(input)) match {
case Success(plan, _) => plan
case failureOrError =>
sys.error(failureOrError.toString)
}
}
:
}
今度はこの2つを
見てみます。](https://image.slidesharecdn.com/sparksql-150623115659-lva1-app6892/85/SparkSQL-11-320.jpg)
![class SqlParser extends AbstractSparkSQLParser with DataTypeParser {
protected val ABS = Keyword(“ABS")
protected val ALL = Keyword(“ALL”)
:
protected val WHEN = Keyword(“WHEN")
protected val WHERE = Keyword(“WHERE")
protected val WITH = Keyword("WITH")
!
protected lazy val start: Parser[LogicalPlan] =
start1 | insert | cte
!
protected lazy val start1: Parser[LogicalPlan] =
(select | ("(" ~> select <~ ")")) *
( UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) }
| INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) }
| EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)}
| UNION ~ DISTINCT.? ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
)
!
protected lazy val select: Parser[LogicalPlan] =
SELECT ~> DISTINCT.? ~
repsep(projection, ",") ~
(FROM ~> relations).? ~
(WHERE ~> expression).? ~
(GROUP ~ BY ~> rep1sep(expression, ",")).? ~
(HAVING ~> expression).? ~
sortType.? ~
(LIMIT ~> expression).? ^^ {
case d ~ p ~ r ~ f ~ g ~ h ~ o ~ l =>
val base = r.getOrElse(OneRowRelation)
val withFilter = f.map(Filter(_, base)).getOrElse(base)
val withProjection = g
.map(Aggregate(_, assignAliases(p), withFilter))
.getOrElse(Project(assignAliases(p), withFilter))
val withDistinct = d.map(_ => Distinct(withProjection)).getOrElse(withProjection)
val withHaving = h.map(Filter(_, withDistinct)).getOrElse(withDistinct)
val withOrder = o.map(_(withHaving)).getOrElse(withHaving)
val withLimit = l.map(Limit(_, withOrder)).getOrElse(withOrder)
withLimit
}
!
protected lazy val insert: Parser[LogicalPlan] =
INSERT ~> (OVERWRITE ^^^ true | INTO ^^^ false) ~ (TABLE ~> relation) ~ select ^^ {
case o ~ r ~ s => InsertIntoTable(r, Map.empty[String, Option[String]], s, o, false)
}
:
}](https://image.slidesharecdn.com/sparksql-150623115659-lva1-app6892/85/SparkSQL-12-320.jpg)
![class SqlParser extends AbstractSparkSQLParser with DataTypeParser {
protected val ABS = Keyword(“ABS")
protected val ALL = Keyword(“ALL”)
:
protected val WHEN = Keyword(“WHEN")
protected val WHERE = Keyword(“WHERE")
protected val WITH = Keyword("WITH")
!
protected lazy val start: Parser[LogicalPlan] =
start1 | insert | cte
!
protected lazy val start1: Parser[LogicalPlan] =
(select | ("(" ~> select <~ ")")) *
( UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) }
| INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) }
| EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)}
| UNION ~ DISTINCT.? ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
)
!
protected lazy val select: Parser[LogicalPlan] =
SELECT ~> DISTINCT.? ~
repsep(projection, ",") ~
(FROM ~> relations).? ~
(WHERE ~> expression).? ~
(GROUP ~ BY ~> rep1sep(expression, ",")).? ~
(HAVING ~> expression).? ~
sortType.? ~
(LIMIT ~> expression).? ^^ {
case d ~ p ~ r ~ f ~ g ~ h ~ o ~ l =>
val base = r.getOrElse(OneRowRelation)
val withFilter = f.map(Filter(_, base)).getOrElse(base)
val withProjection = g
.map(Aggregate(_, assignAliases(p), withFilter))
.getOrElse(Project(assignAliases(p), withFilter))
val withDistinct = d.map(_ => Distinct(withProjection)).getOrElse(withProjection)
val withHaving = h.map(Filter(_, withDistinct)).getOrElse(withDistinct)
val withOrder = o.map(_(withHaving)).getOrElse(withHaving)
val withLimit = l.map(Limit(_, withOrder)).getOrElse(withOrder)
withLimit
}
!
protected lazy val insert: Parser[LogicalPlan] =
INSERT ~> (OVERWRITE ^^^ true | INTO ^^^ false) ~ (TABLE ~> relation) ~ select ^^ {
case o ~ r ~ s => InsertIntoTable(r, Map.empty[String, Option[String]], s, o, false)
}
:
}
そうです。おなじみの
パーサー・コンビネータです。](https://image.slidesharecdn.com/sparksql-150623115659-lva1-app6892/85/SparkSQL-13-320.jpg)