Download as PDF, PPTX









![Apache Big Data North America | Vancouver | 05.05.2016 | Johannes Weigend | © QAware GmbH
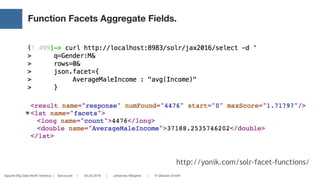
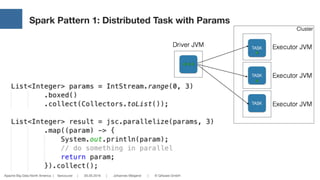
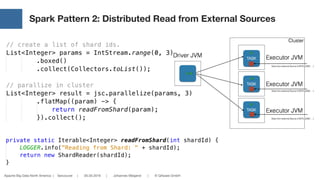
Solr Stores Everything in a Single „Table“ (BigTable).
Searching is Extremely Fast and Powerful.*
Customer Order
*1
Name Amount
Address Product
Type ID Name Address Amount Product K2B
Customer 1 K 1 A 1 - - [3,5]
Customer 2 K 2 A 2 - - [4]
Order 3 - - Z 1 P 1 [1]
Order 4 - - Z 2 P 2 [2]
...
SolrDocument
SolrDocument
SolrDocument
SolrDocument
(*) With 100 million documents per shard, runtimes of queries and aggregations are normally less then 100ms](https://image.slidesharecdn.com/real-worldanalyticswithsolrcloudandspark-160517124552/85/Real-World-Analytics-with-Solr-Cloud-and-Spark-16-320.jpg)
















![Apache Big Data North America | Vancouver | 05.05.2016 | Johannes Weigend | © QAware GmbH
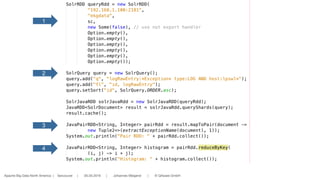
Logfile Analytics with Solr and Spark
■Histogram of all exception from hosts A,B,C during time
interval D
■Step 1: Search with Solr
■Solr Query (q=*Exception AND (server: A OR server:B OR server:C) AND timestamp
between [1.1.2015, 31.12.2015]
■Step 2: Create a map with key = << exception name >>, value =
count
■Group with Spark](https://image.slidesharecdn.com/real-worldanalyticswithsolrcloudandspark-160517124552/85/Real-World-Analytics-with-Solr-Cloud-and-Spark-41-320.jpg)


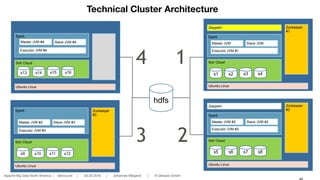







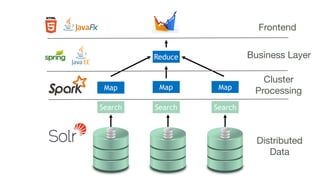
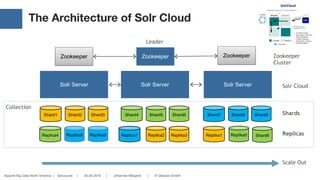
The document discusses the integration of Solr Cloud and Apache Spark for handling large-scale analytical problems effectively, emphasizing the need for interactive applications with sub-second response times. It highlights the challenges of horizontal scalability and distributed data processing, offering insights into Solr's capabilities for data searching and indexing along with Spark's rapid distributed computing. Additionally, the document provides technical details and examples, demonstrating how this combination can be utilized for various data-intensive applications.











































































































