Download to read offline



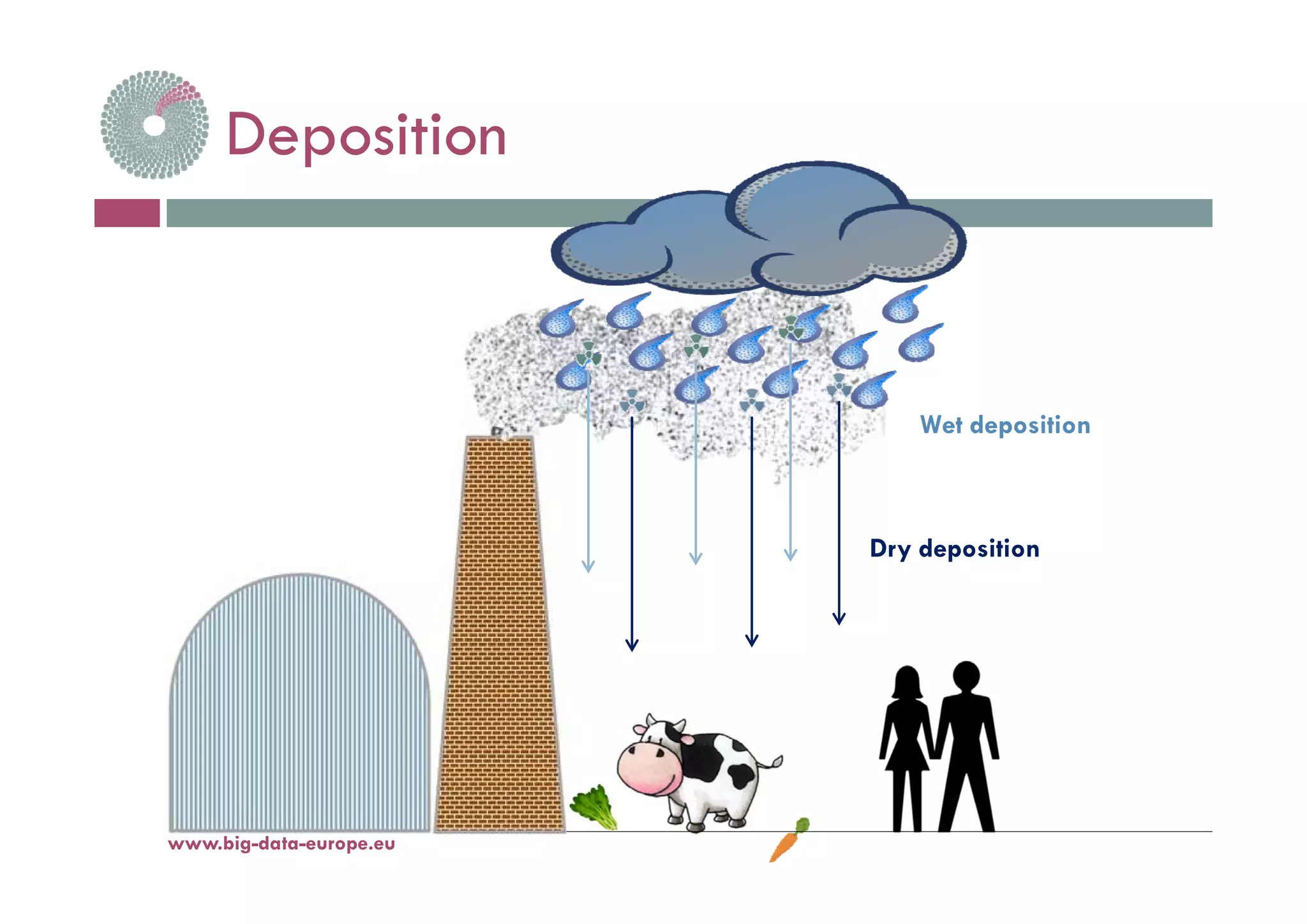


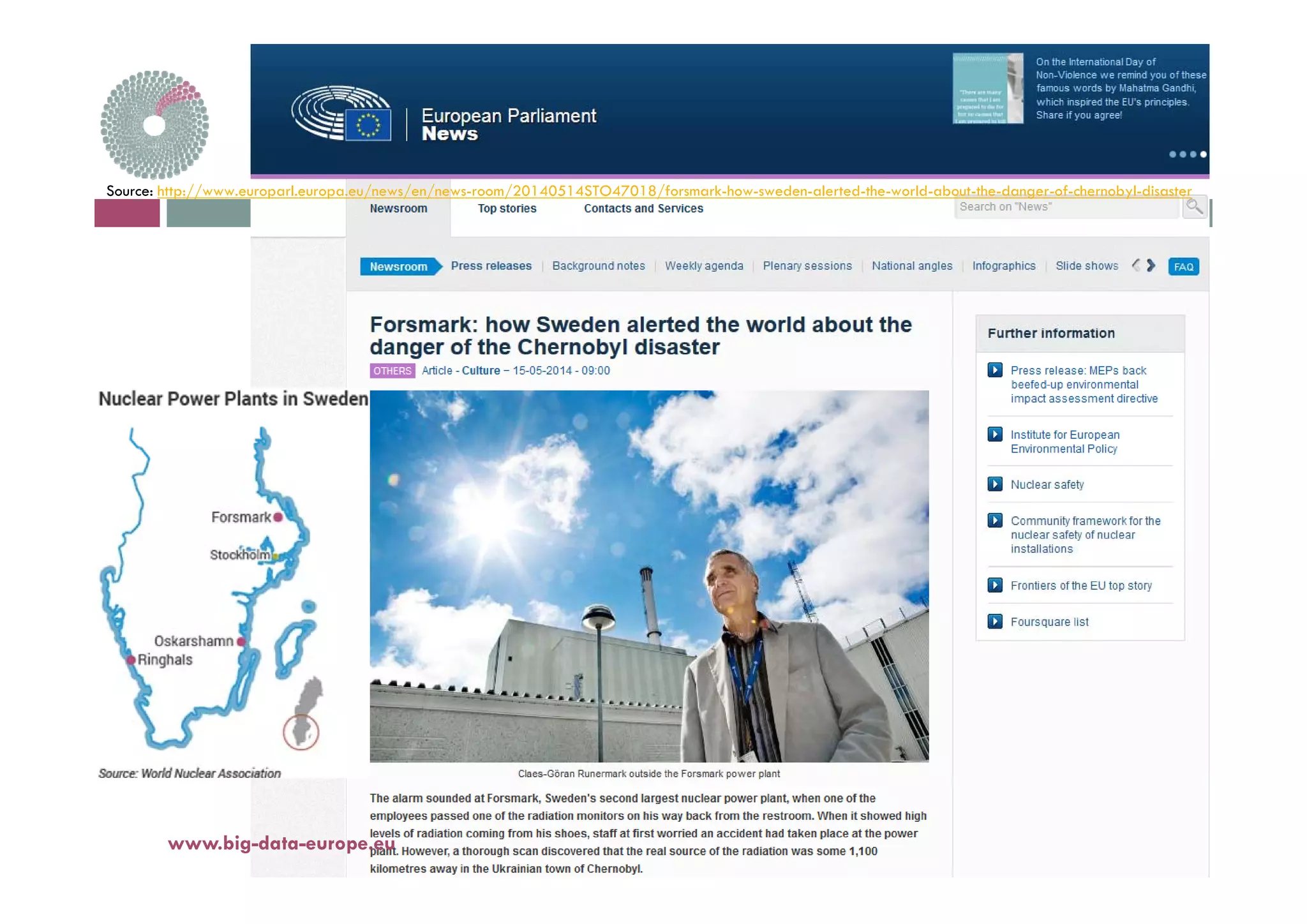











This document discusses leveraging big data techniques to identify the release location of a hazardous substance into the atmosphere. It summarizes previous contamination incidents like Chernobyl and Fukushima and the challenges of inverse modeling. The proposed approach uses a large database of pre-computed dispersion simulations and historical weather data managed by big data tools. Matching current conditions to similar pre-computed cases could solve the release location faster than traditional computationally intensive inverse modeling. Key open issues to explore are defining "similar enough" weather and ensuring manageable database volumes for accurate matching.

































































































