Agenda
• Concept: What’sgood code?
• Move Code from Controller to Model
• RESTful best practices
• Model best practices
• Controller best practices
• View best practices
5.
Warning! you shouldhave testing before modify!
本次演講雖沒有提及測試,
但在修改重構程式前,
應有好的測試,
以確保程式於修改後執行無誤。
Best Practice Lesson1:
Move code from Controller to
Model
action code 超過15行請注意
http://weblog.jamisbuck.org/2006/10/18/skinny-controller-fat-model
13.
1.Move finder tonamed_scope
class PostsController < ApplicationController
def index
@public_posts = Post.find(:all, :conditions => { :state => 'public' },
:limit => 10,
:order => 'created_at desc')
@draft_posts = Post.find(:all, :conditions => { :state => 'draft' },
:limit => 10,
:order => 'created_at desc')
end
end
Before
14.
class UsersController <ApplicationController
def index
@published_post = Post.published
@draft_post = Post.draft
end
end
class Post < ActiveRecord::Base
named_scope :published, :conditions => { :state => 'published' },
:limit => 10, :order => 'created_at desc')
named_scope :draft, :conditions => { :state => 'draft' },
:limit => 10, :order => 'created_at desc')
end
1.Move finder to named_scope
After
15.
2. Use modelassociation
class PostsController < ApplicationController
def create
@post = Post.new(params[:post])
@post.user_id = current_user.id
@post.save
end
end
Before
16.
class PostsController <ApplicationController
def create
@post = current_user.posts.build(params[:post])
@post.save
end
end
class User < ActiveRecord::Base
has_many :posts
end
2. Use model association
After
17.
class PostsController <ApplicationController
def edit
@post = Post.find(params[:id)
if @post.current_user != current_user
flash[:warning] = 'Access denied'
redirect_to posts_url
end
end
end
3. Use scope access
不必要的權限檢查
Before
18.
class PostsController <ApplicationController
def edit
# raise RecordNotFound exception (404 error) if not found
@post = current_user.posts.find(params[:id)
end
end
After
3. Use scope access
找不到自然會丟例外
19.
4.Add model virtualattribute
<% form_for @user do |f| %>
<%= text_filed_tag :full_name %>
<% end %>
class UsersController < ApplicationController
def create
@user = User.new(params[:user)
@user.first_name = params[:full_name].split(' ', 2).first
@user.last_name = params[:full_name].split(' ', 2).last
@user.save
end
end
Before
20.
4.Add model virtualattribute
class User < ActiveRecord::Base
def full_name
[first_name, last_name].join(' ')
end
def full_name=(name)
split = name.split(' ', 2)
self.first_name = split.first
self.last_name = split.last
end
end
example code from http://railscasts.com/episodes/16-virtual-attributes
After
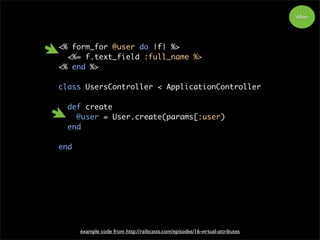
21.
<% form_for @userdo |f| %>
<%= f.text_field :full_name %>
<% end %>
class UsersController < ApplicationController
def create
@user = User.create(params[:user)
end
end
example code from http://railscasts.com/episodes/16-virtual-attributes
After
22.
5. Use modelcallback
<% form_for @post do |f| %>
<%= f.text_field :content %>
<%= check_box_tag 'auto_tagging' %>
<% end %>
class PostController < ApplicationController
def create
@post = Post.new(params[:post])
if params[:auto_tagging] == '1'
@post.tags = AsiaSearch.generate_tags(@post.content)
else
@post.tags = ""
end
@post.save
end
end
Before
23.
5. Use modelcallback
class Post < ActiveRecord::Base
attr_accessor :auto_tagging
before_save :generate_taggings
private
def generate_taggings
return unless auto_tagging == '1'
self.tags = Asia.search(self.content)
end
end
After
24.
<% form_for :note,... do |f| %>
<%= f.text_field :content %>
<%= f.check_box :auto_tagging %>
<% end
class PostController < ApplicationController
def create
@post = Post.new(params[:post])
@post.save
end
end
After
25.
6. Replace ComplexCreation
with Factory Method
class InvoiceController < ApplicationController
def create
@invoice = Invoice.new(params[:invoice])
@invoice.address = current_user.address
@invoice.phone = current_user.phone
@invoice.vip = ( @invoice.amount > 1000 )
if Time.now.day > 15
@invoice.delivery_time = Time.now + 2.month
else
@invoice.delivery_time = Time.now + 1.month
end
@invoice.save
end
end
Before
26.
6. Replace ComplexCreation
with Factory Method
class Invoice < ActiveRecord::Base
def self.new_by_user(params, user)
invoice = self.new(params)
invoice.address = user.address
invoice.phone = user.phone
invoice.vip = ( invoice.amount > 1000 )
if Time.now.day > 15
invoice.delivery_time = Time.now + 2.month
else
invoice.delivery_time = Time.now + 1.month
end
end
end
After
27.
class InvoiceController <ApplicationController
def create
@invoice = Invoice.new_by_user(params[:invoice], current_user)
@invoice.save
end
end
After
28.
7. Move ModelLogic into the
Model
class PostController < ApplicationController
def publish
@post = Post.find(params[:id])
@post.update_attribute(:is_published, true)
@post.approved_by = current_user
if @post.create_at > Time.now - 7.days
@post.popular = 100
else
@post.popular = 0
end
redirect_to post_url(@post)
end
end
Before
29.
7. Move ModelLogic into the
Model
class Post < ActiveRecord::Base
def publish
self.is_published = true
self.approved_by = current_user
if self.create_at > Time.now-7.days
self.popular = 100
else
self.popular = 0
end
end
end
After
30.
class PostController <ApplicationController
def publish
@post = Post.find(params[:id])
@post.publish
redirect_to post_url(@post)
end
end
After
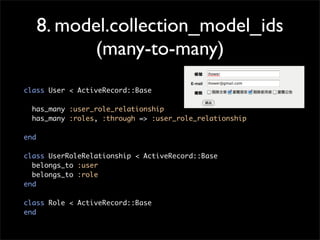
31.
8. model.collection_model_ids
(many-to-many)
class User< ActiveRecord::Base
has_many :user_role_relationship
has_many :roles, :through => :user_role_relationship
end
class UserRoleRelationship < ActiveRecord::Base
belongs_to :user
belongs_to :role
end
class Role < ActiveRecord::Base
end
32.
<% form_for @userdo |f| %>
<%= f.text_field :email %>
<% for role in Role.all %>
<%= check_box_tag 'role_id[]', role.id, @user.roles.include?(role) %>
<%= role.name %>
<% end %>
<% end %>
class User < ApplicationController
def update
@user = User.find(params[:id])
if @user.update_attributes(params[:user])
@user.roles.delete_all
(params[:role_id] || []).each { |i| @user.roles << Role.find(i) }
end
end
end
Before
33.
<% form_for @userdo |f| %>
<% for role in Role.all %>
<%= check_box_tag 'user[role_ids][]', role.id, @user.roles.include?(role)
<%= role.name %>
<% end %>
<%= hidden_field_tag 'user[role_ids][]', '' %>
<% end %>
class User < ApplicationController
def update
@user = User.find(params[:id])
@user.update_attributes(params[:user])
# 相當於 @user.role_ids = params[:user][:role_ids]
end
end
After
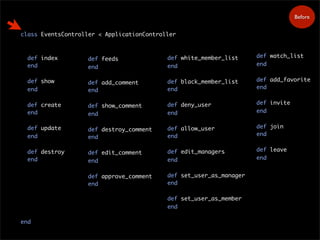
34.
Before
9. Nested ModelForms (one-to-one)
class Product < ActiveRecord::Base
has_one :detail
end
class Detail < ActiveRecord::Base
belongs_to :product
end
<% form_for :product do |f| %>
<%= f.text_field :title %>
<% fields_for :detail do |detail| %>
<%= detail.text_field :manufacturer %>
<% end %>
<% end %>
35.
class Product <ApplicationController
def create
@product = Product.new(params[:product])
@details = Detail.new(params[:detail])
Product.transaction do
@product.save!
@details.product = @product
@details.save!
end
end
end
example code from Agile Web Development with Rails 3rd.
Before
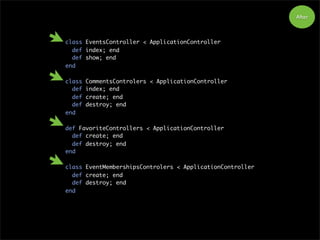
36.
After
9. Nested ModelForms (one-to-one)
Rails 2.3 new feature
class Product < ActiveRecord::Base
has_one :detail
accepts_nested_attributes_for :detail
end
<% form_for :product do |f| %>
<%= f.text_field :title %>
<% f.fields_for :detail do |detail| %>
<%= detail.text_field :manufacturer %>
<% end %>
<% end
37.
After
class Product <ApplicationController
def create
@product = Product.new(params[:product])
@product.save
end
end
38.
10. Nested ModelForms (one-to-many)
class Project < ActiveRecord::Base
has_many :tasks
accepts_nested_attributes_for :tasks
end
class Task < ActiveRecord::Base
belongs_to :project
end
<% form_for @project do |f| %>
<%= f.text_field :name %>
<% f.fields_for :tasks do |tasks_form| %>
<%= tasks_form.text_field :name %>
<% end %>
<% end %>
39.
Nested Model Forms
beforeRails 2.3 ?
• Ryan Bates’s series of railscasts on complex forms
• http://railscasts.com/episodes/75-complex-forms-part-3
• Recipe 13 in Advanced Rails Recipes book
Why RESTful?
RESTful helpyou to organize/name controllers, routes
and actions in standardization way
42.
class EventsController <ApplicationController
def index
end
def show
end
def create
end
def update
end
def destroy
end
end
def watch_list
end
def add_favorite
end
def invite
end
def join
end
def leave
end
def feeds
end
def add_comment
end
def show_comment
end
def destroy_comment
end
def edit_comment
end
def approve_comment
end
def white_member_list
end
def black_member_list
end
def deny_user
end
def allow_user
end
def edit_managers
end
def set_user_as_manager
end
def set_user_as_member
end
Before
43.
After
class EventsController <ApplicationController
def index; end
def show; end
end
class CommentsControlers < ApplicationController
def index; end
def create; end
def destroy; end
end
def FavoriteControllers < ApplicationController
def create; end
def destroy; end
end
class EventMembershipsControlers < ApplicationController
def create; end
def destroy; end
end
1. Overuse routecustomizations
Find another resources
map.resources :posts do |post|
post.resources :comments
end
After
46.
Suppose we hasa event model...
class Event < ActiveRecord::Base
has_many :attendee
has_one :map
has_many :memberships
has_many :users, :through => :memberships
end
47.
Can you answerhow to design
your resources ?
• manage event attendees (one-to-many)
• manage event map (one-to-one)
• manage event memberships (many-to-many)
• operate event state: open or closed
• search events
• sorting events
• event admin interface
48.
Learn RESTful design
myslide about restful:
http://www.slideshare.net/ihower/practical-rails2-350619
49.
2. Needless deepnesting
過度設計: Never more than one level
Before
map.resources :posts do |post|
post.resources :comments do |comment|
comment.resources :favorites
end
end
<%= link_to post_comment_favorite_path(@post, @comment, @favorite) %>
50.
After
map.resources :posts do|post|
post.resources :comments
end
map.resources :comments do |comment|
comment.resources :favorites
end
<%= link_to comment_favorite_path(@comment, @favorite) %>
2. Needless deep nesting
過度設計: Never more than one level
51.
3. Not usedefault route
Before
map.resources :posts, :member => { :push => :post }
map.connect ':controller/:action/:id'
map.connect ':controller/:action/:id.:format'
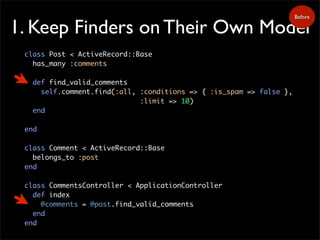
1. Keep Finderson Their Own Model
class Post < ActiveRecord::Base
has_many :comments
def find_valid_comments
self.comment.find(:all, :conditions => { :is_spam => false },
:limit => 10)
end
end
class Comment < ActiveRecord::Base
belongs_to :post
end
class CommentsController < ApplicationController
def index
@comments = @post.find_valid_comments
end
end
Before
55.
1. Keep Finderson Their Own Model
class Post < ActiveRecord::Base
has_many :comments
end
class Comment < ActiveRecord::Base
belongs_to :post
named_scope :only_valid, :conditions => { :is_spam => false }
named_scope :limit, lambda { |size| { :limit => size } }
end
class CommentsController < ApplicationController
def index
@comments = @post.comments.only_valid.limit(10)
end
end
After
56.
2. Love named_scope
classPostController < ApplicationController
def search
conditions = { :title => "%#{params[:title]}%" } if params[:title]
conditions.merge!{ :content => "%#{params[:content]}%" } if params[:content]
case params[:order]
when "title" : order = "title desc"
when "created_at" : order = "created_at"
end
if params[:is_published]
conditions.merge!{ :is_published => true }
end
@posts = Post.find(:all, :conditions => conditions, :order => order,
:limit => params[:limit])
end
end
Before
example code from Rails Antipatterns book
57.
2. Love named_scope
After
classPost < ActiveRecord::Base
named_scope :matching, lambda { |column, value|
return {} if value.blank?
{ :conditions => ["#{column} like ?", "%#{value}%"] }
}
named_scope :order, lambda { |order|
{ :order => case order
when "title" : "title desc"
when "created_at" : "created_at"
end }
}
end
58.
After
class PostController <ApplicationController
def search
@posts = Post.matching(:title, params[:title])
.matching(:content, params[:content])
.order(params[:order])
end
end
59.
3. the Lawof Demeter
class Invoice < ActiveRecord::Base
belongs_to :user
end
<%= @invoice.user.name %>
<%= @invoice.user.address %>
<%= @invoice.user.cellphone %>
Before
60.
3. the Lawof Demeter
class Invoice < ActiveRecord::Base
belongs_to :user
delegate :name, :address, :cellphone, :to => :user,
:prefix => true
end
<%= @invoice.user_name %>
<%= @invoice.user_address %>
<%= @invoice.user_cellphone %>
After
61.
4. DRY: Metaprogramming
classPost < ActiveRecord::Base
validate_inclusion_of :status, :in => ['draft', 'published', 'spam']
def self.all_draft
find(:all, :conditions => { :status => 'draft' }
end
def self.all_published
find(:all, :conditions => { :status => 'published' }
end
def self.all_spam
find(:all, :conditions => { :status => 'spam' }
end
def draft?
self.stats == 'draft'
end
def published?
self.stats == 'published'
end
def spam?
self.stats == 'spam'
end
end
Before
62.
4. DRY: Metaprogramming
classPost < ActiveRecord::Base
STATUSES = ['draft', 'published', 'spam']
validate_inclusion_of :status, :in => STATUSES
class << self
STATUSES.each do |status_name|
define_method "all_#{status}" do
find(:all, :conditions => { :status => status_name }
end
end
end
STATUSES.each do |status_name|
define_method "#{status_name}?" do
self.status == status_name
end
end
end
After
5. Extract intoModule
class User < ActiveRecord::Base
validates_presence_of :cellphone
before_save :parse_cellphone
def parse_cellphone
# do something
end
end
Before
65.
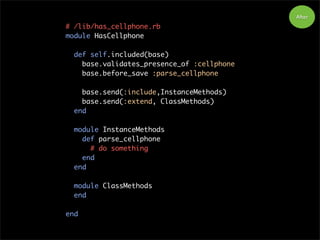
# /lib/has_cellphone.rb
module HasCellphone
defself.included(base)
base.validates_presence_of :cellphone
base.before_save :parse_cellphone
base.send(:include,InstanceMethods)
base.send(:extend, ClassMethods)
end
module InstanceMethods
def parse_cellphone
# do something
end
end
module ClassMethods
end
end
After
66.
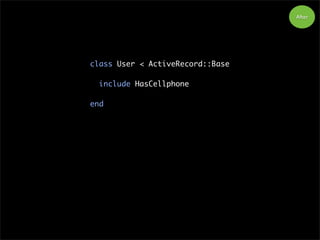
class User <ActiveRecord::Base
include HasCellphone
end
After
67.
6. Extract tocomposed class
Before
# == Schema Information
# address_city :string(255)
# address_street :string(255)
class Customer < ActiveRecord::Base
def adddress_close_to?(other_customer)
address_city == other_customer.address_city
end
def address_equal(other_customer)
address_street == other_customer.address_street &&
address_city == other_customer.address_city
end
end
68.
After
6. Extract tocomposed class
(value object)
class Customer < ActiveRecord::Base
composed_of :address, :mapping => [ %w(address_street street),
%w(address_city city) ]
end
class Address
attr_reader :street, :city
def initialize(street, city)
@street, @city = street, city
end
def close_to?(other_address)
city == other_address.city
end
def ==(other_address)
city == other_address.city && street == other_address.street
end
end
example code from Agile Web Development with Rails 3rd.
69.
7. Use Observer
classProject < ActiveRecord::Base
after_create :send_create_notifications
private
def send_create_notifications
self.members.each do |member|
ProjectNotifier.deliver_notification(self, member)
end
end
end
Before
70.
class Project <ActiveRecord::Base
# nothing here
end
# app/observers/project_notification_observer.rb
class ProjectNotificationObserver < ActiveRecord::Observer
observe Project
def after_create(project)
project.members.each do |member|
ProjectMailer.deliver_notice(project, member)
end
end
end
7. Use Observer
After
1. Isolating SeedData
Before
class CreateRoles < ActiveRecord::Migration
def self.up
create_table "roles", :force => true do |t|
t.string :name
end
["admin", "author", "editor","account"].each do |name|
Role.create!(:name => name)
end
end
def self.down
drop_table "roles"
end
end
73.
1. Isolating SeedData
After
# /db/seeds.rb (Rails 2.3.4)
["admin", "author", "editor","account"].each do |name|
Role.create!(:name => name)
end
rake db:seed
74.
After
# /lib/tasks/dev.rake (beforeRails 2.3.4)
namespace :dev do
desc "Setup seed data"
task :setup => :environment do
["admin", "author", "editor","account"].each do |name|
Role.create!(:name => name)
end
end
end
rake dev:setup
75.
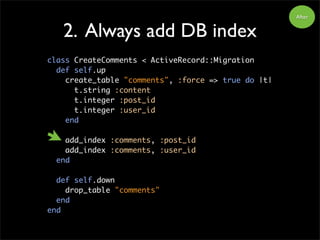
2. Always addDB index
class CreateComments < ActiveRecord::Migration
def self.up
create_table "comments", :force => true do |t|
t.string :content
t.integer :post_id
t.integer :user_id
end
end
def self.down
drop_table "comments"
end
end
Before
76.
2. Always addDB index
class CreateComments < ActiveRecord::Migration
def self.up
create_table "comments", :force => true do |t|
t.string :content
t.integer :post_id
t.integer :user_id
end
add_index :comments, :post_id
add_index :comments, :user_id
end
def self.down
drop_table "comments"
end
end
After
1. Use before_filter
classPostController < ApplicationController
def show
@post = current_user.posts.find(params[:id]
end
def edit
@post = current_user.posts.find(params[:id]
end
def update
@post = current_user.posts.find(params[:id]
@post.update_attributes(params[:post])
end
def destroy
@post = current_user.posts.find(params[:id]
@post.destroy
end
end
Before
79.
1. Use before_filter
classPostController < ApplicationController
before_filter :find_post, :only => [:show, :edit, :update, :destroy]
def update
@post.update_attributes(params[:post])
end
def destroy
@post.destroy
end
protected
def find_post
@post = current_user.posts.find(params[:id])
end
end
After
80.
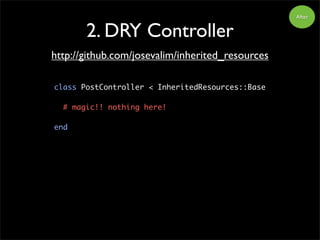
2. DRY Controller
classPostController < ApplicationController
def index
@posts = Post.all
end
def show
@post = Post.find(params[:id)
end
def new
@post = Post.new
end
def create
@post.create(params[:post]
redirect_to post_path(@post)
end
end
Before
def edit
@post = Post.find(params[:id)
end
def update
@post = Post.find(params[:id)
@post.update_attributes(params[:post])
redirect_to post_path(@post)
end
def destroy
@post = Post.find(params[:id)
@post.destroy
redirect_to posts_path
end
After
2. DRY Controller
classPostController < InheritedResources::Base
# if you need customize redirect url
def create
create! do |success, failure|
seccess.html { redirect_to post_url(@post) }
failure.html { redirect_to root_url }
end
end
end
83.
• You loseintent and readability
• Deviating from standards makes it harder
to work with other programmers
• Upgrading rails
DRY Controller Debate!!
小心走火入魔
from http://www.binarylogic.com/2009/10/06/discontinuing-resourcelogic/
1. Move codeinto controller
<% @posts = Post.find(:all) %>
<% @posts.each do |post| %>
<%=h post.title %>
<%=h post.content %>
<% end %>
Before
class PostsController < ApplicationController
def index
@posts = Post.find(:all)
end
end
After
87.
2. Move codeinto model
<% if current_user && (current_user == @post.user ||
@post.editors.include?(current_user) %>
<%= link_to 'Edit this post', edit_post_url(@post) %>
<% end %>
<% if @post.editable_by?(current_user) %>
<%= link_to 'Edit this post', edit_post_url(@post) %>
<% end %>
class Post < ActiveRecord::Base
def ediable_by?(user)
user && ( user == self.user || self.editors.include?(user)
end
end
Before
After
4. Replace instancevariable
with local variable
<%= render :partial => "sidebar" %>
<%= render :partial => "sidebar", :locals => { :post => @post } %>
Before
After
class Post < ApplicationController
def show
@post = Post.find(params[:id)
end
end
5. Use FormBuilder
After
<% my_form_for @post do |f| %>
<%= f.text_field :title, :label => t("post.title") %>
<%= f.text_area :content, :size => '80x20',
:label => t("post.content") %>
<%= f.submit t("submit") %>
<% end %>
92.
module ApplicationHelper
def my_form_for(*args,&block)
options = args.extract_options!.merge(:builder =>
LabeledFormBuilder)
form_for(*(args + [options]), &block)
end
end
class MyFormBuilder < ActionView::Helpers::FormBuilder
%w[text_field text_area].each do |method_name|
define_method(method_name) do |field_name, *args|
@template.content_tag(:p, field_label(field_name, *args) +
"<br />" + field_error(field_name) + super)
end
end
def submit(*args)
@template.content_tag(:p, super)
end
end
After
93.
6. Organize Helperfiles
# app/helpers/user_posts_helper.rb
# app/helpers/author_posts_helper.rb
# app/helpers/editor_posts_helper.rb
# app/helpers/admin_posts_helper.rb
class ApplicationController < ActionController::Base
helper :all # include all helpers, all the time
end
# app/helpers/posts_helper.rb
Before
After
94.
7. Learn RailsHelpers
• Learn content_for and yield
• Learn how to pass block parameter in helper
• my slide about helper: http://www.slideshare.net/ihower/building-web-interface-on-rails
• Read Rails helpers source code
• /actionpack-x.y.z/action_view/helpers/*
More best practices:
•Rails Performance
http://www.slideshare.net/ihower/rails-performance
• Rails Security
http://www.slideshare.net/ihower/rails-security-3299368















![2. Use model association
class PostsController < ApplicationController
def create
@post = Post.new(params[:post])
@post.user_id = current_user.id
@post.save
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-15-320.jpg)
![class PostsController < ApplicationController
def create
@post = current_user.posts.build(params[:post])
@post.save
end
end
class User < ActiveRecord::Base
has_many :posts
end
2. Use model association
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-16-320.jpg)
![class PostsController < ApplicationController
def edit
@post = Post.find(params[:id)
if @post.current_user != current_user
flash[:warning] = 'Access denied'
redirect_to posts_url
end
end
end
3. Use scope access
不必要的權限檢查
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-17-320.jpg)

![4.Add model virtual attribute
<% form_for @user do |f| %>
<%= text_filed_tag :full_name %>
<% end %>
class UsersController < ApplicationController
def create
@user = User.new(params[:user)
@user.first_name = params[:full_name].split(' ', 2).first
@user.last_name = params[:full_name].split(' ', 2).last
@user.save
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-19-320.jpg)
![4.Add model virtual attribute
class User < ActiveRecord::Base
def full_name
[first_name, last_name].join(' ')
end
def full_name=(name)
split = name.split(' ', 2)
self.first_name = split.first
self.last_name = split.last
end
end
example code from http://railscasts.com/episodes/16-virtual-attributes
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-20-320.jpg)
![5. Use model callback
<% form_for @post do |f| %>
<%= f.text_field :content %>
<%= check_box_tag 'auto_tagging' %>
<% end %>
class PostController < ApplicationController
def create
@post = Post.new(params[:post])
if params[:auto_tagging] == '1'
@post.tags = AsiaSearch.generate_tags(@post.content)
else
@post.tags = ""
end
@post.save
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-22-320.jpg)

![<% form_for :note, ... do |f| %>
<%= f.text_field :content %>
<%= f.check_box :auto_tagging %>
<% end
class PostController < ApplicationController
def create
@post = Post.new(params[:post])
@post.save
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-24-320.jpg)
![6. Replace Complex Creation
with Factory Method
class InvoiceController < ApplicationController
def create
@invoice = Invoice.new(params[:invoice])
@invoice.address = current_user.address
@invoice.phone = current_user.phone
@invoice.vip = ( @invoice.amount > 1000 )
if Time.now.day > 15
@invoice.delivery_time = Time.now + 2.month
else
@invoice.delivery_time = Time.now + 1.month
end
@invoice.save
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-25-320.jpg)

![class InvoiceController < ApplicationController
def create
@invoice = Invoice.new_by_user(params[:invoice], current_user)
@invoice.save
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-27-320.jpg)
![7. Move Model Logic into the
Model
class PostController < ApplicationController
def publish
@post = Post.find(params[:id])
@post.update_attribute(:is_published, true)
@post.approved_by = current_user
if @post.create_at > Time.now - 7.days
@post.popular = 100
else
@post.popular = 0
end
redirect_to post_url(@post)
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-28-320.jpg)

![class PostController < ApplicationController
def publish
@post = Post.find(params[:id])
@post.publish
redirect_to post_url(@post)
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-30-320.jpg)
![<% form_for @user do |f| %>
<%= f.text_field :email %>
<% for role in Role.all %>
<%= check_box_tag 'role_id[]', role.id, @user.roles.include?(role) %>
<%= role.name %>
<% end %>
<% end %>
class User < ApplicationController
def update
@user = User.find(params[:id])
if @user.update_attributes(params[:user])
@user.roles.delete_all
(params[:role_id] || []).each { |i| @user.roles << Role.find(i) }
end
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-32-320.jpg)
![<% form_for @user do |f| %>
<% for role in Role.all %>
<%= check_box_tag 'user[role_ids][]', role.id, @user.roles.include?(role)
<%= role.name %>
<% end %>
<%= hidden_field_tag 'user[role_ids][]', '' %>
<% end %>
class User < ApplicationController
def update
@user = User.find(params[:id])
@user.update_attributes(params[:user])
# 相當於 @user.role_ids = params[:user][:role_ids]
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-33-320.jpg)

![class Product < ApplicationController
def create
@product = Product.new(params[:product])
@details = Detail.new(params[:detail])
Product.transaction do
@product.save!
@details.product = @product
@details.save!
end
end
end
example code from Agile Web Development with Rails 3rd.
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-35-320.jpg)

![After
class Product < ApplicationController
def create
@product = Product.new(params[:product])
@product.save
end
end](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-37-320.jpg)















![2. Love named_scope
class PostController < ApplicationController
def search
conditions = { :title => "%#{params[:title]}%" } if params[:title]
conditions.merge!{ :content => "%#{params[:content]}%" } if params[:content]
case params[:order]
when "title" : order = "title desc"
when "created_at" : order = "created_at"
end
if params[:is_published]
conditions.merge!{ :is_published => true }
end
@posts = Post.find(:all, :conditions => conditions, :order => order,
:limit => params[:limit])
end
end
Before
example code from Rails Antipatterns book](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-56-320.jpg)
![2. Love named_scope
After
class Post < ActiveRecord::Base
named_scope :matching, lambda { |column, value|
return {} if value.blank?
{ :conditions => ["#{column} like ?", "%#{value}%"] }
}
named_scope :order, lambda { |order|
{ :order => case order
when "title" : "title desc"
when "created_at" : "created_at"
end }
}
end](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-57-320.jpg)
![After
class PostController < ApplicationController
def search
@posts = Post.matching(:title, params[:title])
.matching(:content, params[:content])
.order(params[:order])
end
end](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-58-320.jpg)


![4. DRY: Metaprogramming
class Post < ActiveRecord::Base
validate_inclusion_of :status, :in => ['draft', 'published', 'spam']
def self.all_draft
find(:all, :conditions => { :status => 'draft' }
end
def self.all_published
find(:all, :conditions => { :status => 'published' }
end
def self.all_spam
find(:all, :conditions => { :status => 'spam' }
end
def draft?
self.stats == 'draft'
end
def published?
self.stats == 'published'
end
def spam?
self.stats == 'spam'
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-61-320.jpg)
![4. DRY: Metaprogramming
class Post < ActiveRecord::Base
STATUSES = ['draft', 'published', 'spam']
validate_inclusion_of :status, :in => STATUSES
class << self
STATUSES.each do |status_name|
define_method "all_#{status}" do
find(:all, :conditions => { :status => status_name }
end
end
end
STATUSES.each do |status_name|
define_method "#{status_name}?" do
self.status == status_name
end
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-62-320.jpg)



![After
6. Extract to composed class
(value object)
class Customer < ActiveRecord::Base
composed_of :address, :mapping => [ %w(address_street street),
%w(address_city city) ]
end
class Address
attr_reader :street, :city
def initialize(street, city)
@street, @city = street, city
end
def close_to?(other_address)
city == other_address.city
end
def ==(other_address)
city == other_address.city && street == other_address.street
end
end
example code from Agile Web Development with Rails 3rd.](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-68-320.jpg)



![1. Isolating Seed Data
Before
class CreateRoles < ActiveRecord::Migration
def self.up
create_table "roles", :force => true do |t|
t.string :name
end
["admin", "author", "editor","account"].each do |name|
Role.create!(:name => name)
end
end
def self.down
drop_table "roles"
end
end](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-72-320.jpg)
![1. Isolating Seed Data
After
# /db/seeds.rb (Rails 2.3.4)
["admin", "author", "editor","account"].each do |name|
Role.create!(:name => name)
end
rake db:seed](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-73-320.jpg)
![After
# /lib/tasks/dev.rake (before Rails 2.3.4)
namespace :dev do
desc "Setup seed data"
task :setup => :environment do
["admin", "author", "editor","account"].each do |name|
Role.create!(:name => name)
end
end
end
rake dev:setup](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-74-320.jpg)


![1. Use before_filter
class PostController < ApplicationController
def show
@post = current_user.posts.find(params[:id]
end
def edit
@post = current_user.posts.find(params[:id]
end
def update
@post = current_user.posts.find(params[:id]
@post.update_attributes(params[:post])
end
def destroy
@post = current_user.posts.find(params[:id]
@post.destroy
end
end
Before](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-78-320.jpg)
![1. Use before_filter
class PostController < ApplicationController
before_filter :find_post, :only => [:show, :edit, :update, :destroy]
def update
@post.update_attributes(params[:post])
end
def destroy
@post.destroy
end
protected
def find_post
@post = current_user.posts.find(params[:id])
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-79-320.jpg)
![2. DRY Controller
class PostController < ApplicationController
def index
@posts = Post.all
end
def show
@post = Post.find(params[:id)
end
def new
@post = Post.new
end
def create
@post.create(params[:post]
redirect_to post_path(@post)
end
end
Before
def edit
@post = Post.find(params[:id)
end
def update
@post = Post.find(params[:id)
@post.update_attributes(params[:post])
redirect_to post_path(@post)
end
def destroy
@post = Post.find(params[:id)
@post.destroy
redirect_to posts_path
end](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-80-320.jpg)






![3. Move code into helper
<%= select_tag :state, options_for_select( [[t(:draft),"draft" ],
[t(:published),"published"]],
params[:default_state] ) %>
Before
After
<%= select_tag :state, options_for_post_state(params[:default_state]) %>
# /app/helpers/posts_helper.rb
def options_for_post_state(default_state)
options_for_select( [[t(:draft),"draft" ],[t(:published),"published"]],
default_state )
end](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-88-320.jpg)



![module ApplicationHelper
def my_form_for(*args, &block)
options = args.extract_options!.merge(:builder =>
LabeledFormBuilder)
form_for(*(args + [options]), &block)
end
end
class MyFormBuilder < ActionView::Helpers::FormBuilder
%w[text_field text_area].each do |method_name|
define_method(method_name) do |field_name, *args|
@template.content_tag(:p, field_label(field_name, *args) +
"<br />" + field_error(field_name) + super)
end
end
def submit(*args)
@template.content_tag(:p, super)
end
end
After](https://image.slidesharecdn.com/rails-best-practices-091024015011-phpapp01/85/Rails-Best-Practices-92-320.jpg)






















































