Downloaded 13 times





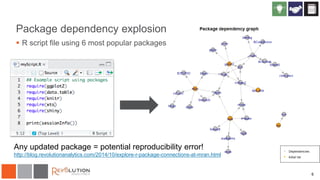










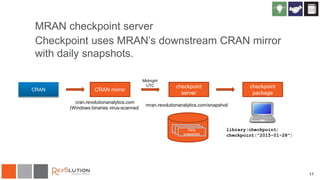










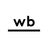
The document discusses reproducibility in R research and analytics, emphasizing the need for tying instructions to data analysis for better verification and understanding. It introduces the 'checkpoint' package, which allows users to maintain specific package versions to ensure reproducible results across different environments. The presentation also highlights the importance of managing package dependencies and shares strategies for using R in a consistent and reliable manner.































































































