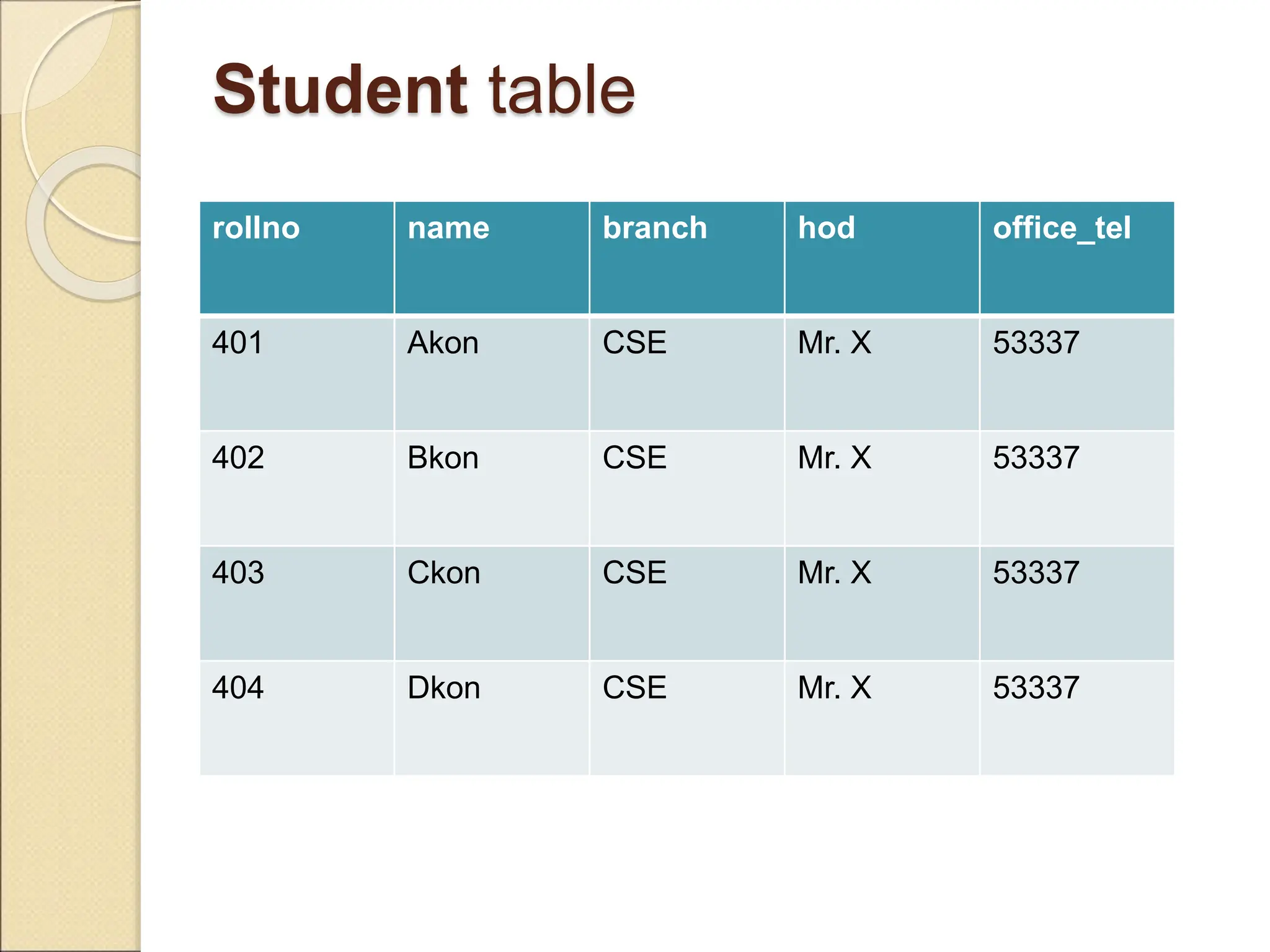
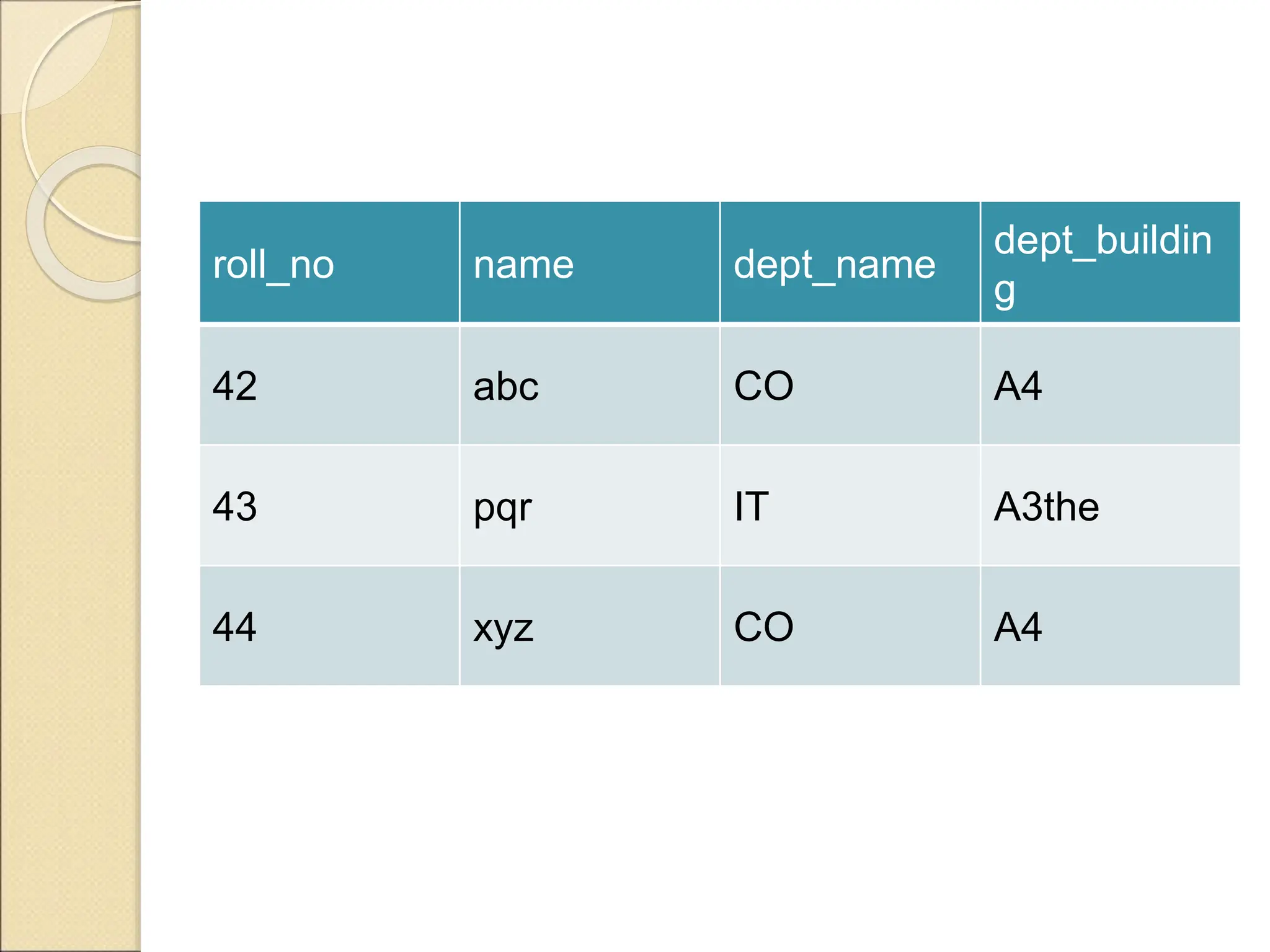
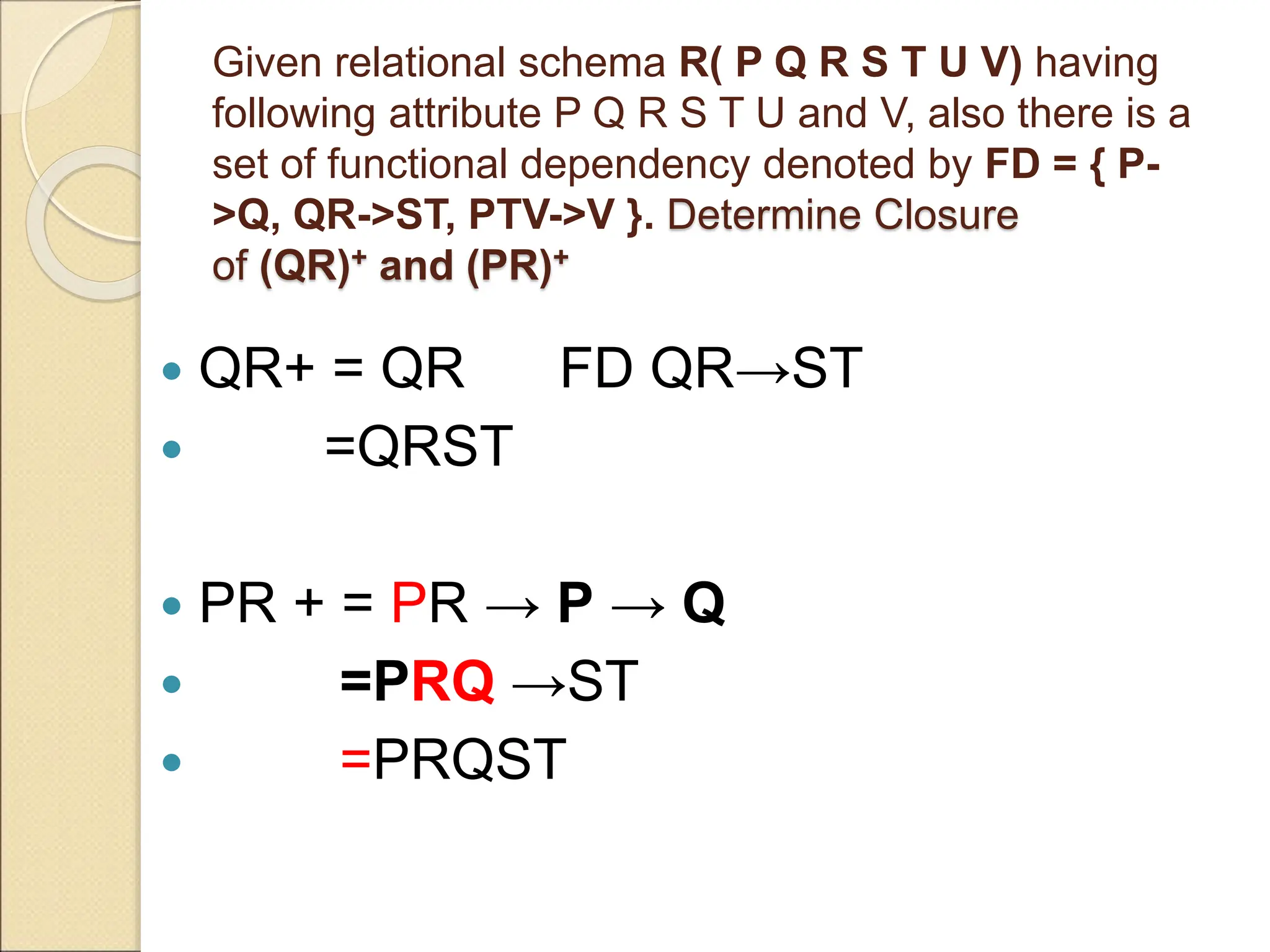
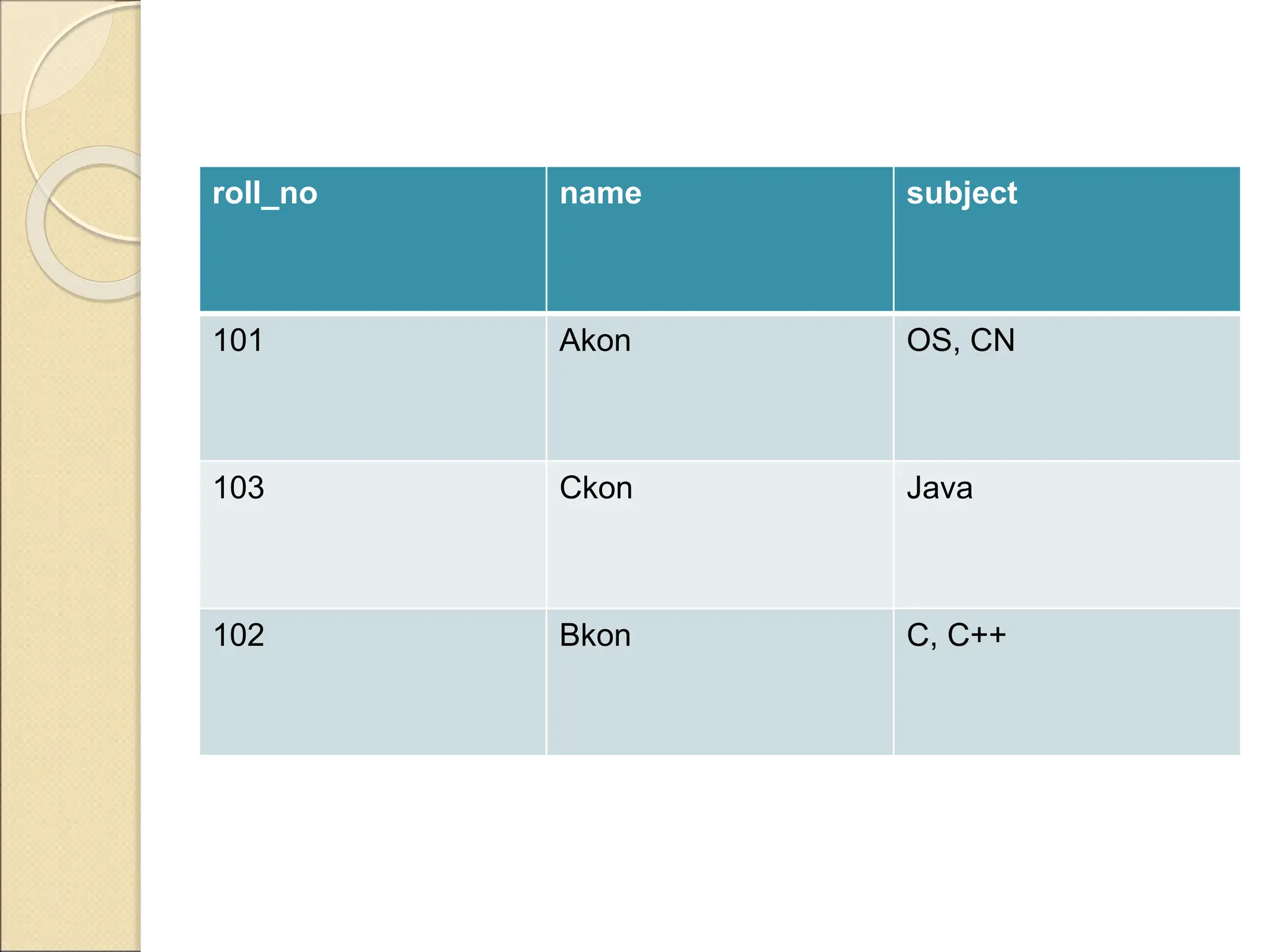
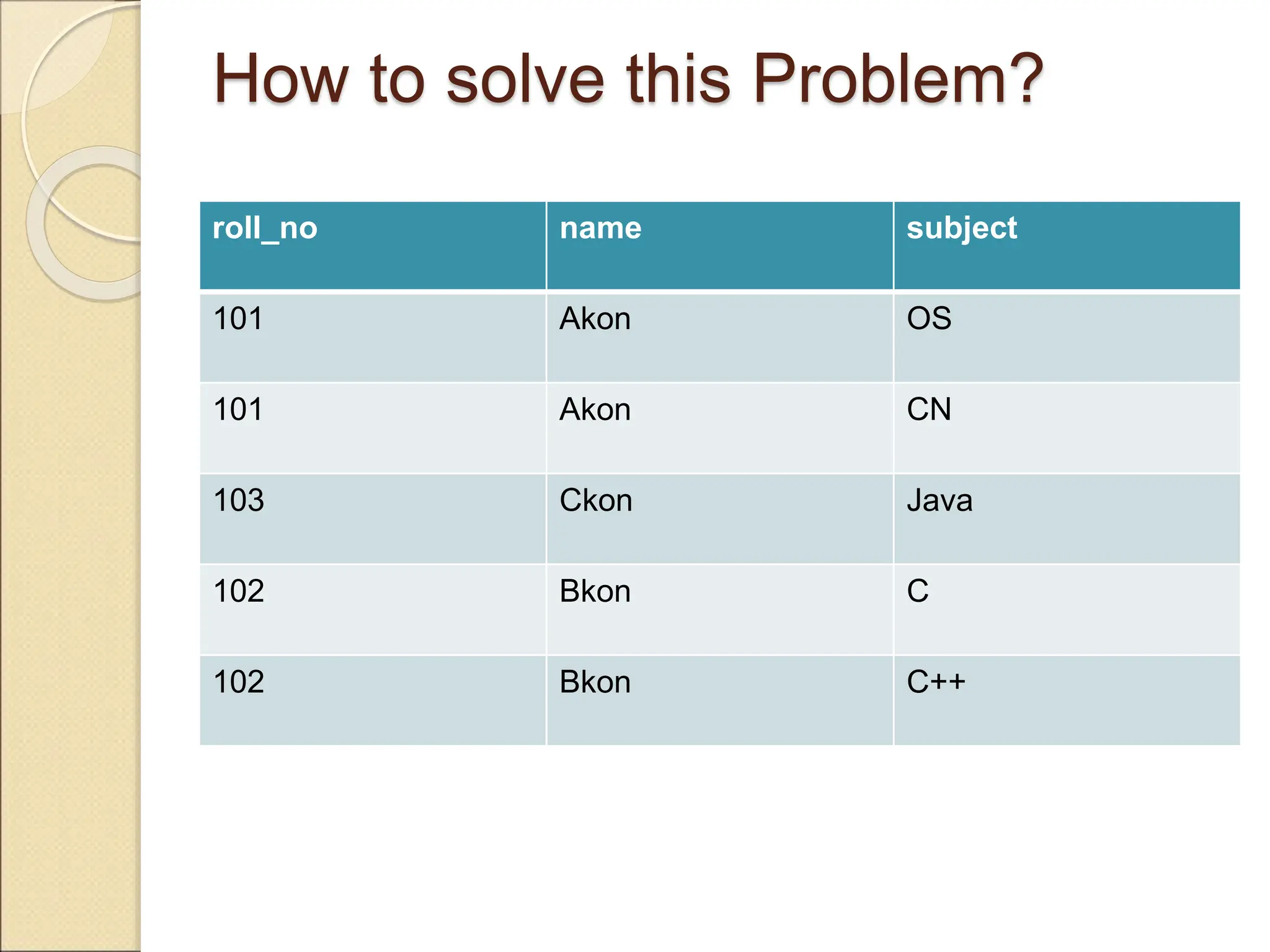
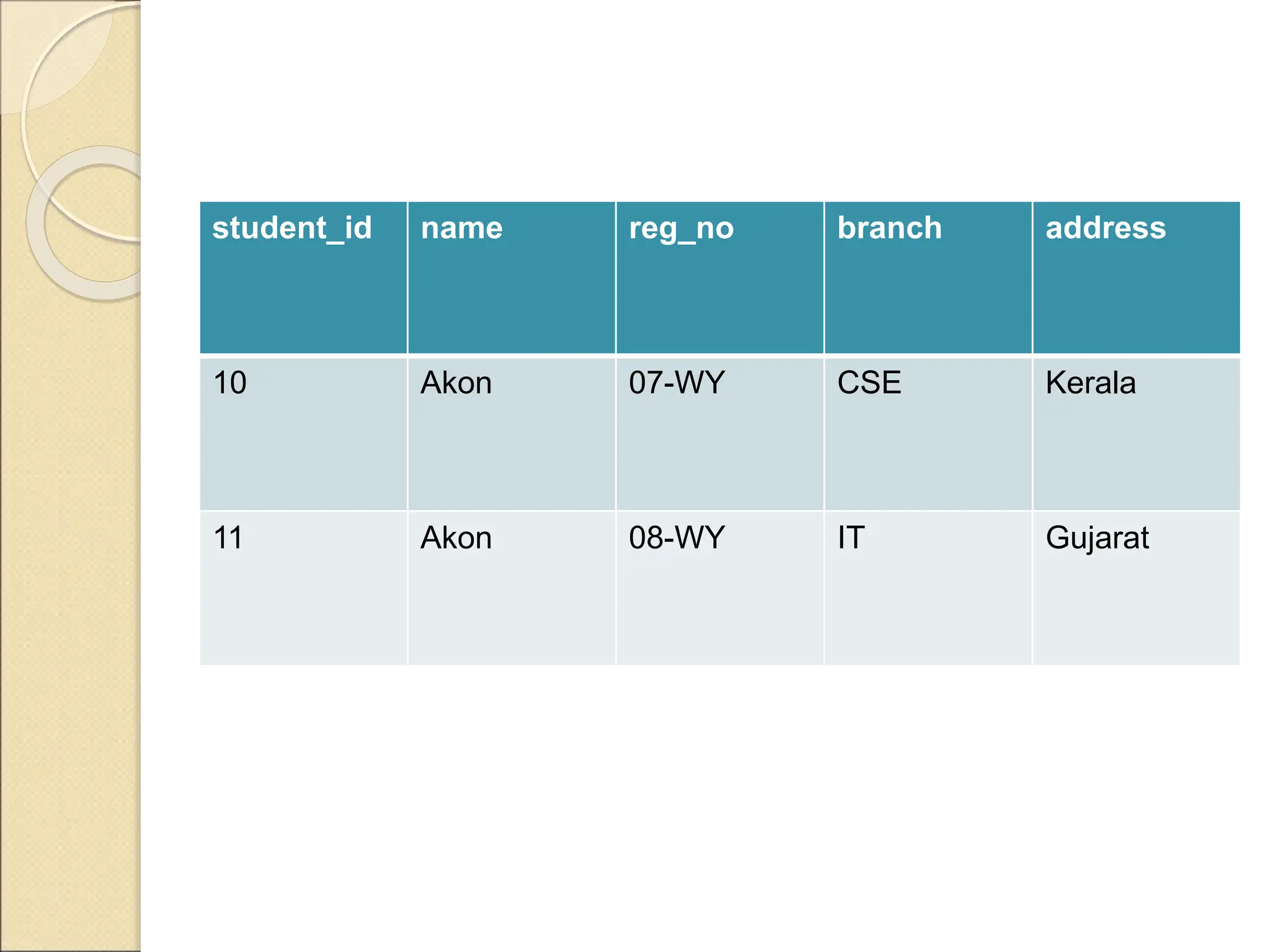
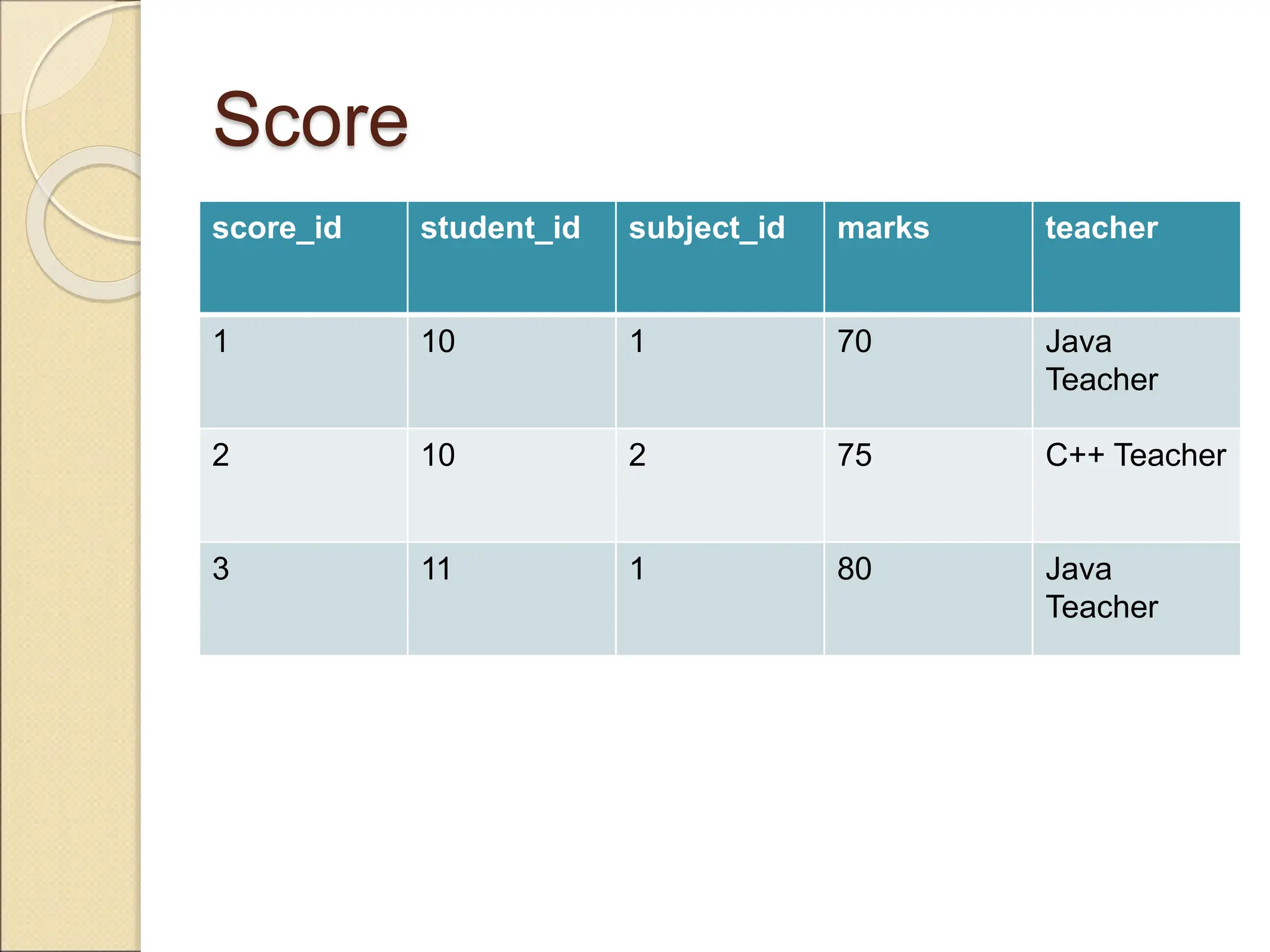
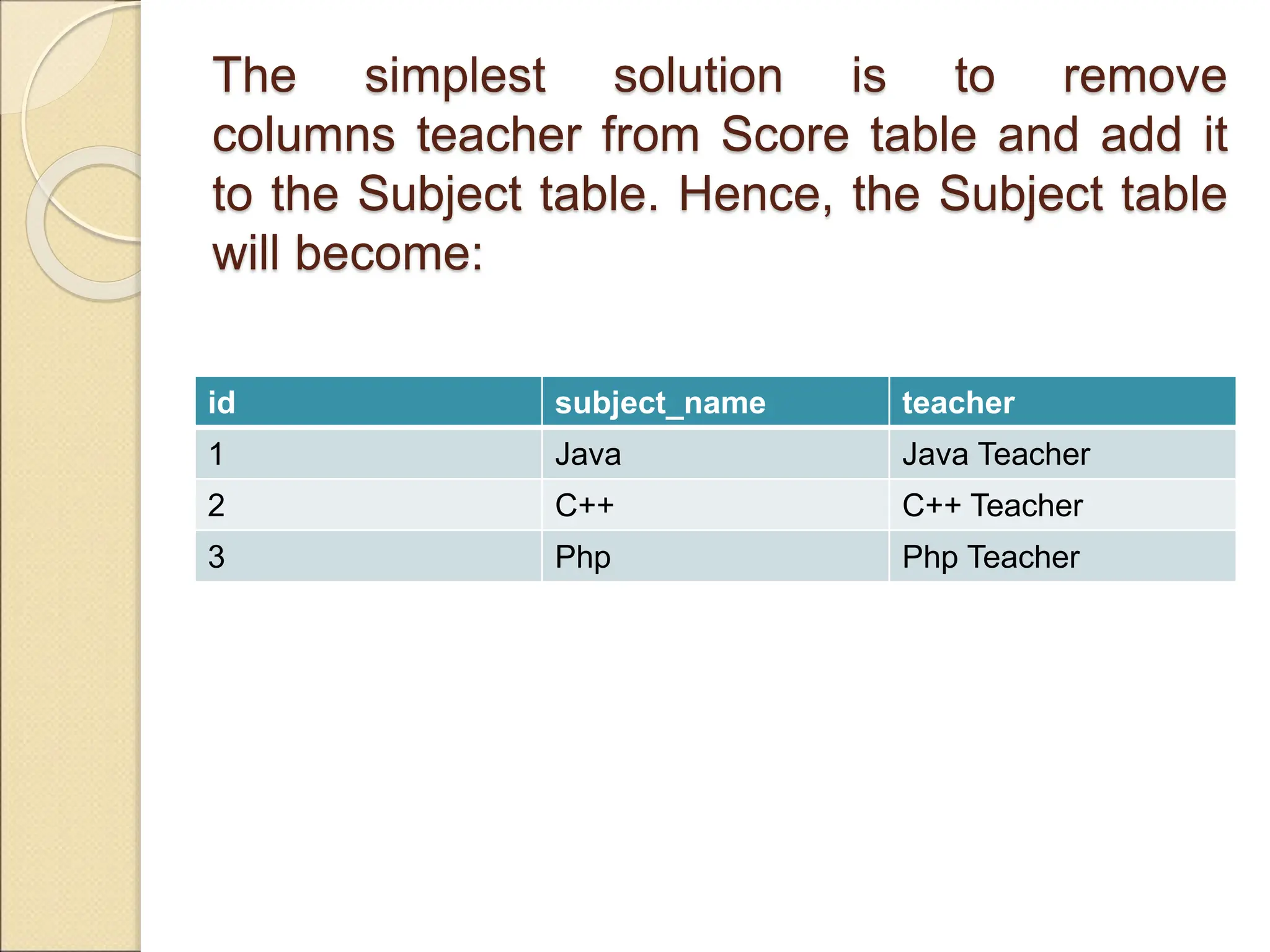
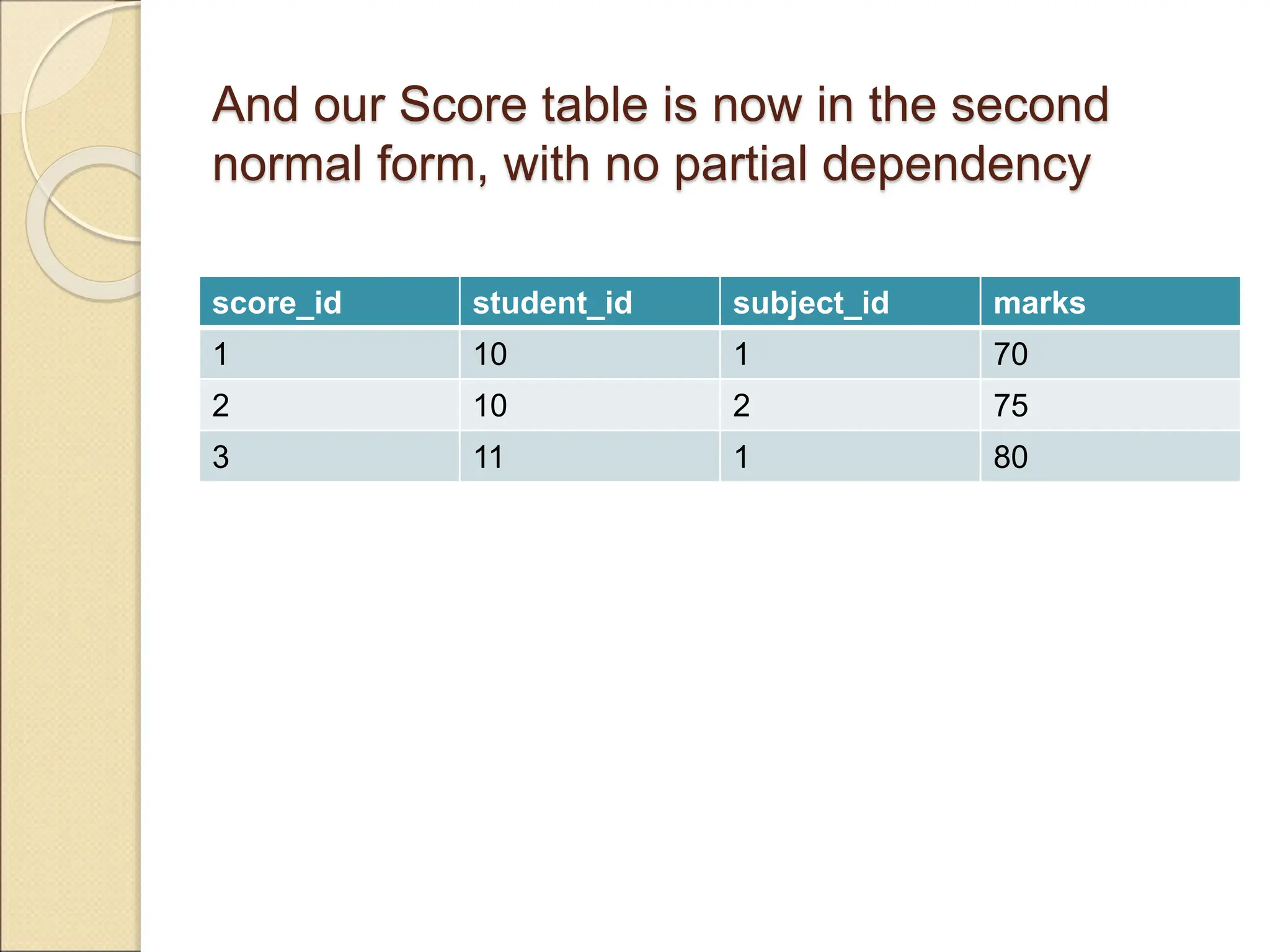
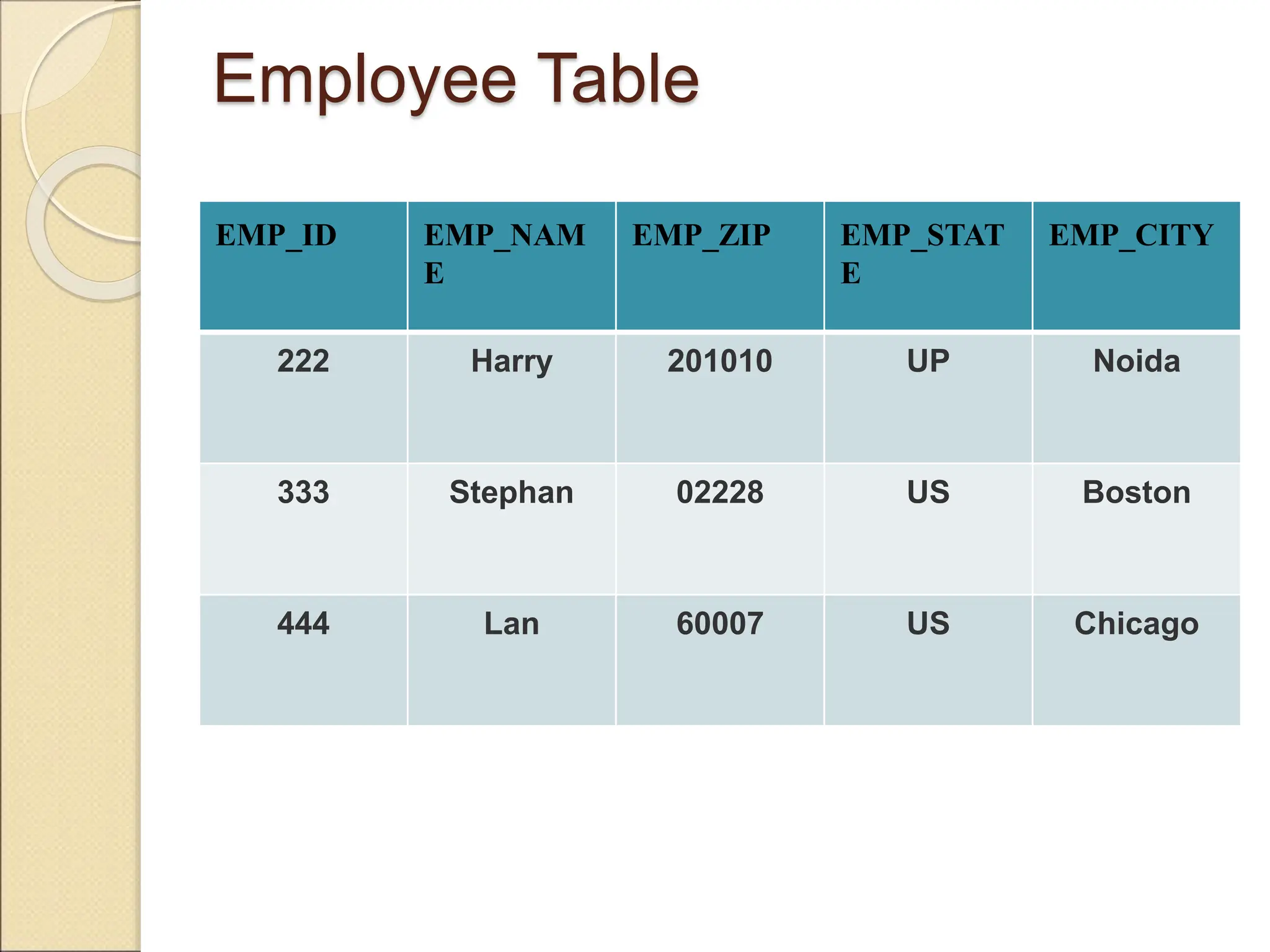
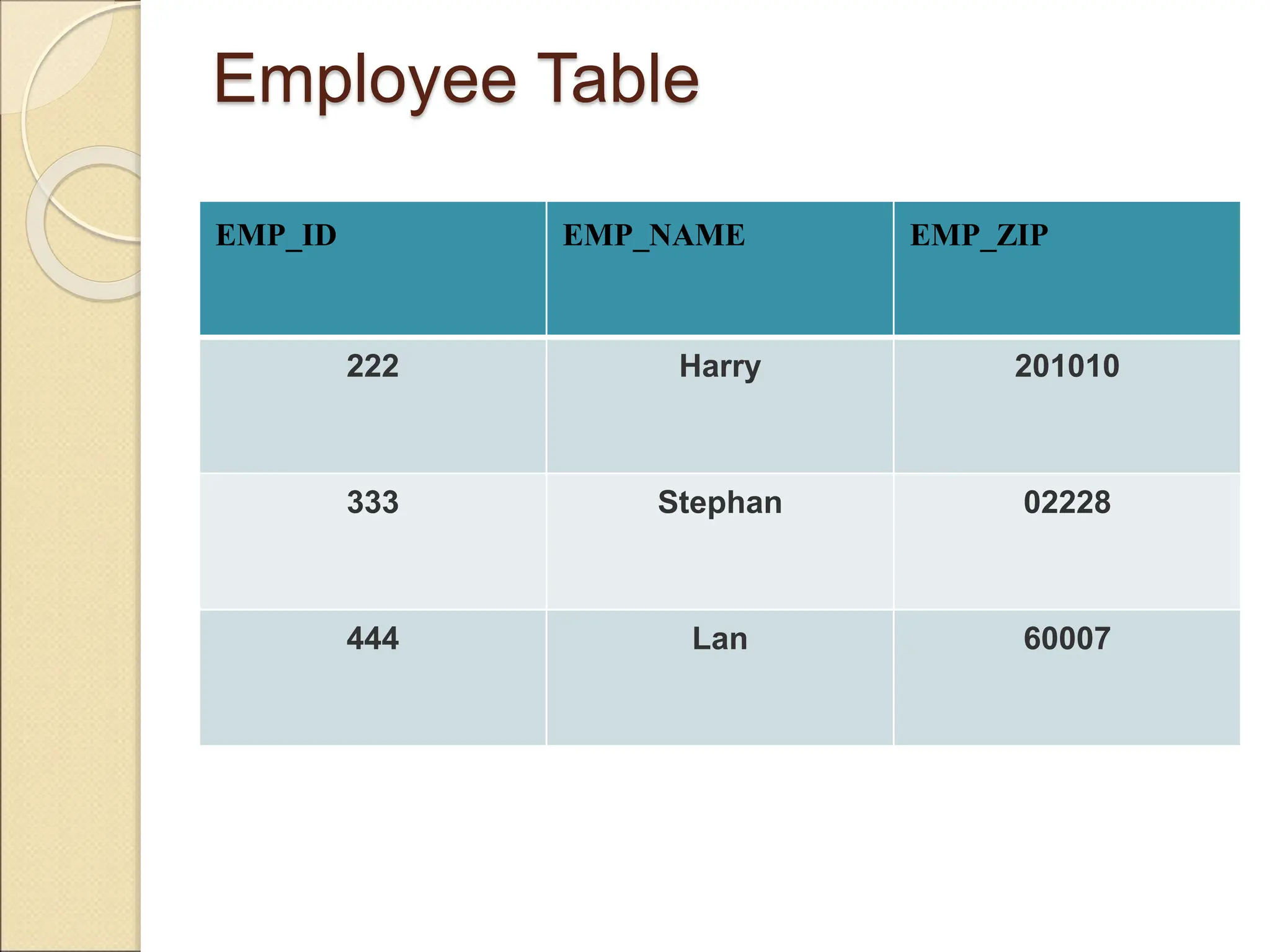
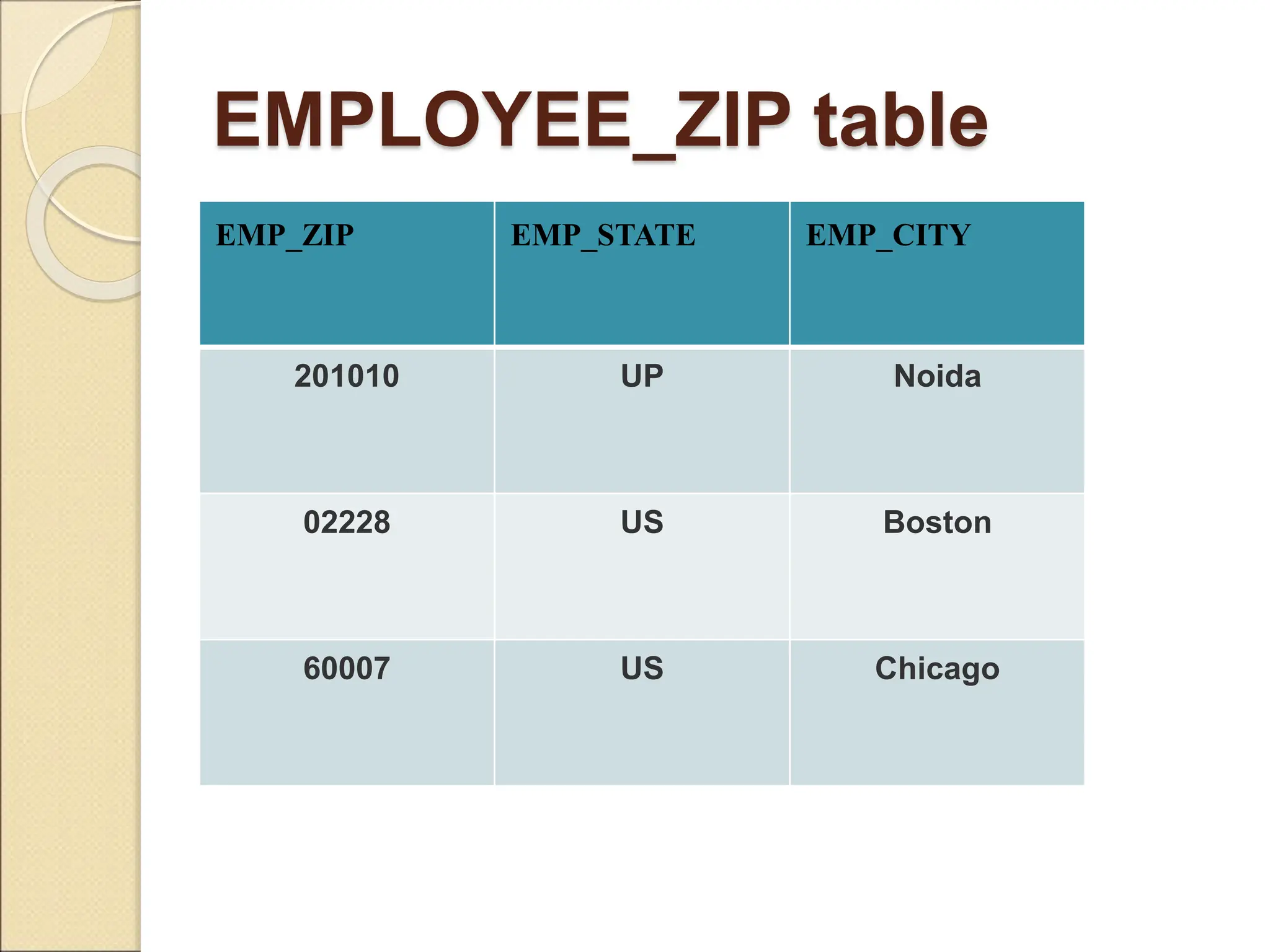
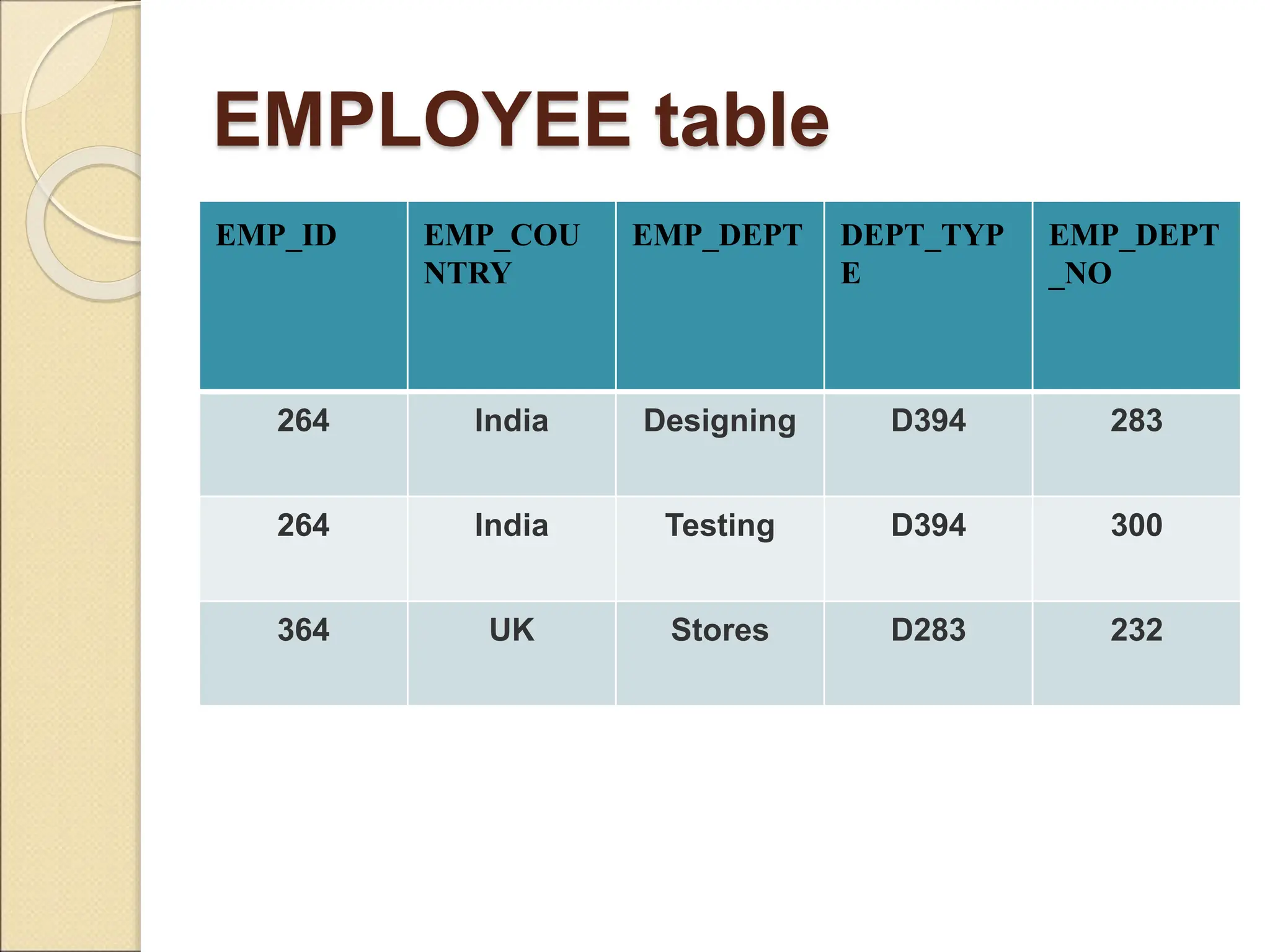
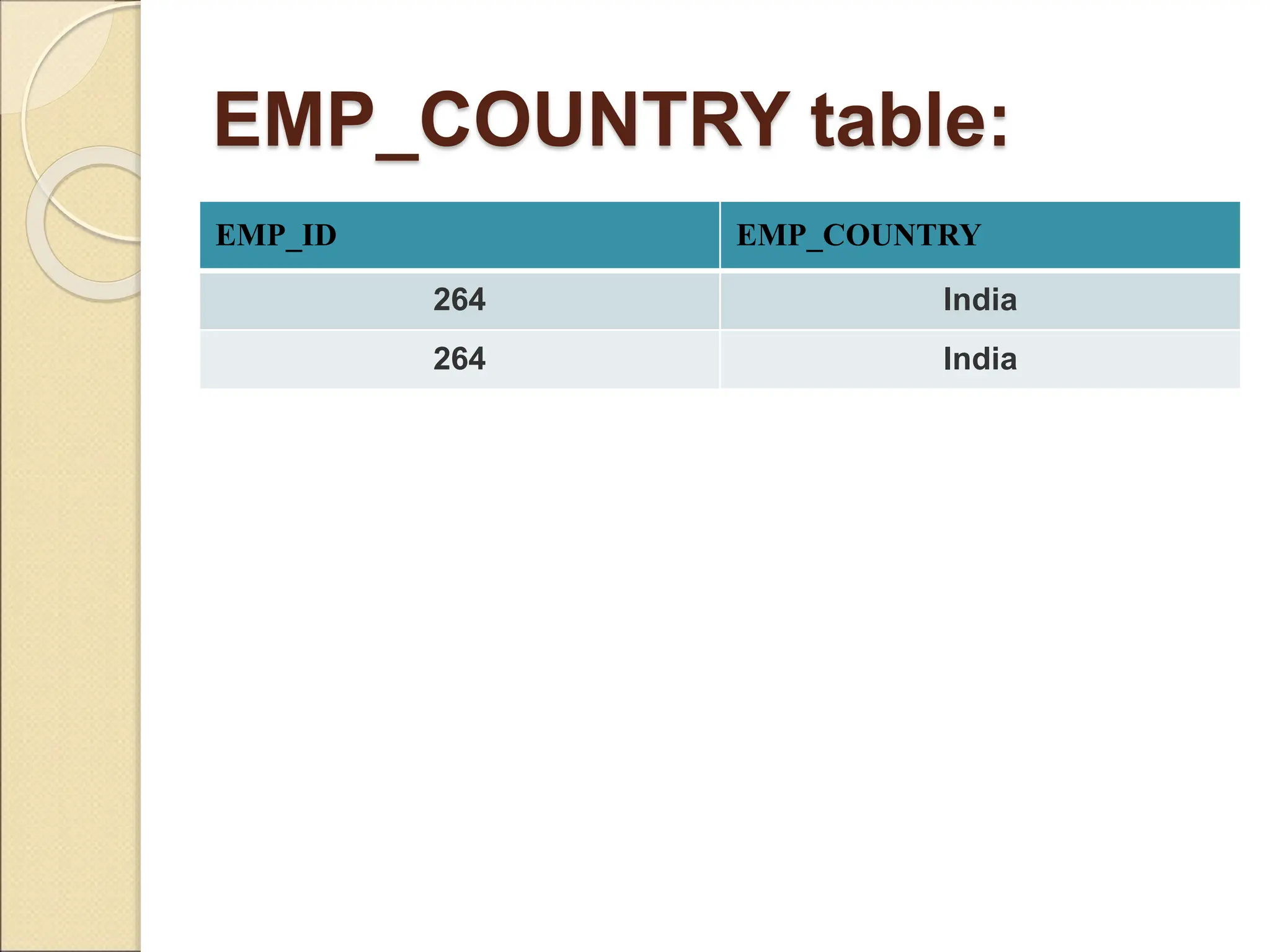
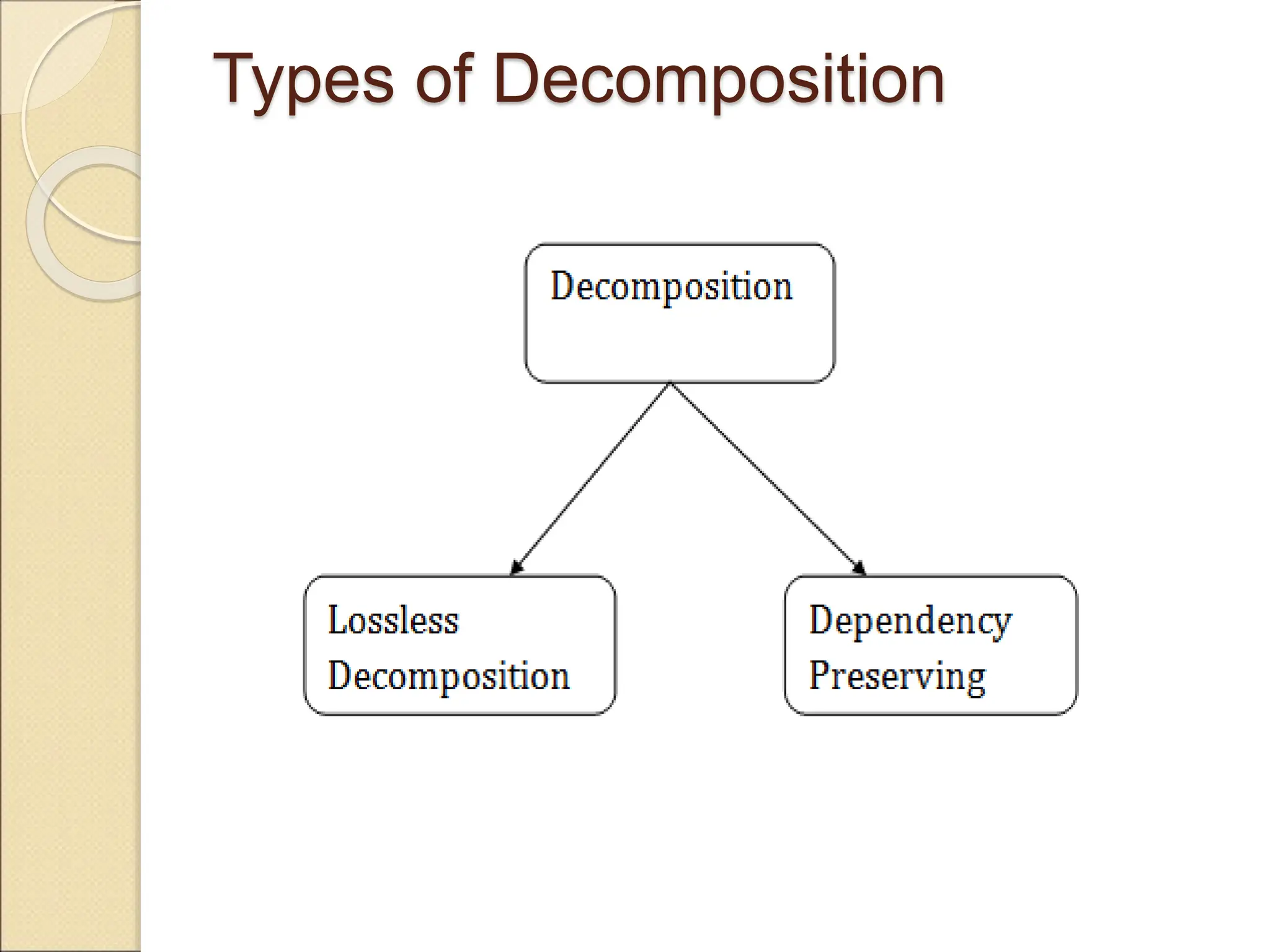
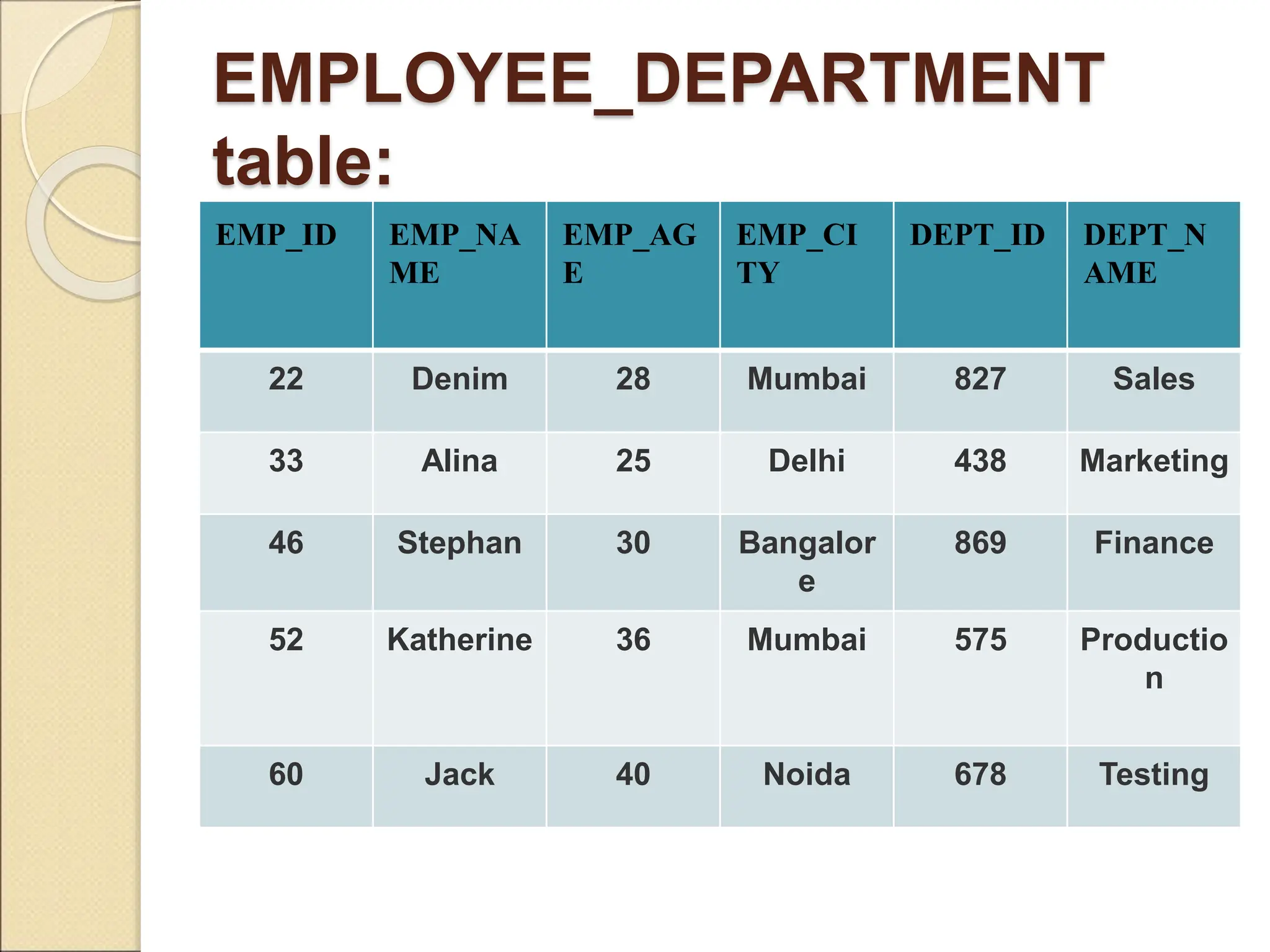
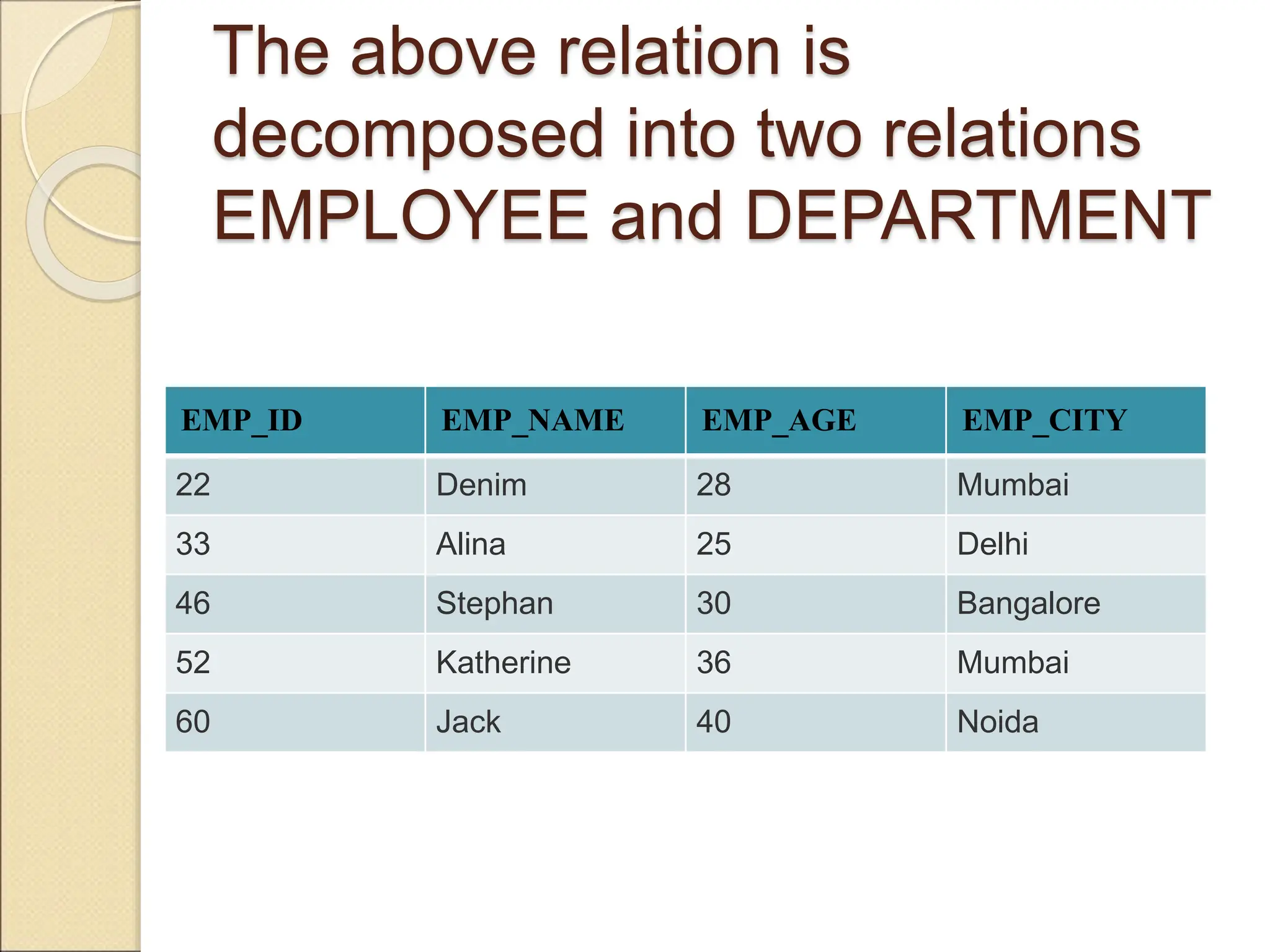
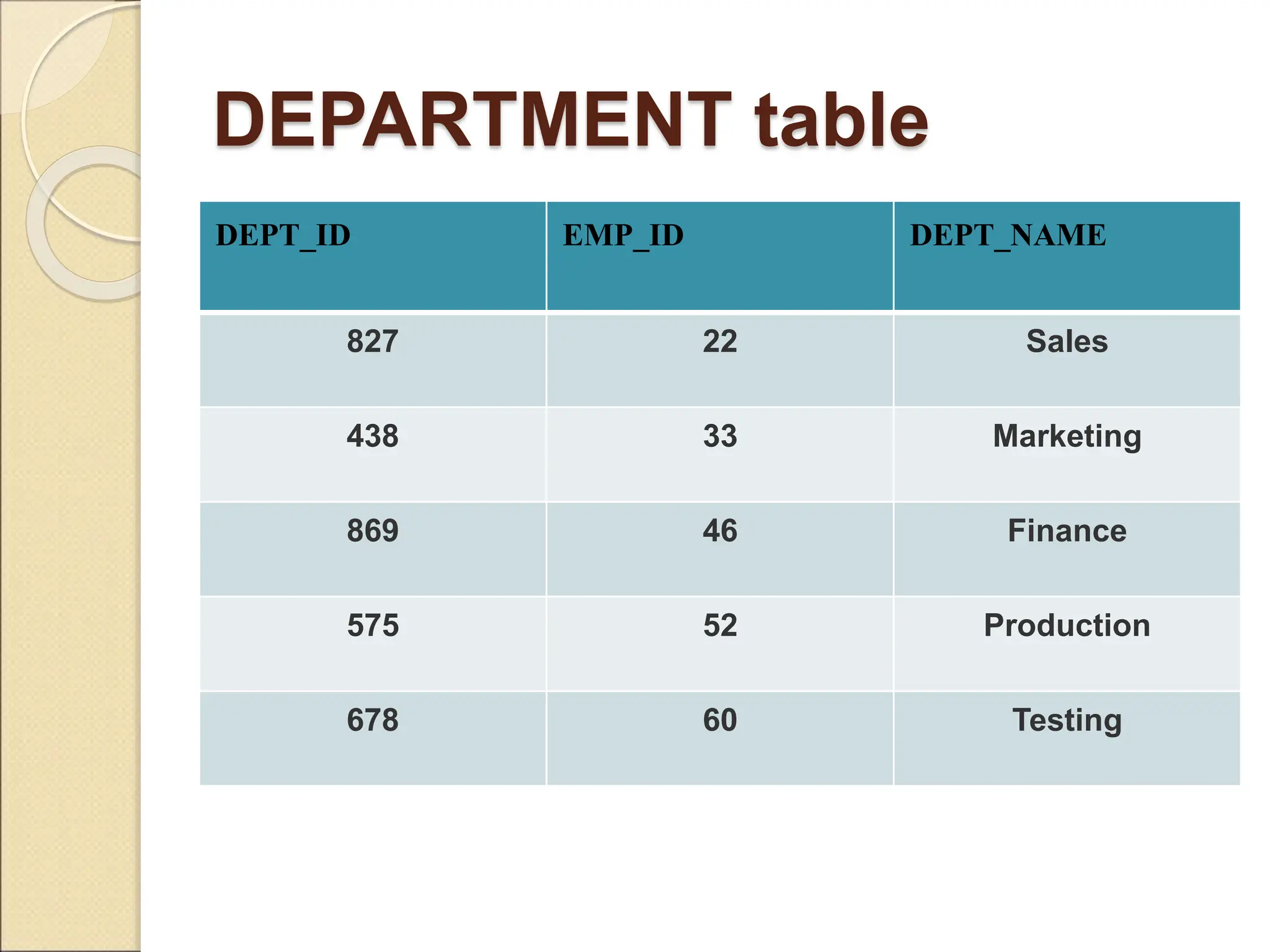
The document discusses schema refinement and normalization in databases. It defines schema refinement as a technique to refine the database schema by avoiding redundancy through decomposition. Normalization is introduced as a systematic process to organize data by eliminating anomalies like insertion, update, and deletion anomalies. The document covers different types of dependencies like functional, transitive, and multivalued dependencies that exist in databases. It also explains different normal forms like 1NF, 2NF and BCNF that are used to normalize relations and eliminate redundancy.






























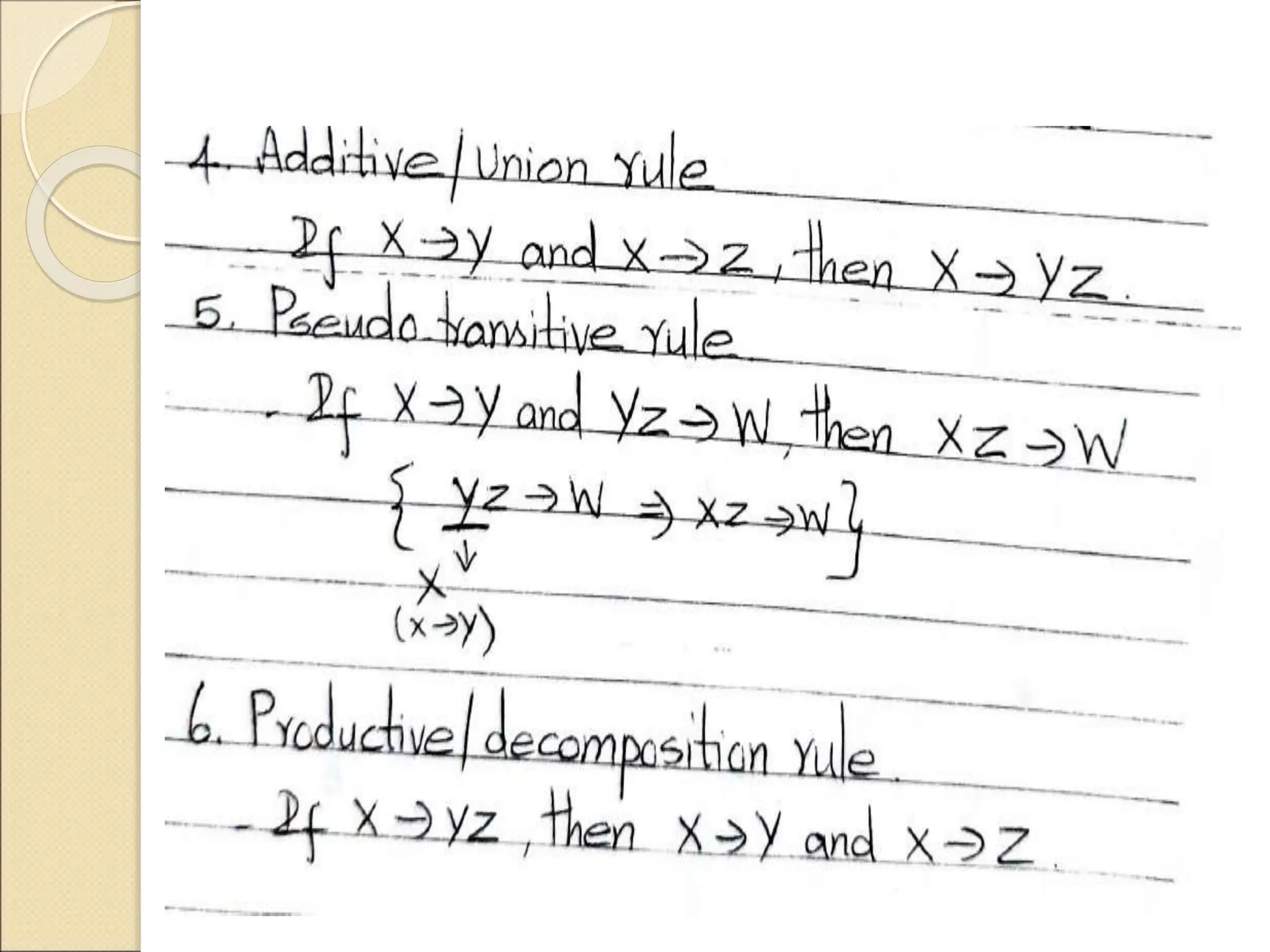
























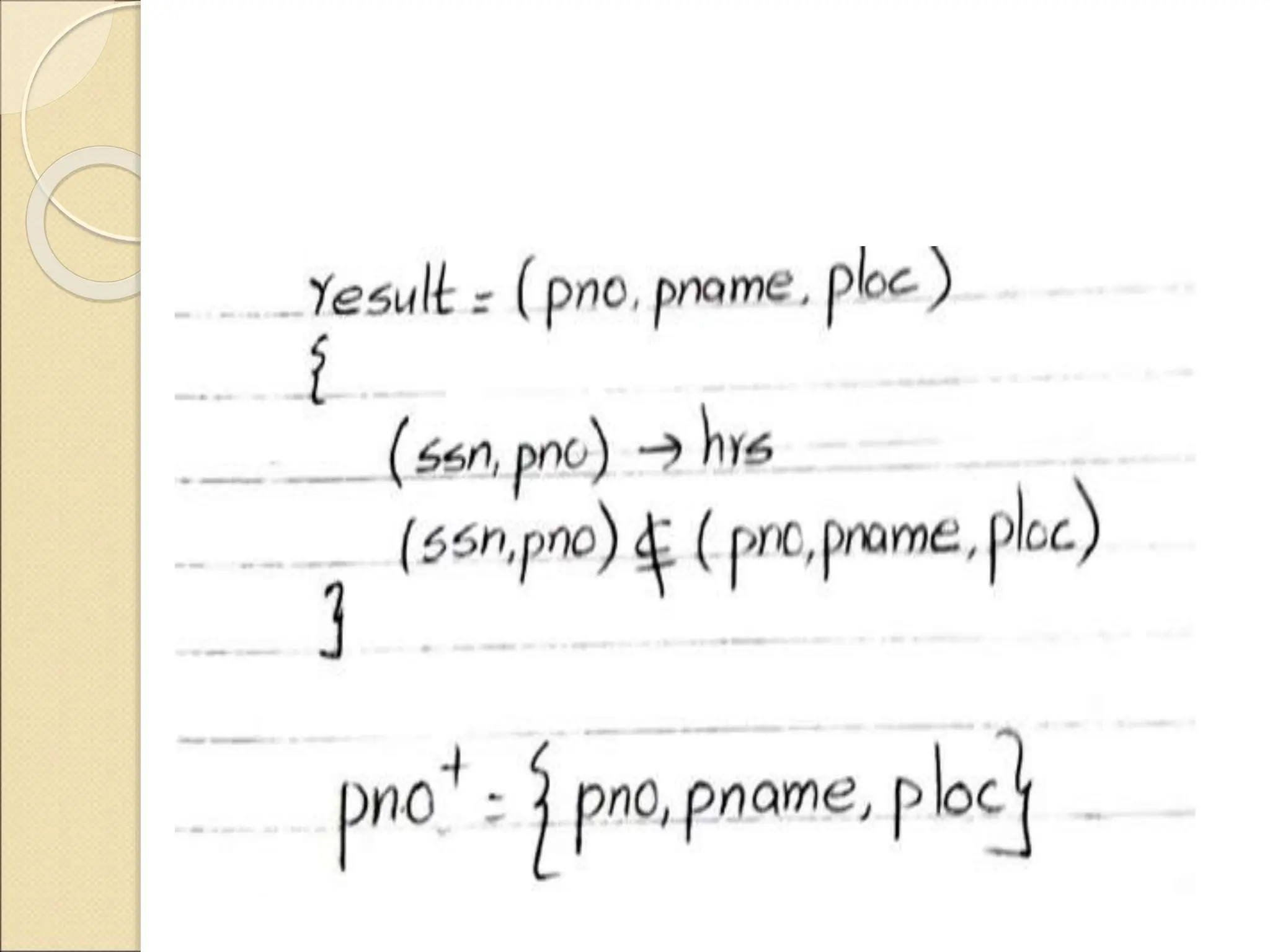































































![Big Data Mining Methods in Medical Applications [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataminingmethodsinmedicalapplicationsautosaved-240128114133-60b647d6-thumbnail.jpg?width=640&height=640&fit=bounds)































