Downloaded 27 times




![7 | © Copyright Zilliz
7
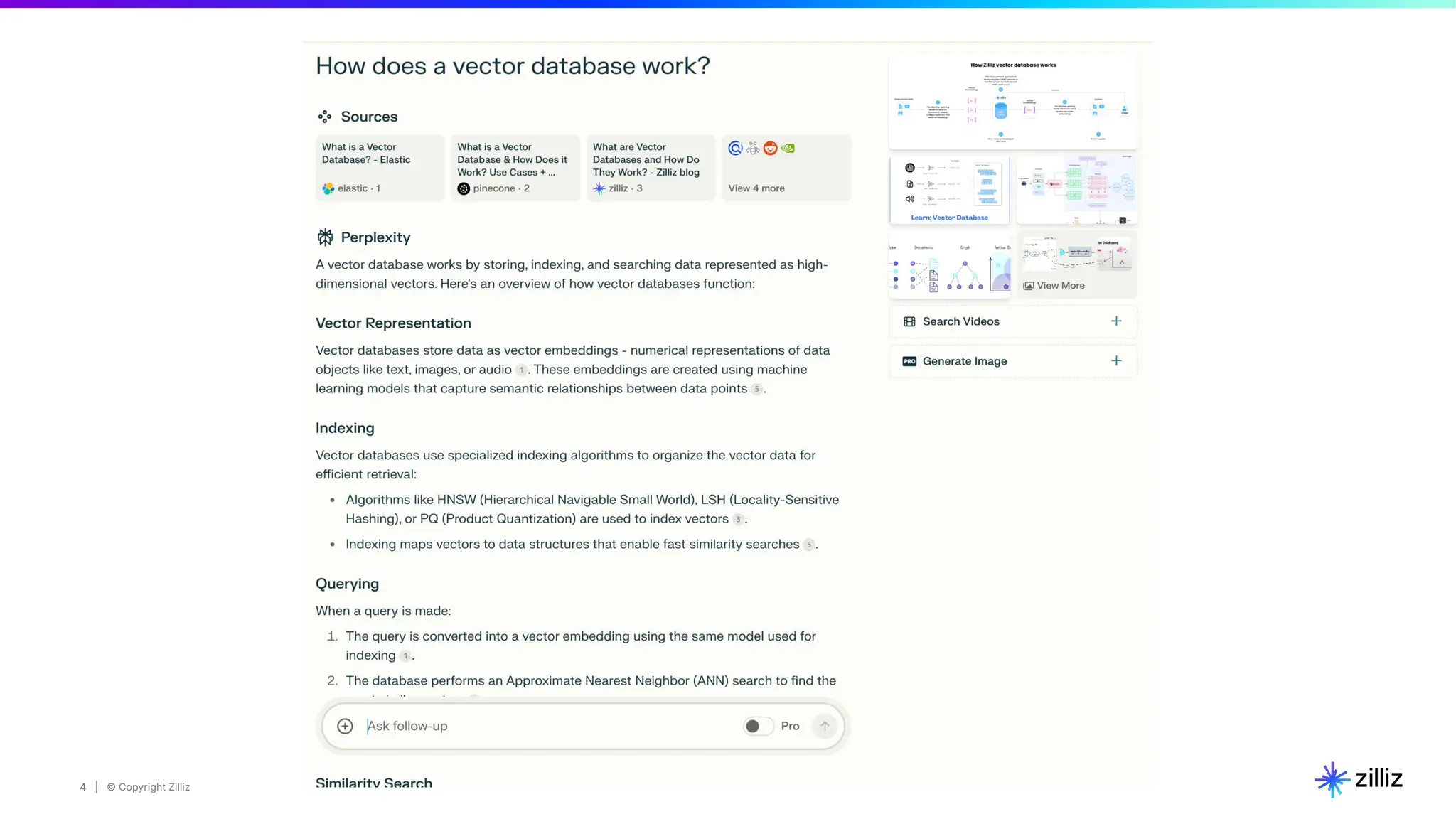
RAG Pipeline Options
Credit: https://github.com/langchain-ai/rag-from-scratch]](https://image.slidesharecdn.com/2024-11-07-webinar-buildingaprincipledragpipeline-stefanwebb1-241107191205-eabf0e0a/75/Evaluating-Retrieval-Augmented-Generation-Webinar-7-2048.jpg)
![8 | © Copyright Zilliz
8
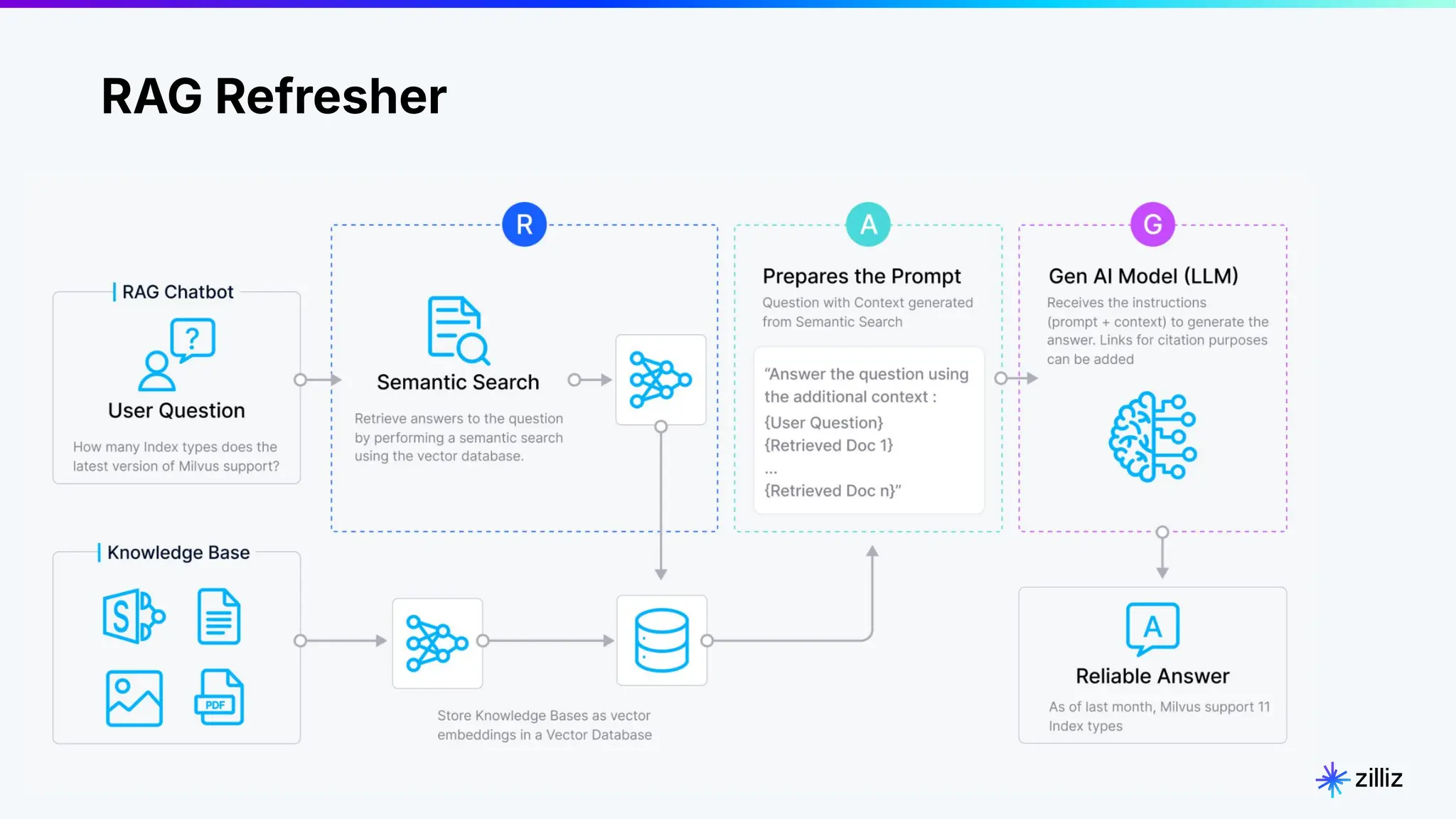
RAG Pipeline Options
Credit: Gao et al., 2024]](https://image.slidesharecdn.com/2024-11-07-webinar-buildingaprincipledragpipeline-stefanwebb1-241107191205-eabf0e0a/75/Evaluating-Retrieval-Augmented-Generation-Webinar-8-2048.jpg)



















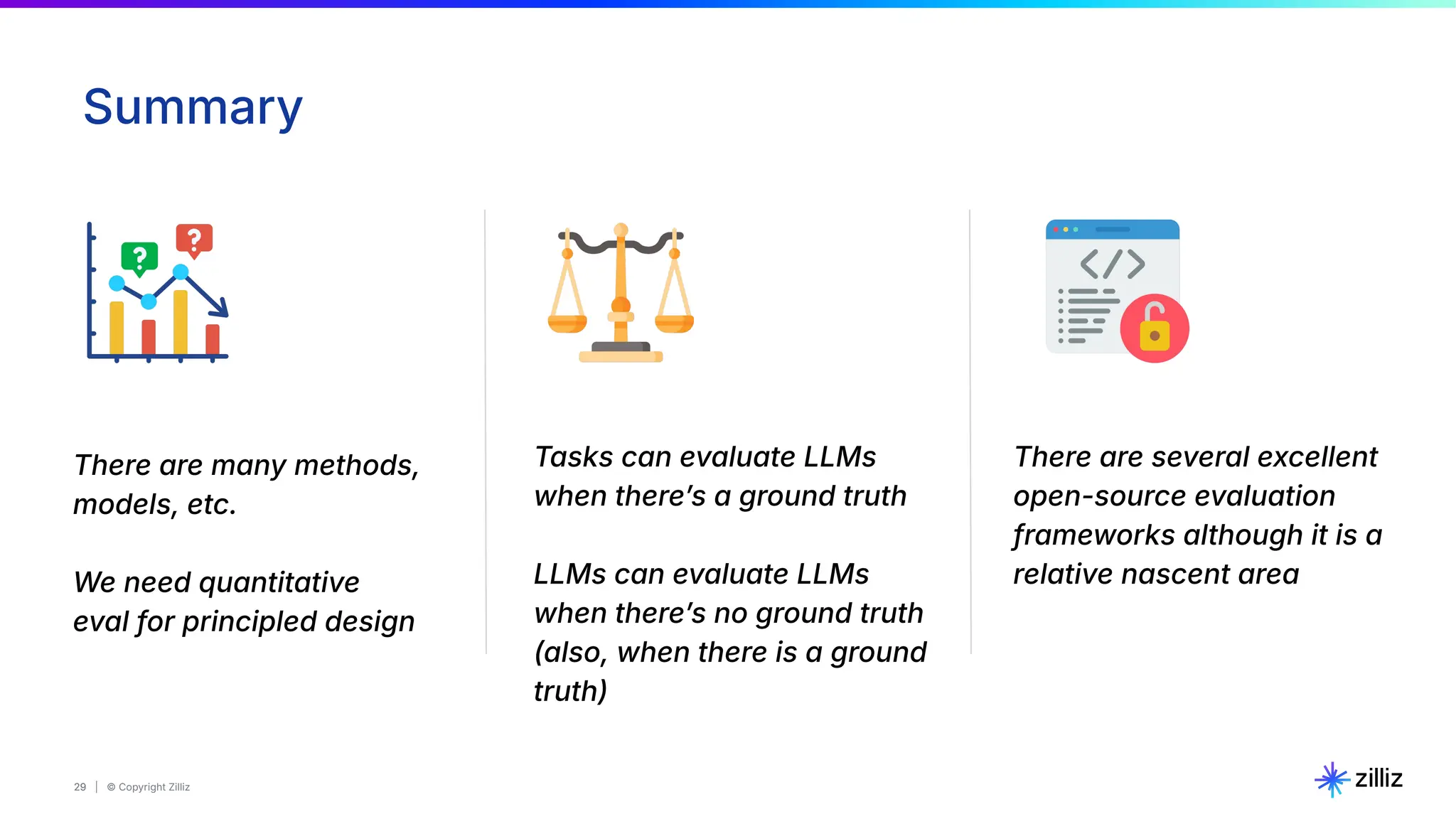





The document discusses the evaluation of foundation models, highlighting challenges, limitations, and various methods of assessment such as task-based and introspection-based evaluations. It emphasizes the importance of understanding biases and the necessity for quantitative evaluation strategies while mentioning the availability of open-source frameworks for better evaluation. Additionally, it introduces Milvus, an open-source vector database aimed at enhancing generative AI projects.



















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














