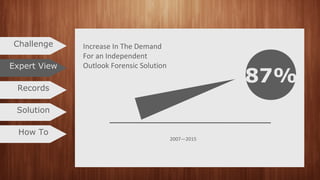
The document outlines a procedure for investigating PST files without needing Outlook installed, highlighting the ability to traverse PST files and search for evidence among numerous emails. It discusses examination of both ANSI and Unicode formats, categorization of attachments, and the generation of structured investigation reports. Additionally, it covers the use of various search filters and criteria available in the MailXaminer software to effectively extract email evidence.