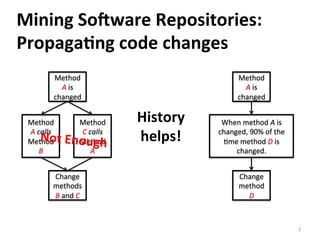
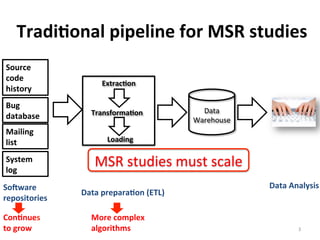
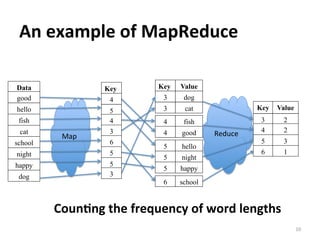
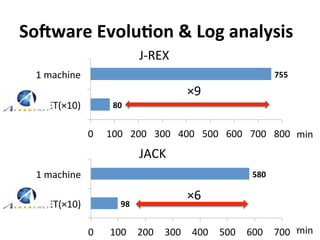
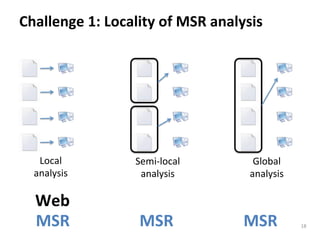
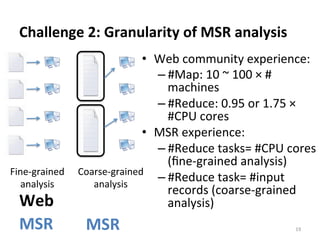
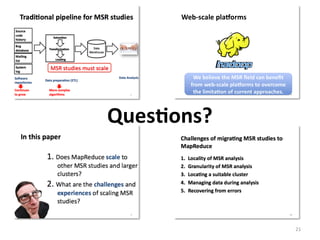
This document reports on scaling tools for mining software repositories (MSR) studies using MapReduce. It finds that MapReduce can effectively scale three large MSR studies - a software evolution study, code clone detection, and log analysis - to larger datasets and clusters of up to 28 machines. The main challenges in migrating MSR studies to MapReduce are the locality and granularity of the analysis, locating a suitable cluster, managing large datasets, and handling errors.