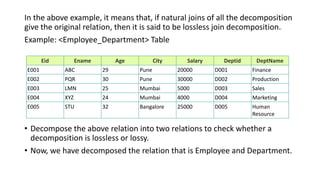
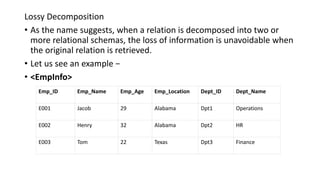
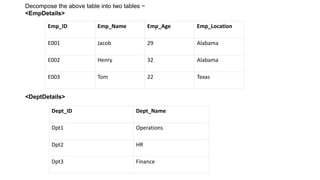
The document provides an introduction to relational database design and concepts. It discusses how relational databases organize data in tables made up of rows and columns. It also discusses functional dependencies, which specify relationships between attributes, and how relational decomposition breaks tables into multiple tables to eliminate problems from bad design like anomalies and redundancy. Decomposition must be lossless, preserve dependencies, and eliminate data redundancy.

















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)















