



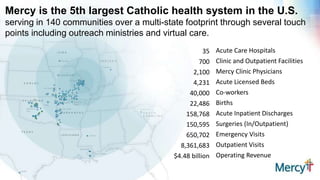




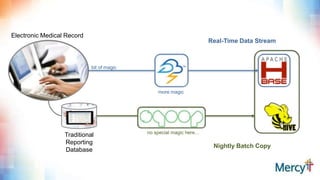
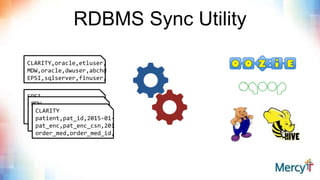
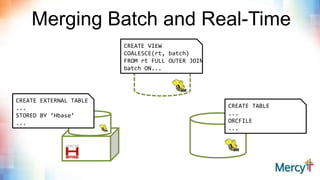










This document discusses real-time clinical analytics at Mercy, a large Catholic health system. It describes how Mercy is using Hadoop to process real-time data streams and merge them with batch data to enable near real-time updates and faster analytics. This allows them to reuse existing SQL skills and data models while gaining the benefits of real-time data. Potential use cases mentioned include free-text search on lab results, inventory archiving, medical documentation improvement, and EMR auditing.










































































































