Download to read offline





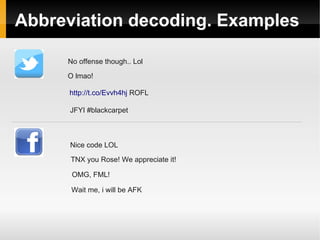


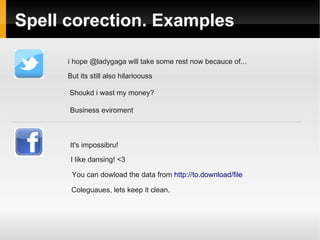


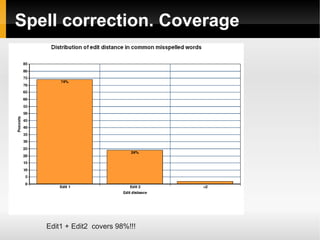



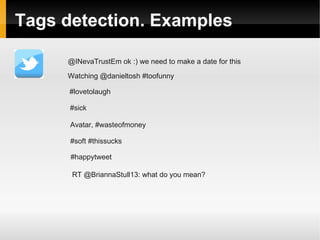
![Tags detection. Words splitting
Dynamic programming
Statistical approach due to ambiguity
#orcore → [orc_ore], [or_core]
#expertsexchange → [expert_sex_change], [experts_exchange]
Train data
Dictionary (default linux ~100K words)](https://image.slidesharecdn.com/sentiments-141111150153-conversion-gate01/85/Sentiments-Improvement-22-320.jpg)
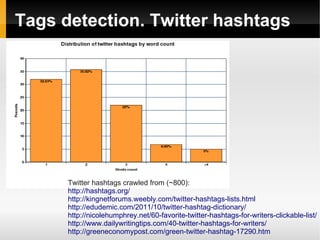
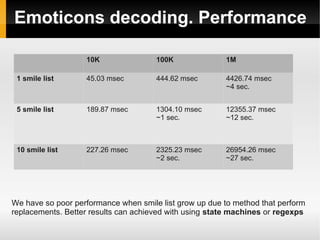
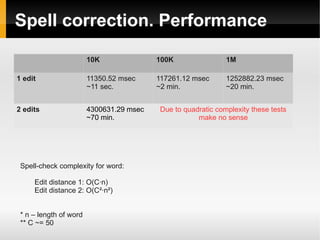
![Tags detection. Performance
100 400 800
Time 4019.73 msec
~4 sec.
6429.19
~6 sec.
7897.23
~8 sec.
Accuracy 83.00% 86.25% 84.88%
Main problems:
● Train set not often solves ambiguity problem
● Dictionary hits filter lot of right candidates
#rapnotamusic → [ra_p_not_a_music]](https://image.slidesharecdn.com/sentiments-141111150153-conversion-gate01/85/Sentiments-Improvement-24-320.jpg)




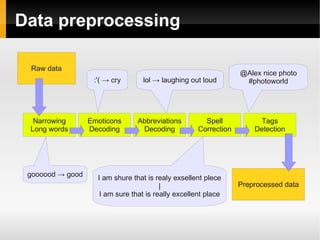
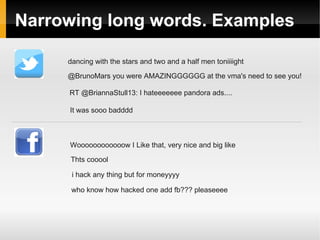
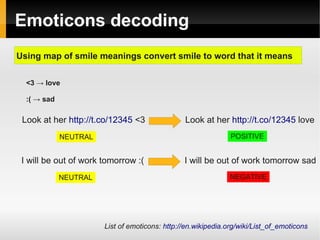
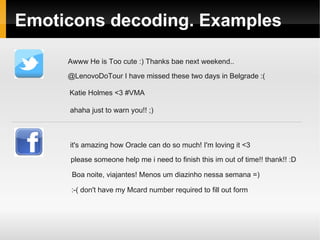
The document proposes ideas for sentiment analysis including data preprocessing techniques like narrowing long words, decoding emoticons and abbreviations, spell correction, and detecting tags. It discusses the approaches, provides examples, and analyzes performance for each technique. The techniques are meant to preprocess data before calculating sentiment to improve accuracy. The document also lists potential improvements to the current approaches.



































![NLP Asignment Final Presentation [IIT-Bombay]](https://cdn.slidesharecdn.com/ss_thumbnails/final-presentation-131213084802-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




























