Download to read offline


![Стратегии резервирования /1
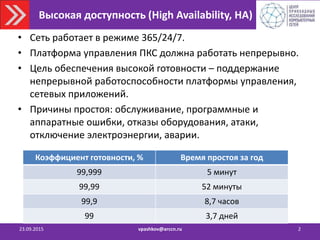
23.09.2015 vpashkov@arccn.ru 4
Active/Standby
(Passive) стратегии:
• Холодное
[без синхронизации]
• Теплое
[периодическая
синхронизация]
• Горячее
[постоянная
синхронизация]](https://image.slidesharecdn.com/2015-150923123303-lva1-app6892/85/SDN-4-320.jpg)
![Стратегии резервирования /2
23.09.2015 vpashkov@arccn.ru 6
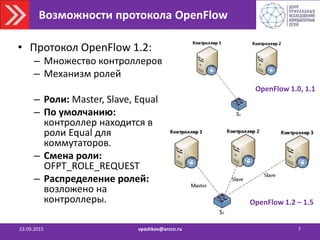
• Стратегии резервирования Active/Active
– Ассиметричная
– Симметричная
• Высокая сложность [Требуется координация контроллеров,
поддержка глобального состояния]
• Высокая доступность [минимальное время простоя]
• Высокая утилизация вычислительных ресурсов](https://image.slidesharecdn.com/2015-150923123303-lva1-app6892/85/SDN-6-320.jpg)
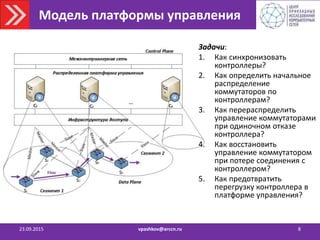

![Задача 1: Синхронизация контроллеров
• На основе Multi-Paxos
• Обеспечивает одновременное одинаковое выполнение команд
контроллеров
• Команды: изменение Network View, установление новых потоков (чтение
NV), изменение ролей контроллеров.
23.09.2015 vpashkov@arccn.ru 10
Add NodeAdd Flow...
Журнал событий
In-memory
хранилище
ДКА
Контроллер
[MASTER]
Сервис синхронизации
Событие
Add NodeAdd Flow...
Журнал событий
ДКА
Контроллер
[SLAVE]
Сервис синхронизации
Add NodeAdd Flow...
Журнал событий
ДКА
Контроллер
[SLAVE]
Сервис синхронизации
Сегмент
Network 1
Сегмент
Network 2
Сегмент
Network 3
Состояние
Network View 1
In-memory
хранилище
Состояние
Network View 1
In-memory
хранилище
Состояние
Network View 1
Proposer Acceptor Acceptor Acceptor](https://image.slidesharecdn.com/2015-150923123303-lva1-app6892/85/SDN-10-320.jpg)
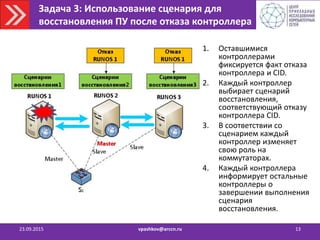
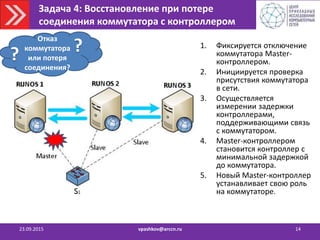
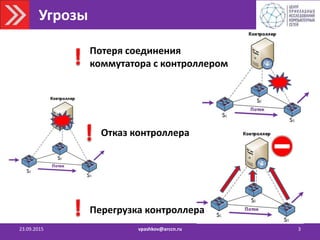
![Задача 5: Предотвращение перегрузки
контроллера платформы управления
23.09.2015 vpashkov@arccn.ru 15
Для обнаружения перегрузки:
• Устанавливаются пороговые значения
параметров загрузки контроллеров.
• Осуществляется постоянный мониторинг
загрузки контроллеров
[количество коммутаторов, количество packet-
in запросов в секунду, CPU, память]
• Факт перегрузки фиксируется при
обнаружении превышения порогового
значения.
Задача перераспределения коммутаторов по контроллерам: Необходимо
перераспределить коммутаторы так, чтобы:
1. Нагрузка на каждый из контроллеров не превышала его производительности
2. Использовалось минимальное количество контроллеров.
3. При перестроении управления сетью было проведено минимальное
количество передач управления коммутаторами.](https://image.slidesharecdn.com/2015-150923123303-lva1-app6892/85/SDN-15-320.jpg)
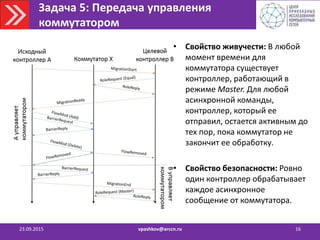


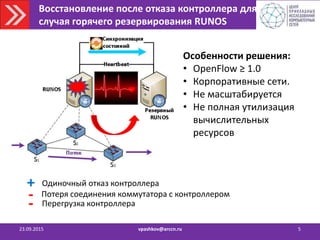
![Выводы
23.09.2015 vpashkov@arccn.ru 19
• Проект RUNOS (C++, OF 1.3)
https://github.com/ARCCN/runos
• RUNOS с поддержкой Active/Standby стратегии
горячего резервирования для небольших сетей
[в открытый доступ]
• RUNOS с поддержкой стратегии Active/Active
Оптимизация разработанных алгоритмов
Разработка распределенных приложений](https://image.slidesharecdn.com/2015-150923123303-lva1-app6892/85/SDN-19-320.jpg)


Документ описывает HA-платформу управления для программно-конфигурируемых сетей, акцентируя внимание на обеспечении высокой доступности и непрерывной работоспособности сетевых приложений. Рассматриваются стратегии резервирования, протокол OpenFlow и методы синхронизации контроллеров для предотвращения простоев и перегрузок. В заключение упоминается проект runos, который поддерживает различные стратегии резервирования и предлагает открытый доступ к разработке.




























































