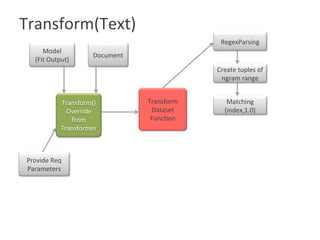
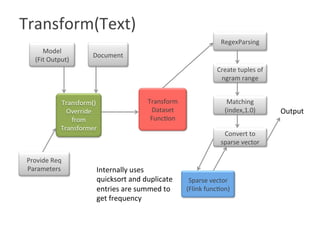
The document describes implementing a CountVectorizer in Apache Flink. CountVectorizer is a class in scikit-learn that transforms documents into feature vectors based on word frequency. The key functionality implemented includes fit(), which counts word frequencies, transform(), which transforms new documents, and get_feature_names(). Parameters like minDF, maxDF, stopwords and n-grams are also supported. Tests show the outputs match scikit-learn CountVectorizer. Sample applications include document similarity and word clouds.



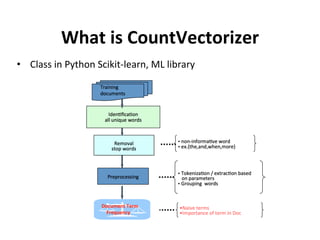
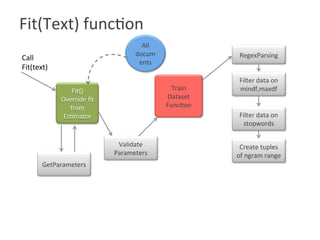
![Functionality Implemented
• fit() (Es?mator) :
[“this is a text”,
“this is not a text
document to
document”]
Output of fit
(this,1) (is,2) (a,3)
(text,4) (not,5)
(document,6) (to,
7)](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-4-320.jpg)
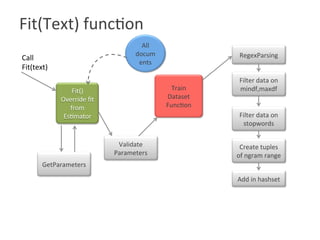
![Functionality Implemented
• transform() (Transformer) :
• get_feature_names() :
Output
(this,1) (is,2) (a,3)
(text,4) (not,5)
(document,6) (to,
7)
[“this is a text”,
“this is not a text
document to
document”]
Output of Transform
[(1,1.0) (2,1.0) (3,1.0)
(4,1.0)]
[(1,1.0) (2,1.0) (5,1.0)
(3,1.0) (4,1.0) (6,2.0)
(7,1.0)]](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-5-320.jpg)
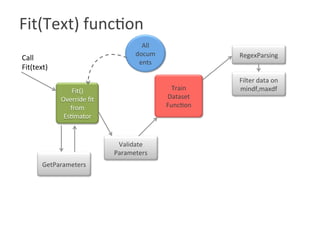
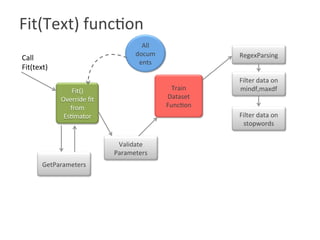
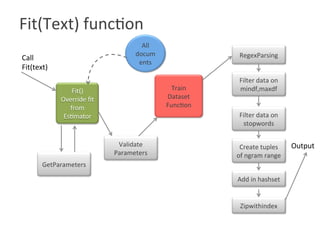
![Functionality Implemented
• Parameters added to countVectorizer() constructor
-> setMinDF(2), setMaxDF(5)
Mindf =2 The sun in the sky is bright. We can see the shining sun, the bright sun
Maxdf = 5 The sun in the sky is bright. We can see the shining sun, the bright sun
-> setStopwords (List([“in”,”the”] ))
The sun in the sky is bright. We can see the shining sun, the bright sun](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-6-320.jpg)


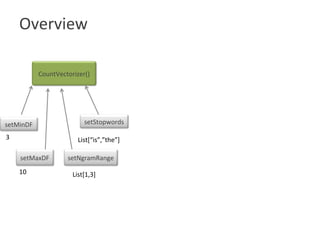
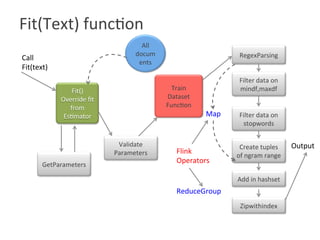
![Overview
CountVectorizer()
setStopwords setMinDF
setMaxDF setNgramRange
3
10
List[“is”,”the”]
List[1,3]](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-10-320.jpg)
![Overview
CountVectorizer() Fit()
Input
Data
files
setStopwords setMinDF
setMaxDF setNgramRange
[“this is a text”,
“this is not a text
document to
document”] 3
10
List[“is”,”the”]
List[1,3]
Output of fit
(this,1) (is,2) (a,3)
(text,4) (not,5)
(document,6) (to,7)](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-11-320.jpg)
![Overview
CountVectorizer() Fit()
Transform
Input
Data
files
setStopwords
setMinDF
setMaxDF setNgramRange
Output of fit
(this,1) (is,2) (a,3)
(text,4) (not,5)
(document,6) (to,7)
[“this is a text”,
“this is not a text
document to
document”] Output of Transform
[(1,1.0) (2,1.0) (3,1.0)
(4,1.0)]
[(1,1.0) (2,1.0) (5,1.0)
(3,1.0) (4,1.0) (6,2.0)
(7,1.0)]
3
10
List[“is”,”the”]
List[1,3]](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-12-320.jpg)
![Overview
CountVectorizer() Fit()
Transform
Input
Data
files
setStopwords
setMinDF
setMaxDF setNgramRange
getFeature
Names
Output of fit
(this,1) (is,2) (a,3)
(text,4) (not,5)
(document,6) (to,7)
[“this is a text”,
“this is not a text
document to
document”] Output of Transform
[(1,1.0) (2,1.0) (3,1.0)
(4,1.0)]
[(1,1.0) (2,1.0) (5,1.0)
(3,1.0) (4,1.0) (6,2.0)
(7,1.0)]
3
10
List[“is”,”the”]
List[1,3]](https://image.slidesharecdn.com/roshaninagmoteweek4demo-160628054257/85/CountVectorizer_ApacheFlink-13-320.jpg)


























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










