Download to read offline





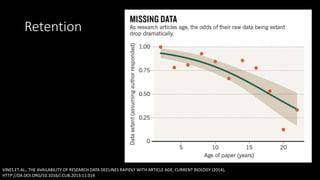

















The document discusses the complexities of digital preservation and data curation, highlighting the importance of effective data management in maintaining usable research data over time. It emphasizes the need for proper formatting, adequate resources, and early engagement in the data curation process. The presentation is shared under a Creative Commons license, with links to relevant sources and images provided.

































































