Being Reproducible: SSBSS Summer School 2017Carole Goble
Lecture 2:
Being Reproducible: Models, Research Objects and R* Brouhaha
Reproducibility is a R* minefield, depending on whether you are testing for robustness (rerun), defence (repeat), certification (replicate), comparison (reproduce) or transferring between researchers (reuse). Different forms of "R" make different demands on the completeness, depth and portability of research. Sharing is another minefield raising concerns of credit and protection from sharp practices.
In practice the exchange, reuse and reproduction of scientific experiments is dependent on bundling and exchanging the experimental methods, computational codes, data, algorithms, workflows and so on along with the narrative. These "Research Objects" are not fixed, just as research is not “finished”: the codes fork, data is updated, algorithms are revised, workflows break, service updates are released. ResearchObject.org is an effort to systematically support more portable and reproducible research exchange.
In this talk I will explore these issues in more depth using the FAIRDOM Platform and its support for reproducible modelling. The talk will cover initiatives and technical issues, and raise social and cultural challenges.
Biology 100
Stephanie Burdett
Biology Department
Brigham Young University
Provo, Utah
Portfolio Question #4
The Logic of Hypothesis Testing
Important information about completing this assignment:
1. Please thoughtfully and carefully respond to each question and exercise. It is not important whether or not you are able to come up with the “right” answer. As you can see from the grading guide your work will be assessed based on your ability to think and work as a scientist!
2. Make sure you format your paper so that you’ve included titles for each part of the activity and that you submit your document properly
The Activity:
A. Title: Observations
· Record at least 4 observations:
·
·
·
·
B. Title: Question Development
· Write down at least 2 questions generated from your observations. Make sure the questions you pose are suitable for firsthand scientific investigation:
·
·
C. Title: Constructing A Hypothesis
· Select one investigable question from the list you made in question B and use it to construct a hypothesis. Make sure you write a highly formalized hypothesis – If….then statement that focuses on a single independent variable and clearly shows its relationship to the dependent variable. Don’t forget to include a prediction:
D. Title: Experimental Design
· Design an experiment to test your hypothesis. Use bullet points to briefly describe your experimental protocol. You should carefully think about materials, methods, how you will control for extraneous variable, and the data you will collect:
E. Title: Data From The Experiment
· Think about the types of data (qualitative and quantitative) that you want to collect to provide evidence for the hypothesis. Collect suitable data and display it appropriately (graphically, textually, etc.)
· List strengths and weaknesses of this experiment (i.e. what variables weren’t appropriately controlled, etc.)
F. Title: Data Analysis – Conclusion
· Analyze your data. Provide at least 4 pieces of evidence from your analysis that either support or refute your hypothesis.
· Use bullet points to succinctly outline the main points of your conclusion:
G. Title: Recap
· Record at least 2 uncertainties you have(Use bullet points to give any reasons why you are not completely confident in your results/conclusion):
H. Title: Reflection
Review your notes from previous discussions and readings in the textbook to help you prepare your answers.
1. Record at One of the major tenets behind science is that any scientific hypothesis and the experimental design based on that hypothesis must be falsifiable. Briefly, provide an explanation for why falsifiability is the foundation of scientific experimentation and why this principle leads to scientific advancements in knowledge. Limit your answer to no more than 1 page, double-spaced, 12 point font.
2. Using the given vocabulary words where appropriate, summarize the process of turning an investigable question into a hypothes.
Building academic language in science-based subjectsDogberry Messina
Academic language in the sciences, its features and associated thinking and how to embed academic (complex) language skills in science based subjects at Palmer's College. The hand-outs are mostly not on this presentation.
Natural Language Processing on Non-Textual Datagpano
Talk by Casey Stella, presented at the SF Data Mining Hadoop Summit Meetup, on June 8, 2015. Notebook available at https://github.com/cestella/presentations/blob/master/NLP_on_non_textual_data/src/main/ipython/clinical2vec.ipynb
Towards comprehensive syntactic and semantic annotations of the clinical narr...Jinho Choi
Objective To create annotated clinical narratives with layers of syntactic and semantic labels to facilitate advances in clinical natural language processing (NLP). To develop NLP algorithms and open source components. Methods Manual annotation of a clinical narrative corpus of 127 606 tokens following the Treebank schema for syntactic information, PropBank schema for predicate-argument structures, and the Unified Medical Language System (UMLS) schema for semantic information. NLP components were developed. Results The final corpus consists of 13 091 sentences containing 1772 distinct predicate lemmas. Of the 766 newly created PropBank frames, 74 are verbs. There are 28 539 named entity (NE) annotations spread over 15 UMLS semantic groups, one UMLS semantic type, and the Person semantic category. The most frequent annotations belong to the UMLS semantic groups of Procedures (15.71%), Disorders (14.74%), Concepts and Ideas (15.10%), Anatomy (12.80%), Chemicals and Drugs (7.49%), and the UMLS semantic type of Sign or Symptom (12.46%). Inter-annotator agreement results: Treebank (0.926), PropBank (0.891–0.931), NE (0.697–0.750). The part-of-speech tagger, constituency parser, dependency parser, and semantic role labeler are built from the corpus and released open source. A significant limitation uncovered by this project is the need for the NLP community to develop a widely agreed-upon schema for the annotation of clinical concepts and their relations. Conclusions This project takes a foundational step towards bringing the field of clinical NLP up to par with NLP in the general domain. The corpus creation and NLP components provide a resource for research and application development that would have been previously impossible.
Being Reproducible: SSBSS Summer School 2017Carole Goble
Lecture 2:
Being Reproducible: Models, Research Objects and R* Brouhaha
Reproducibility is a R* minefield, depending on whether you are testing for robustness (rerun), defence (repeat), certification (replicate), comparison (reproduce) or transferring between researchers (reuse). Different forms of "R" make different demands on the completeness, depth and portability of research. Sharing is another minefield raising concerns of credit and protection from sharp practices.
In practice the exchange, reuse and reproduction of scientific experiments is dependent on bundling and exchanging the experimental methods, computational codes, data, algorithms, workflows and so on along with the narrative. These "Research Objects" are not fixed, just as research is not “finished”: the codes fork, data is updated, algorithms are revised, workflows break, service updates are released. ResearchObject.org is an effort to systematically support more portable and reproducible research exchange.
In this talk I will explore these issues in more depth using the FAIRDOM Platform and its support for reproducible modelling. The talk will cover initiatives and technical issues, and raise social and cultural challenges.
Biology 100
Stephanie Burdett
Biology Department
Brigham Young University
Provo, Utah
Portfolio Question #4
The Logic of Hypothesis Testing
Important information about completing this assignment:
1. Please thoughtfully and carefully respond to each question and exercise. It is not important whether or not you are able to come up with the “right” answer. As you can see from the grading guide your work will be assessed based on your ability to think and work as a scientist!
2. Make sure you format your paper so that you’ve included titles for each part of the activity and that you submit your document properly
The Activity:
A. Title: Observations
· Record at least 4 observations:
·
·
·
·
B. Title: Question Development
· Write down at least 2 questions generated from your observations. Make sure the questions you pose are suitable for firsthand scientific investigation:
·
·
C. Title: Constructing A Hypothesis
· Select one investigable question from the list you made in question B and use it to construct a hypothesis. Make sure you write a highly formalized hypothesis – If….then statement that focuses on a single independent variable and clearly shows its relationship to the dependent variable. Don’t forget to include a prediction:
D. Title: Experimental Design
· Design an experiment to test your hypothesis. Use bullet points to briefly describe your experimental protocol. You should carefully think about materials, methods, how you will control for extraneous variable, and the data you will collect:
E. Title: Data From The Experiment
· Think about the types of data (qualitative and quantitative) that you want to collect to provide evidence for the hypothesis. Collect suitable data and display it appropriately (graphically, textually, etc.)
· List strengths and weaknesses of this experiment (i.e. what variables weren’t appropriately controlled, etc.)
F. Title: Data Analysis – Conclusion
· Analyze your data. Provide at least 4 pieces of evidence from your analysis that either support or refute your hypothesis.
· Use bullet points to succinctly outline the main points of your conclusion:
G. Title: Recap
· Record at least 2 uncertainties you have(Use bullet points to give any reasons why you are not completely confident in your results/conclusion):
H. Title: Reflection
Review your notes from previous discussions and readings in the textbook to help you prepare your answers.
1. Record at One of the major tenets behind science is that any scientific hypothesis and the experimental design based on that hypothesis must be falsifiable. Briefly, provide an explanation for why falsifiability is the foundation of scientific experimentation and why this principle leads to scientific advancements in knowledge. Limit your answer to no more than 1 page, double-spaced, 12 point font.
2. Using the given vocabulary words where appropriate, summarize the process of turning an investigable question into a hypothes.
Building academic language in science-based subjectsDogberry Messina
Academic language in the sciences, its features and associated thinking and how to embed academic (complex) language skills in science based subjects at Palmer's College. The hand-outs are mostly not on this presentation.
Natural Language Processing on Non-Textual Datagpano
Talk by Casey Stella, presented at the SF Data Mining Hadoop Summit Meetup, on June 8, 2015. Notebook available at https://github.com/cestella/presentations/blob/master/NLP_on_non_textual_data/src/main/ipython/clinical2vec.ipynb
Towards comprehensive syntactic and semantic annotations of the clinical narr...Jinho Choi
Objective To create annotated clinical narratives with layers of syntactic and semantic labels to facilitate advances in clinical natural language processing (NLP). To develop NLP algorithms and open source components. Methods Manual annotation of a clinical narrative corpus of 127 606 tokens following the Treebank schema for syntactic information, PropBank schema for predicate-argument structures, and the Unified Medical Language System (UMLS) schema for semantic information. NLP components were developed. Results The final corpus consists of 13 091 sentences containing 1772 distinct predicate lemmas. Of the 766 newly created PropBank frames, 74 are verbs. There are 28 539 named entity (NE) annotations spread over 15 UMLS semantic groups, one UMLS semantic type, and the Person semantic category. The most frequent annotations belong to the UMLS semantic groups of Procedures (15.71%), Disorders (14.74%), Concepts and Ideas (15.10%), Anatomy (12.80%), Chemicals and Drugs (7.49%), and the UMLS semantic type of Sign or Symptom (12.46%). Inter-annotator agreement results: Treebank (0.926), PropBank (0.891–0.931), NE (0.697–0.750). The part-of-speech tagger, constituency parser, dependency parser, and semantic role labeler are built from the corpus and released open source. A significant limitation uncovered by this project is the need for the NLP community to develop a widely agreed-upon schema for the annotation of clinical concepts and their relations. Conclusions This project takes a foundational step towards bringing the field of clinical NLP up to par with NLP in the general domain. The corpus creation and NLP components provide a resource for research and application development that would have been previously impossible.
Elevating Tactical DDD Patterns Through Object CalisthenicsDorra BARTAGUIZ
After immersing yourself in the blue book and its red counterpart, attending DDD-focused conferences, and applying tactical patterns, you're left with a crucial question: How do I ensure my design is effective? Tactical patterns within Domain-Driven Design (DDD) serve as guiding principles for creating clear and manageable domain models. However, achieving success with these patterns requires additional guidance. Interestingly, we've observed that a set of constraints initially designed for training purposes remarkably aligns with effective pattern implementation, offering a more ‘mechanical’ approach. Let's explore together how Object Calisthenics can elevate the design of your tactical DDD patterns, offering concrete help for those venturing into DDD for the first time!
LF Energy Webinar: Electrical Grid Modelling and Simulation Through PowSyBl -...DanBrown980551
Do you want to learn how to model and simulate an electrical network from scratch in under an hour?
Then welcome to this PowSyBl workshop, hosted by Rte, the French Transmission System Operator (TSO)!
During the webinar, you will discover the PowSyBl ecosystem as well as handle and study an electrical network through an interactive Python notebook.
PowSyBl is an open source project hosted by LF Energy, which offers a comprehensive set of features for electrical grid modelling and simulation. Among other advanced features, PowSyBl provides:
- A fully editable and extendable library for grid component modelling;
- Visualization tools to display your network;
- Grid simulation tools, such as power flows, security analyses (with or without remedial actions) and sensitivity analyses;
The framework is mostly written in Java, with a Python binding so that Python developers can access PowSyBl functionalities as well.
What you will learn during the webinar:
- For beginners: discover PowSyBl's functionalities through a quick general presentation and the notebook, without needing any expert coding skills;
- For advanced developers: master the skills to efficiently apply PowSyBl functionalities to your real-world scenarios.
Slack (or Teams) Automation for Bonterra Impact Management (fka Social Soluti...Jeffrey Haguewood
Sidekick Solutions uses Bonterra Impact Management (fka Social Solutions Apricot) and automation solutions to integrate data for business workflows.
We believe integration and automation are essential to user experience and the promise of efficient work through technology. Automation is the critical ingredient to realizing that full vision. We develop integration products and services for Bonterra Case Management software to support the deployment of automations for a variety of use cases.
This video focuses on the notifications, alerts, and approval requests using Slack for Bonterra Impact Management. The solutions covered in this webinar can also be deployed for Microsoft Teams.
Interested in deploying notification automations for Bonterra Impact Management? Contact us at sales@sidekicksolutionsllc.com to discuss next steps.
Software Delivery At the Speed of AI: Inflectra Invests In AI-Powered QualityInflectra
In this insightful webinar, Inflectra explores how artificial intelligence (AI) is transforming software development and testing. Discover how AI-powered tools are revolutionizing every stage of the software development lifecycle (SDLC), from design and prototyping to testing, deployment, and monitoring.
Learn about:
• The Future of Testing: How AI is shifting testing towards verification, analysis, and higher-level skills, while reducing repetitive tasks.
• Test Automation: How AI-powered test case generation, optimization, and self-healing tests are making testing more efficient and effective.
• Visual Testing: Explore the emerging capabilities of AI in visual testing and how it's set to revolutionize UI verification.
• Inflectra's AI Solutions: See demonstrations of Inflectra's cutting-edge AI tools like the ChatGPT plugin and Azure Open AI platform, designed to streamline your testing process.
Whether you're a developer, tester, or QA professional, this webinar will give you valuable insights into how AI is shaping the future of software delivery.
Connector Corner: Automate dynamic content and events by pushing a buttonDianaGray10
Here is something new! In our next Connector Corner webinar, we will demonstrate how you can use a single workflow to:
Create a campaign using Mailchimp with merge tags/fields
Send an interactive Slack channel message (using buttons)
Have the message received by managers and peers along with a test email for review
But there’s more:
In a second workflow supporting the same use case, you’ll see:
Your campaign sent to target colleagues for approval
If the “Approve” button is clicked, a Jira/Zendesk ticket is created for the marketing design team
But—if the “Reject” button is pushed, colleagues will be alerted via Slack message
Join us to learn more about this new, human-in-the-loop capability, brought to you by Integration Service connectors.
And...
Speakers:
Akshay Agnihotri, Product Manager
Charlie Greenberg, Host
Dev Dives: Train smarter, not harder – active learning and UiPath LLMs for do...UiPathCommunity
💥 Speed, accuracy, and scaling – discover the superpowers of GenAI in action with UiPath Document Understanding and Communications Mining™:
See how to accelerate model training and optimize model performance with active learning
Learn about the latest enhancements to out-of-the-box document processing – with little to no training required
Get an exclusive demo of the new family of UiPath LLMs – GenAI models specialized for processing different types of documents and messages
This is a hands-on session specifically designed for automation developers and AI enthusiasts seeking to enhance their knowledge in leveraging the latest intelligent document processing capabilities offered by UiPath.
Speakers:
👨🏫 Andras Palfi, Senior Product Manager, UiPath
👩🏫 Lenka Dulovicova, Product Program Manager, UiPath
Essentials of Automations: Optimizing FME Workflows with ParametersSafe Software
Are you looking to streamline your workflows and boost your projects’ efficiency? Do you find yourself searching for ways to add flexibility and control over your FME workflows? If so, you’re in the right place.
Join us for an insightful dive into the world of FME parameters, a critical element in optimizing workflow efficiency. This webinar marks the beginning of our three-part “Essentials of Automation” series. This first webinar is designed to equip you with the knowledge and skills to utilize parameters effectively: enhancing the flexibility, maintainability, and user control of your FME projects.
Here’s what you’ll gain:
- Essentials of FME Parameters: Understand the pivotal role of parameters, including Reader/Writer, Transformer, User, and FME Flow categories. Discover how they are the key to unlocking automation and optimization within your workflows.
- Practical Applications in FME Form: Delve into key user parameter types including choice, connections, and file URLs. Allow users to control how a workflow runs, making your workflows more reusable. Learn to import values and deliver the best user experience for your workflows while enhancing accuracy.
- Optimization Strategies in FME Flow: Explore the creation and strategic deployment of parameters in FME Flow, including the use of deployment and geometry parameters, to maximize workflow efficiency.
- Pro Tips for Success: Gain insights on parameterizing connections and leveraging new features like Conditional Visibility for clarity and simplicity.
We’ll wrap up with a glimpse into future webinars, followed by a Q&A session to address your specific questions surrounding this topic.
Don’t miss this opportunity to elevate your FME expertise and drive your projects to new heights of efficiency.
Neuro-symbolic is not enough, we need neuro-*semantic*Frank van Harmelen
Neuro-symbolic (NeSy) AI is on the rise. However, simply machine learning on just any symbolic structure is not sufficient to really harvest the gains of NeSy. These will only be gained when the symbolic structures have an actual semantics. I give an operational definition of semantics as “predictable inference”.
All of this illustrated with link prediction over knowledge graphs, but the argument is general.
UiPath Test Automation using UiPath Test Suite series, part 3DianaGray10
Welcome to UiPath Test Automation using UiPath Test Suite series part 3. In this session, we will cover desktop automation along with UI automation.
Topics covered:
UI automation Introduction,
UI automation Sample
Desktop automation flow
Pradeep Chinnala, Senior Consultant Automation Developer @WonderBotz and UiPath MVP
Deepak Rai, Automation Practice Lead, Boundaryless Group and UiPath MVP
Builder.ai Founder Sachin Dev Duggal's Strategic Approach to Create an Innova...Ramesh Iyer
In today's fast-changing business world, Companies that adapt and embrace new ideas often need help to keep up with the competition. However, fostering a culture of innovation takes much work. It takes vision, leadership and willingness to take risks in the right proportion. Sachin Dev Duggal, co-founder of Builder.ai, has perfected the art of this balance, creating a company culture where creativity and growth are nurtured at each stage.
AI for Every Business: Unlocking Your Product's Universal Potential by VP of ...
Rubric
1. file:///C:/Documents%20and%20Settings/staff.000/My%20Documents/...
Lab Report : What is the effect of salt or detergent on the polarity of water?
Teacher Name: Ms. Parker
Student Name: ________________________________________
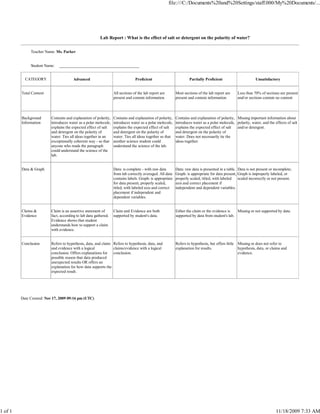
CATEGORY Advanced Proficient Partially Proficient Unsatisfactory
Total Content All sections of the lab report are Most sections of the lab report are Less than 70% of sections are present
present and contain information present and contain information and/or sections contain no content
Background Contains and explanation of polarity, Contains and explanation of polarity, Contains and explanation of polarity, Missing important information about
Information introduces water as a polar molecule, introduces water as a polar molecule, introduces water as a polar molecule, polarity, water, and the effects of salt
explains the expected effect of salt explains the expected effect of salt explains the expected effect of salt and/or detergent.
and detergent on the polarity of and detergent on the polarity of and detergent on the polarity of
water. Ties all ideas together in an water. Ties all ideas together so that water. Does not necessarily tie the
exceptionally coherent way - so that another science student could ideas together.
anyone who reads the paragraph understand the science of the lab.
could understand the science of the
lab.
Data & Graph Data: is complete - with raw data Data: raw data is presented in a table. Data is not present or incomplete;
from lab correctly averaged. All data Graph: is appropriate for data present, Graph is improperly labeled, or
contains labels. Graph: is appropriate properly scaled, titled, with labeled scaled incorrectly or not present.
for data present, properly scaled, axis and correct placement if
titled, with labeled axis and correct independent and dependent variables.
placement if independent and
dependent variables.
Claims & Claim is an assertive statement of Claim and Evidence are both Either the claim or the evidence is Missing or not supported by data.
Evidence fact, according to lab data gathered. supported by student's data. supported by data from student's lab.
Evidence shows that student
understands how to support a claim
with evidence.
Conclusion Refers to hypothesis, data, and claim Refers to hypothesis, data, and Refers to hypothesis, but offers little Missing or does not refer to
and evidence with a logical claims/evidence with a logical explanation for results. hypothesis, data, or claims and
conclusion. Offers explanations for conclusion. evidence.
possible reason that data produced
unexpected results OR offers an
explanation for how data supports the
expected result.
Date Created: Nov 17, 2009 09:16 pm (UTC)
1 of 1 11/18/2009 7:33 AM