Download as PDF, PPTX






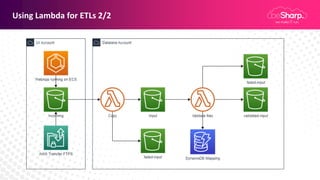

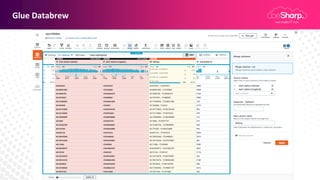
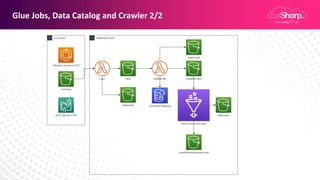
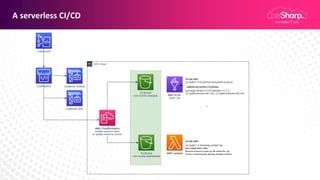
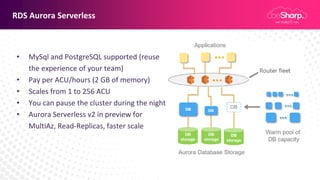
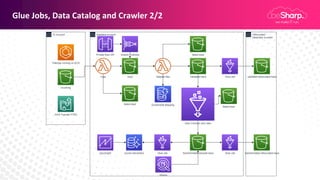




Claudio Pontili, a senior cloud solution architect at beSharp, presented on using serverless architectures for big data on AWS. He discussed using Lambda for ETL processes and Glue for managed ETL jobs. He also covered CI/CD for deploying Lambda and Glue code, data warehousing on Aurora Serverless v1, and a fully serverless big data architecture. Some key learnings included using serverless for high availability and scalability with no effort, pausing Aurora Serverless v1 clusters when not in use, and using infrastructure as code to deploy architectures.




































![Jumpstart your idea with AWS Serverless [Oct 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/jumpstartyourideawithawsserverlessoct2020-240904053409-07f4072b-thumbnail.jpg?width=640&height=640&fit=bounds)




































