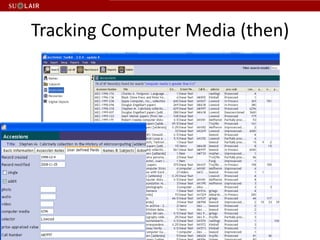
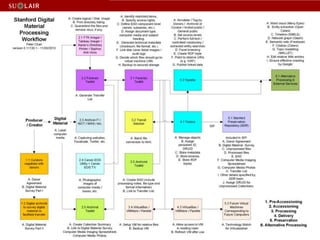
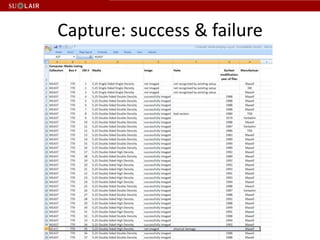
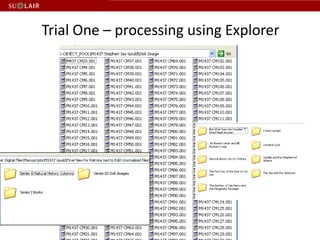
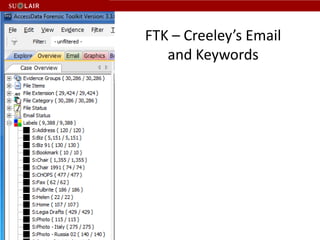
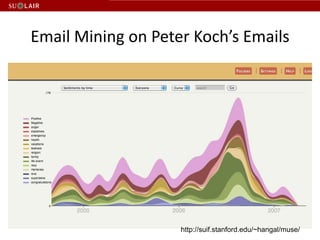
This document discusses Stanford's efforts to process and manage born-digital materials from several collections received in the late 1990s and 2000s. It outlines challenges around reading legacy media formats, describing technical metadata, and providing long-term access. The document also describes Stanford's collaboration with other institutions on the AIMS project and their use of FTK forensic software to extract metadata and organize large email collections.











































![Gettingstartedwithdigitalcollectionsweb[1]](https://cdn.slidesharecdn.com/ss_thumbnails/gettingstartedwithdigitalcollectionsweb1-1227107163937370-9-thumbnail.jpg?width=640&height=640&fit=bounds)
































