Download as PDF, PPTX







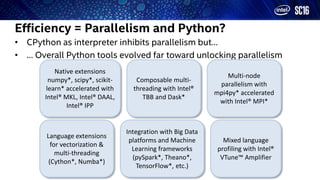








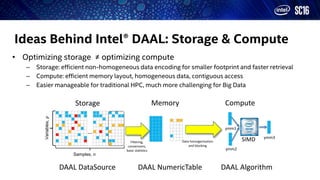







This document discusses scaling Python to HPC and big data environments. It describes how Intel provides Python distributions to improve performance and parallelism. Key points include: - Intel distributions optimize Python packages like NumPy and SciPy with Intel MKL to improve performance of dense and sparse linear algebra operations. - Composable multi-threading is supported using Intel TBB to better balance workloads across CPU threads. - Intel DAAL provides optimized algorithms for machine learning in scikit-learn to accelerate tasks like PCA. The document outlines techniques Intel uses to make Python more suitable for high performance and big data computing through parallelism, optimized libraries, and integration with frameworks like Spark and TensorFlow.









































































