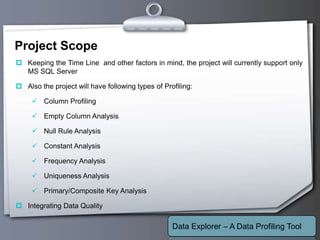
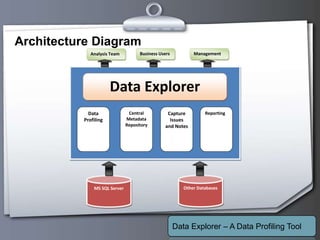
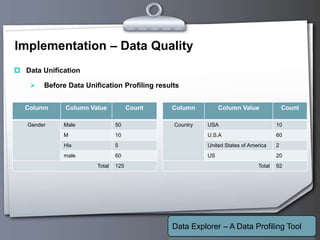
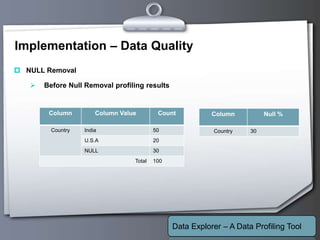
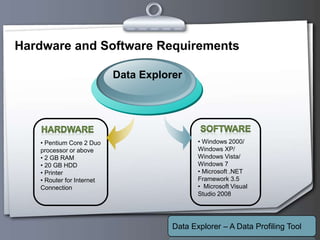
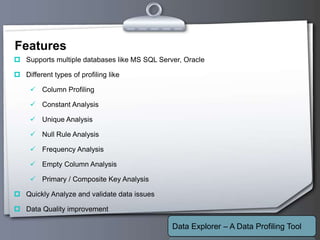
This document outlines a proposed data profiling tool called Data Explorer. It discusses the need for data profiling, limitations of existing approaches, and provides details on the proposed solution. Key points include: Data Explorer will provide an easy to use interface for profiling multiple databases, support various profiling types like column, constant, and unique analysis, integrate data quality checking, and be developed using .NET with C# on Windows platforms. It aims to help users better understand data issues and quality.