Download to read offline






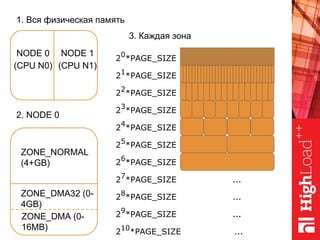
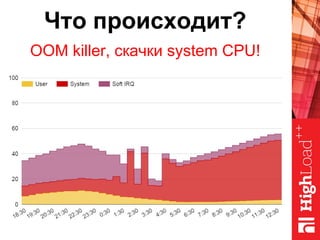
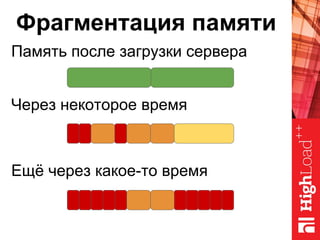






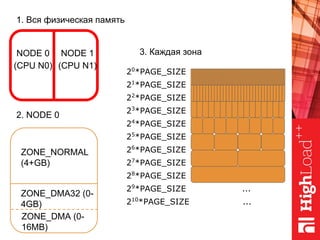
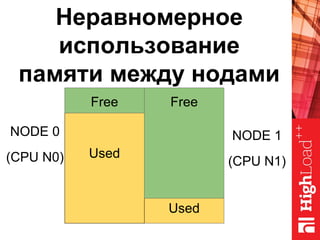





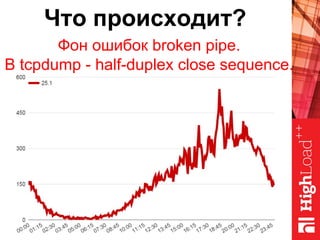


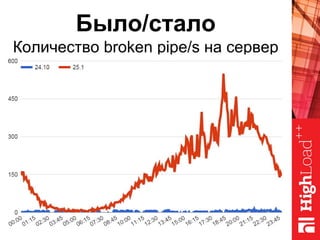


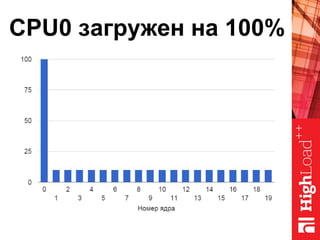

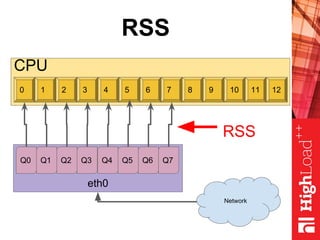
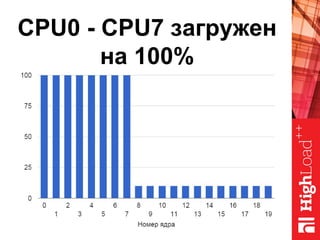
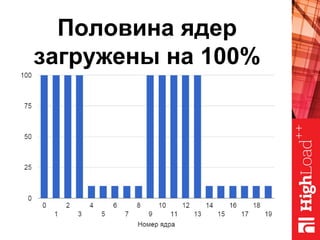

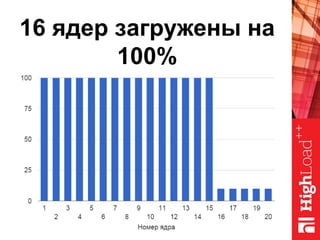





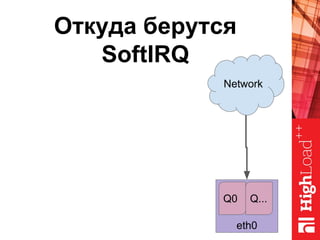
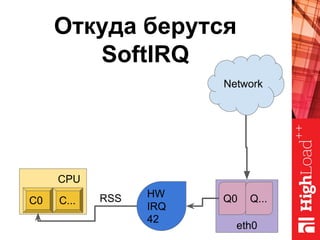
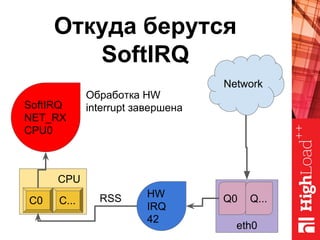
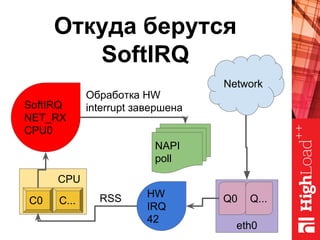
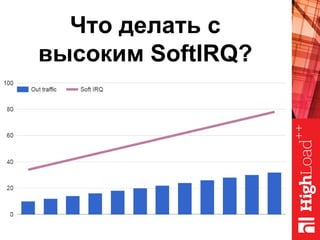
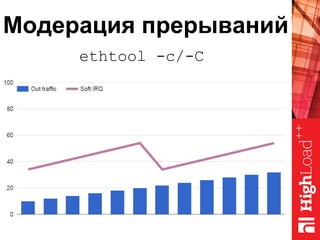

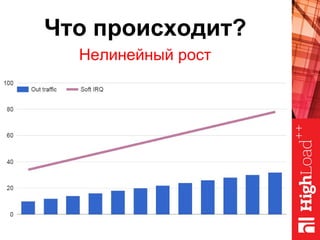


Документ описывает оптимизацию памяти и сетевого стека в Linux, включая историю перехода высоконагруженных серверов на новые дистрибутивы. Рассматриваются проблемы, такие как фрагментация памяти, неравномерное распределение нагрузки по процессорам и механизмы управления сетевыми прерываниями. Предлагаются решения для повышения производительности, включая настройку параметров ядра и оптимизацию распределения сетевых нагрузок.


































