Download as PDF, PPTX




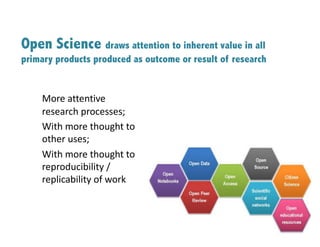


![Data Management Plans (DMP)
• Researcher writes a Data Management Plan
for the important data that they expect to
create during course of their research
• By National Science Foundation: “What
constitutes reasonable data management and
access will be determined by the community
of interest through process of peer review and
program management.” [Data Management & Sharing Frequently
Asked Questions, National Science Founation]](https://image.slidesharecdn.com/openscience-datasciencefinal-190113220718/85/Open-science-as-roadmap-to-better-data-science-research-7-320.jpg)
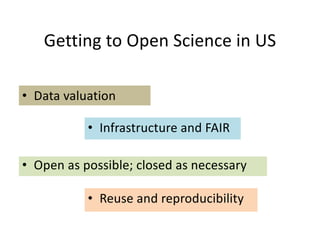



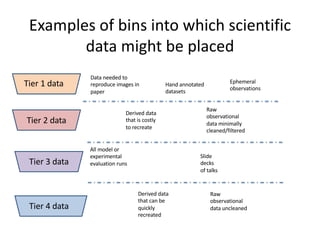

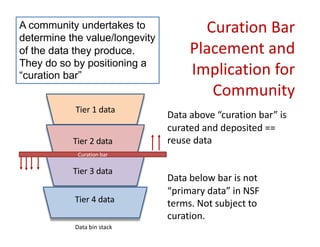
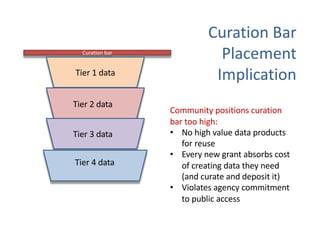
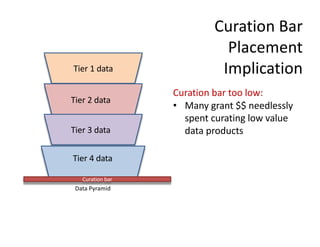
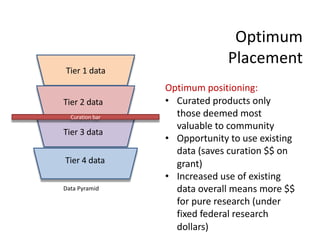








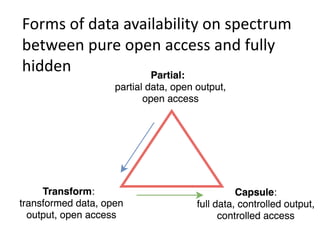







The document discusses the importance of open science in data science, emphasizing that it leads to better research outcomes and societal benefits by encouraging transparency, collaboration, and data sharing. It outlines the role of funders, such as the National Science Foundation, in promoting open science through data management plans and establishing curation practices for data based on its value. Key principles of FAIR data management are presented, advocating for data to be findable, accessible, interoperable, and reusable, while also highlighting the ongoing evolution and adoption of these practices in the scientific community.








































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)





