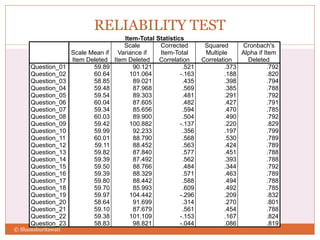
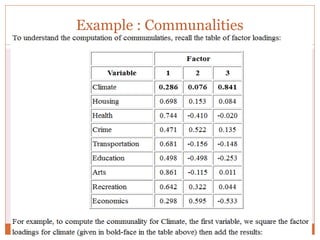
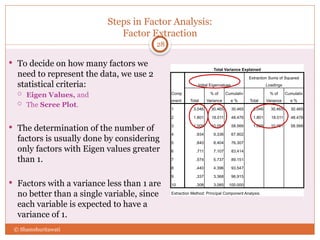
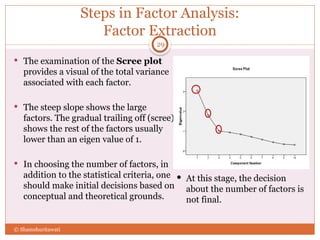
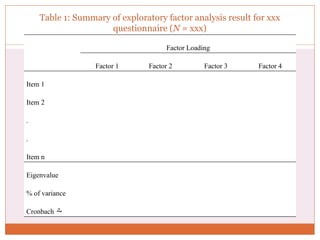
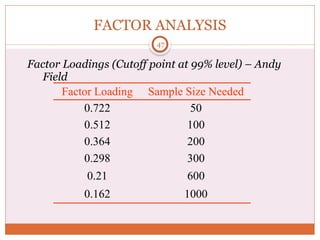
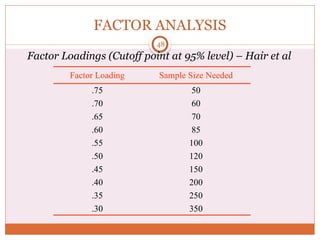
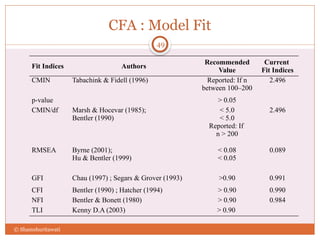
The document discusses reliability analysis with a focus on Cronbach's alpha, which is used as a measure of internal consistency for a set of items, indicating reliability when the value is 0.7 or higher. It also covers the application of factor analysis for data reduction and scale development, providing steps for conducting the analysis such as correlation matrix computation, factor extraction, and rotation methods. The document emphasizes the importance of adequate sample size and inter-item correlations in ensuring the validity of the measures.

























































































![literature_review Important._ppt[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/literaturereviewppt1-240929123747-6f591137-thumbnail.jpg?width=640&height=640&fit=bounds)



















