Download as PDF, PPTX





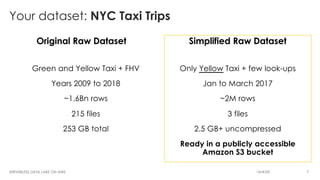


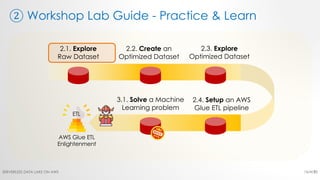
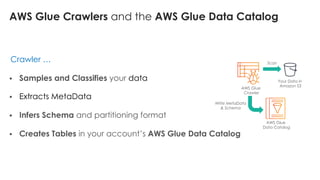

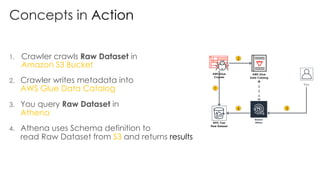

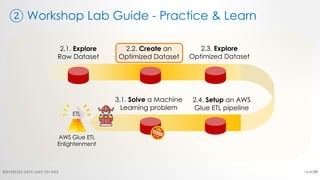

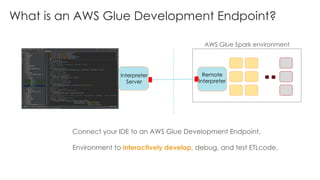

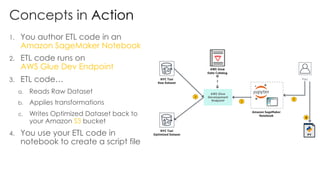


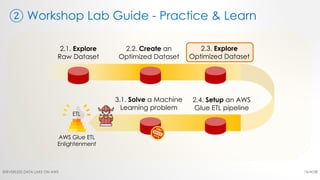
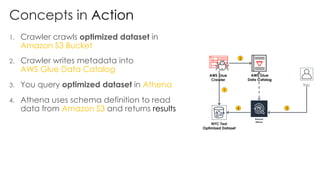

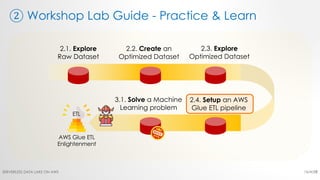



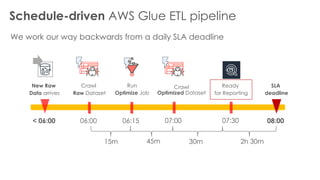
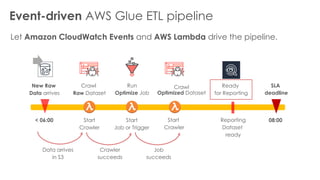
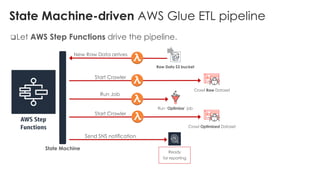
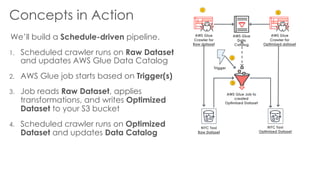

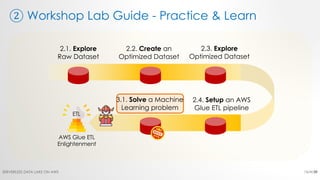

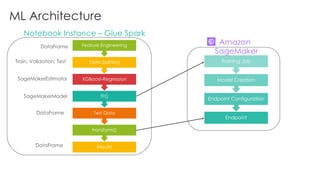
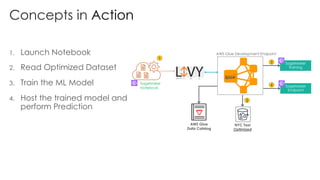




The document is a workshop lab guide for building a serverless data lake on AWS, specifically focused on processing and analyzing NYC taxi trip data using AWS services such as Glue, Athena, and SageMaker. It describes the steps to set up a data lake, optimize datasets for reporting, and develop machine learning models to predict passenger tipping behavior. The guide includes practical hands-on exercises for cataloging data, querying datasets, and applying ETL (extract, transform, load) workflows.




















![[AWS Builders] Effective AWS Glue](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws301effectiveawsgluetaehyunkim-190306061037-thumbnail.jpg?width=640&height=640&fit=bounds)














































