Downloaded 90 times



































![One to Many
Schema Design Choices
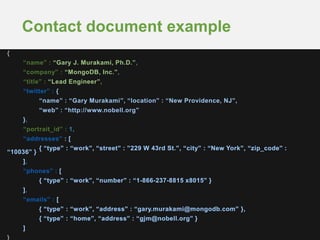
contact
• phone_ids: [ ]
1
N
phone
• phones
phone N
• Not possible in relational DBs
• Save a fetch?
contact
Contact
phone
1
N • contact_id
Redundant to track relationship on both sides
• Both references must be updated for consistency](https://image.slidesharecdn.com/schemadesign-140221091823-phpapp01/85/Schema-Design-36-320.jpg)



![Many to Many
Schema Design Choices
group
•
contact_ids: [ ] N N
contact
group
• contacts
contact
group
contact
• groups
N
group
N
contact
N N • group_ids: [
]
Redundant to track
relationship on both sides
•
Both references must be
updated for consistency
Redundant to track
relationship on both sides
•
Duplicated data must be
updated for consistency](https://image.slidesharecdn.com/schemadesign-140221091823-phpapp01/85/Schema-Design-40-320.jpg)
![Many to Many
General Recommendation
contact
• Depends on use case
group N N • group_ids: [
1.
Simple address book
]
• Contact references groups
2. Corporate email groups
• Group embeds contacts for performance
• Exceptional cases
– Scaling: maximum document size is 16MB
– Scaling may affect performance and working set](https://image.slidesharecdn.com/schemadesign-140221091823-phpapp01/85/Schema-Design-41-320.jpg)








This document discusses schema design concepts for document databases like MongoDB. It covers key concepts like embedding related data for optimal performance and flexible schemas. The document recommends embedding over referencing in most cases, especially for one-to-one and one-to-many relationships where related objects are often viewed together. Many-to-many relationships are more flexible, with embedding recommended for some use cases and referencing for others depending on the needs of the application. The goal is to design schemas that match how the application will use the data.













![Complejo Tabacalero[1]](https://cdn.slidesharecdn.com/ss_thumbnails/complejotabacalero1-091005195942-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)






























