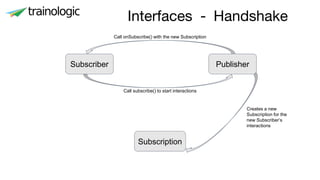
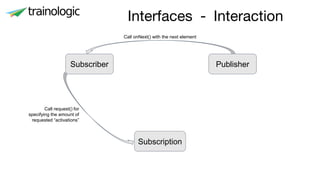
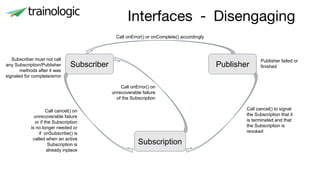
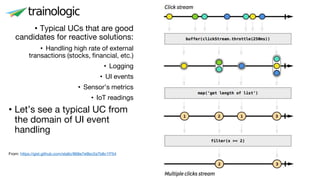
This document discusses reactive programming concepts using Java 9 and Spring Reactor. It introduces reactive streams interfaces in Java 9 like Publisher, Subscriber, and Subscription. It then covers Spring Reactor implementations of these interfaces using Mono and Flux. Code examples are provided for creating simple reactive streams and combining them using operators. The threading model and use of schedulers in Spring Reactor is also briefly explained.






















































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















