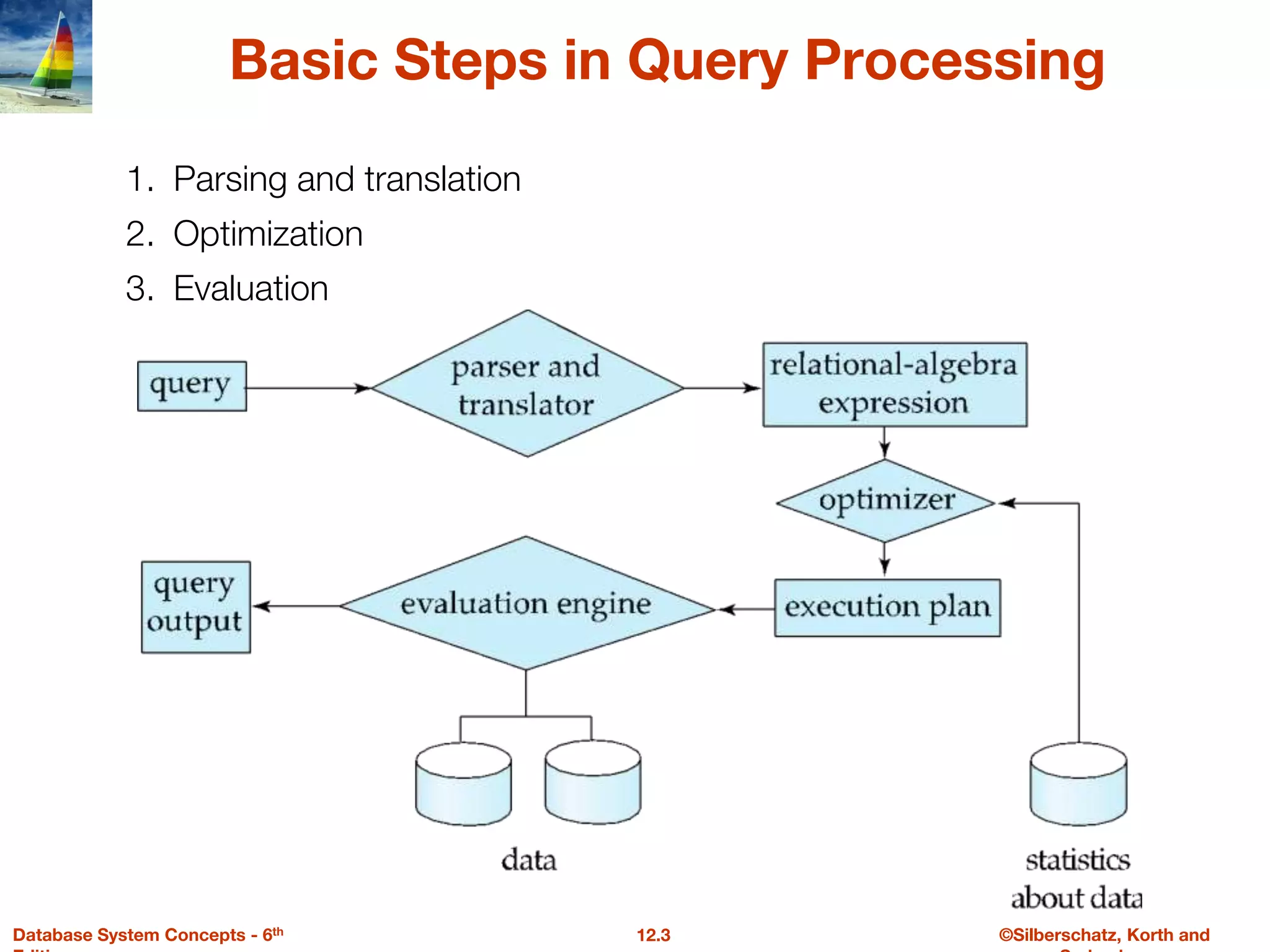
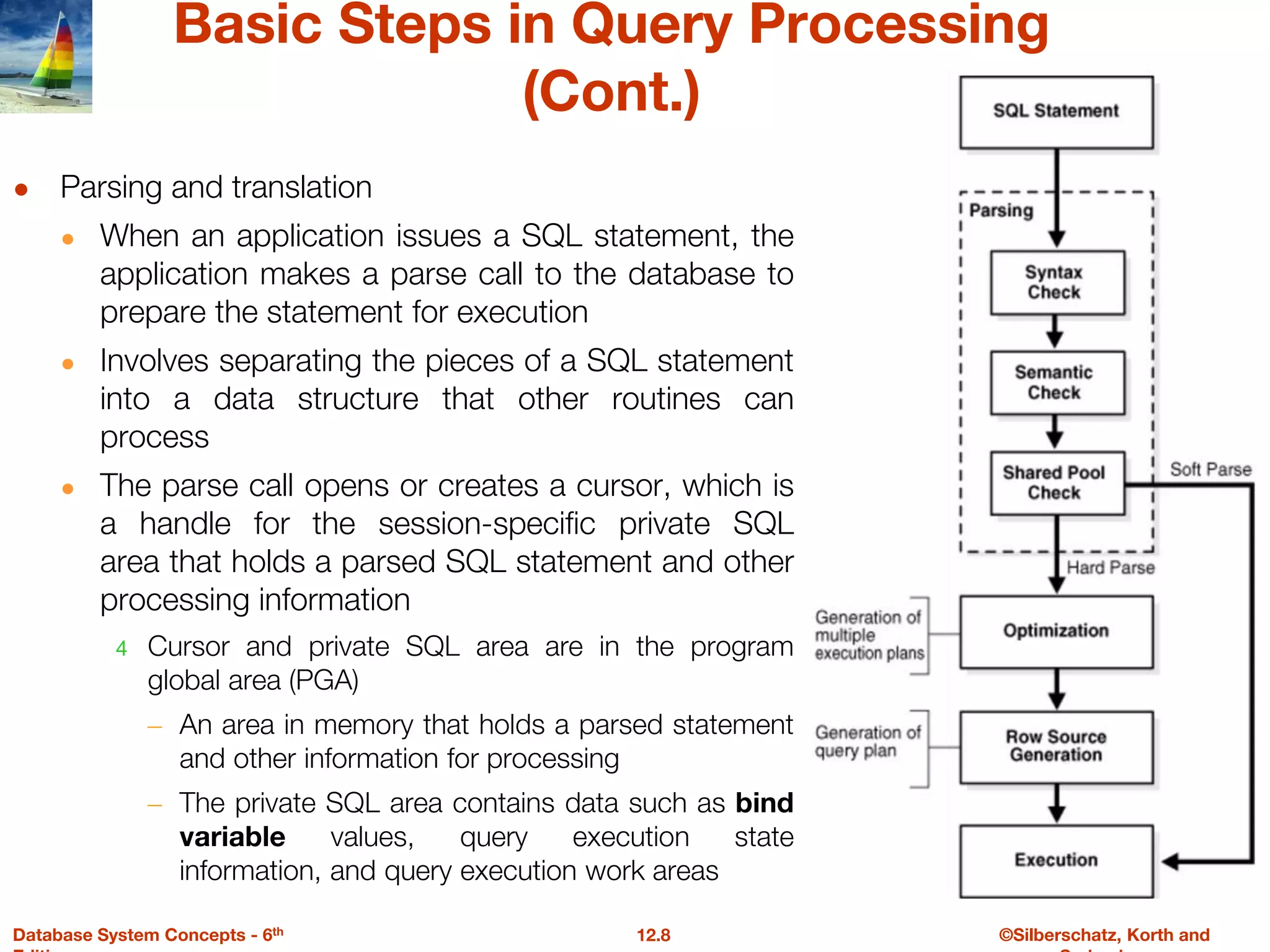
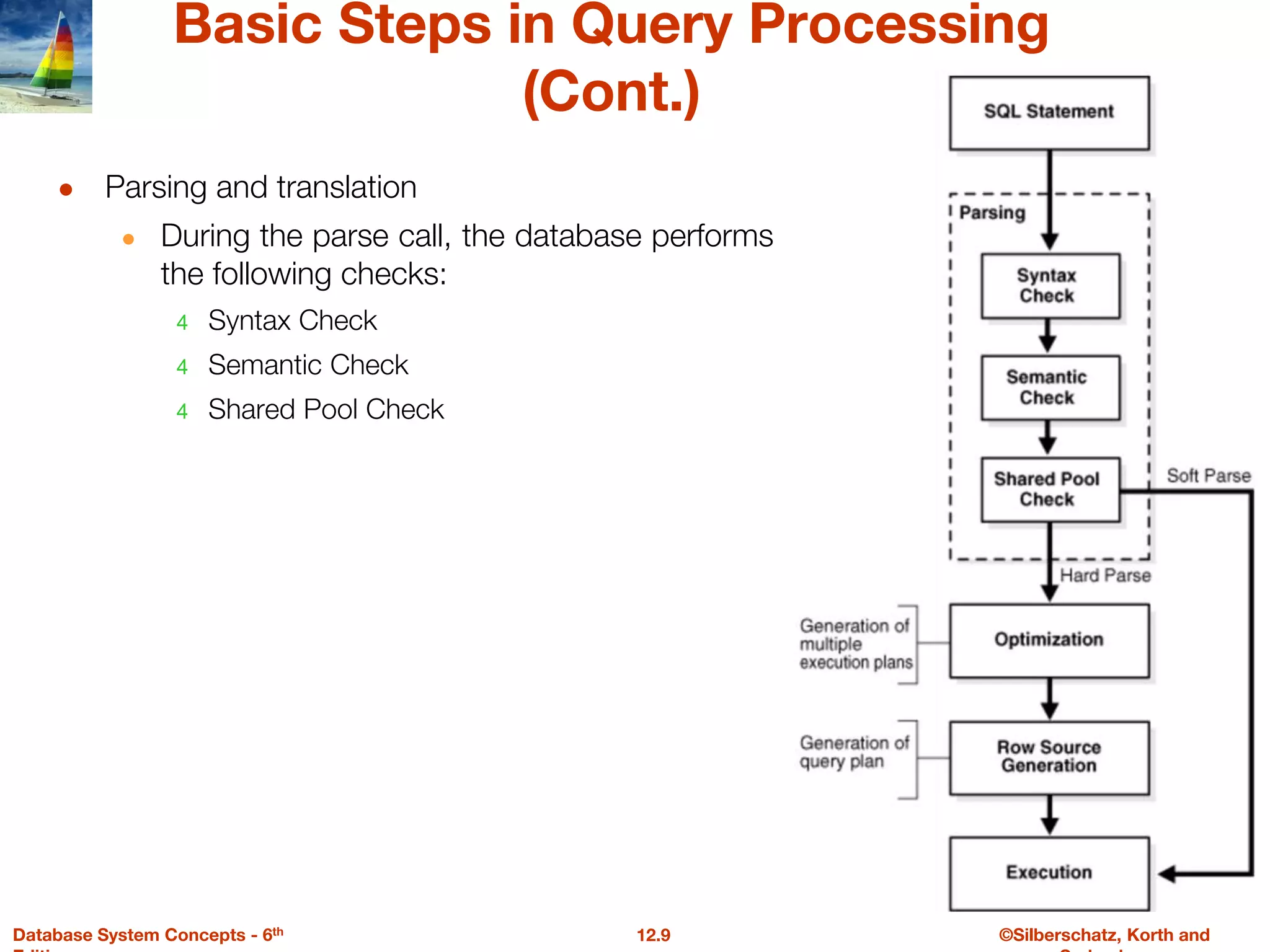
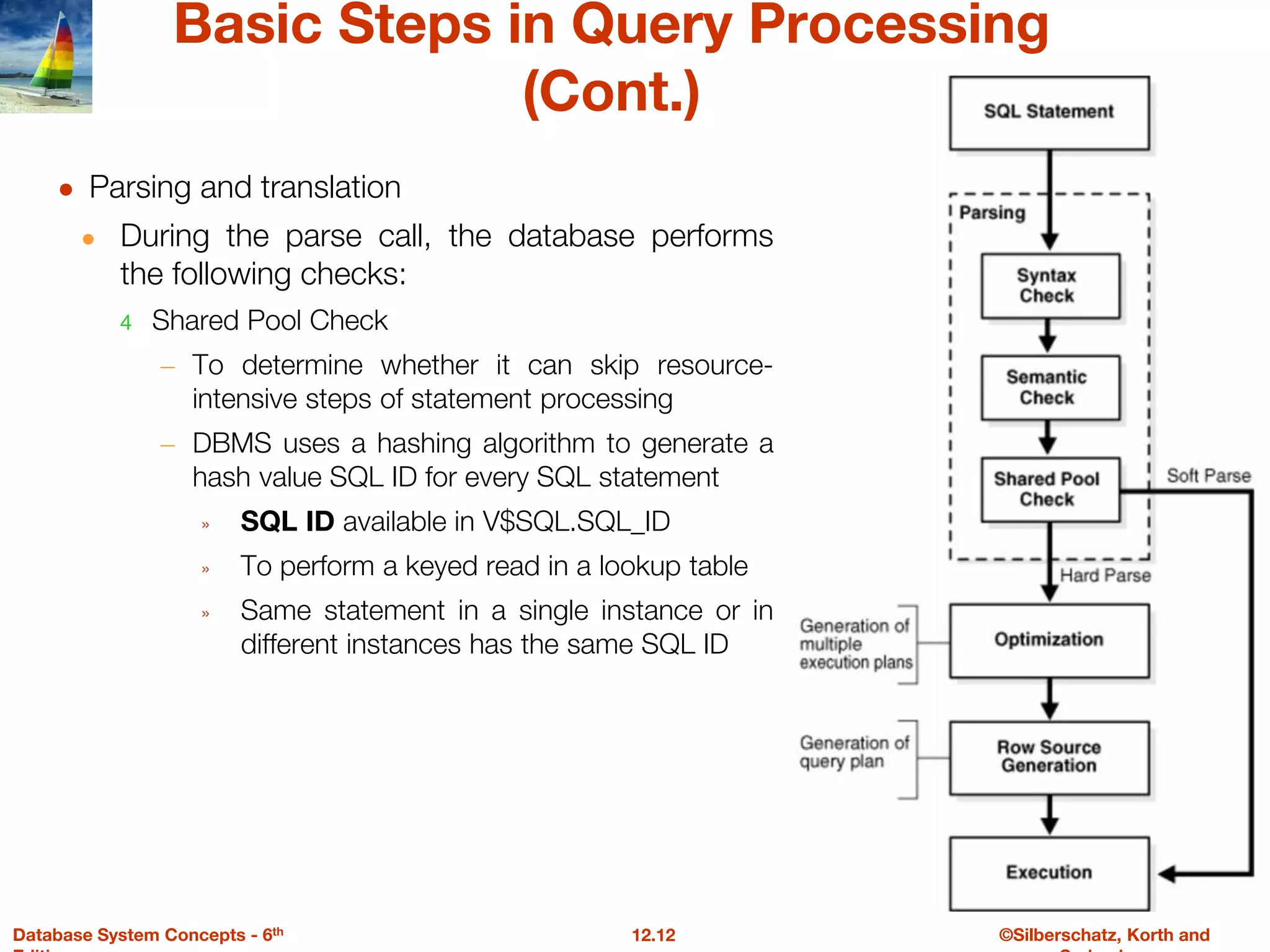
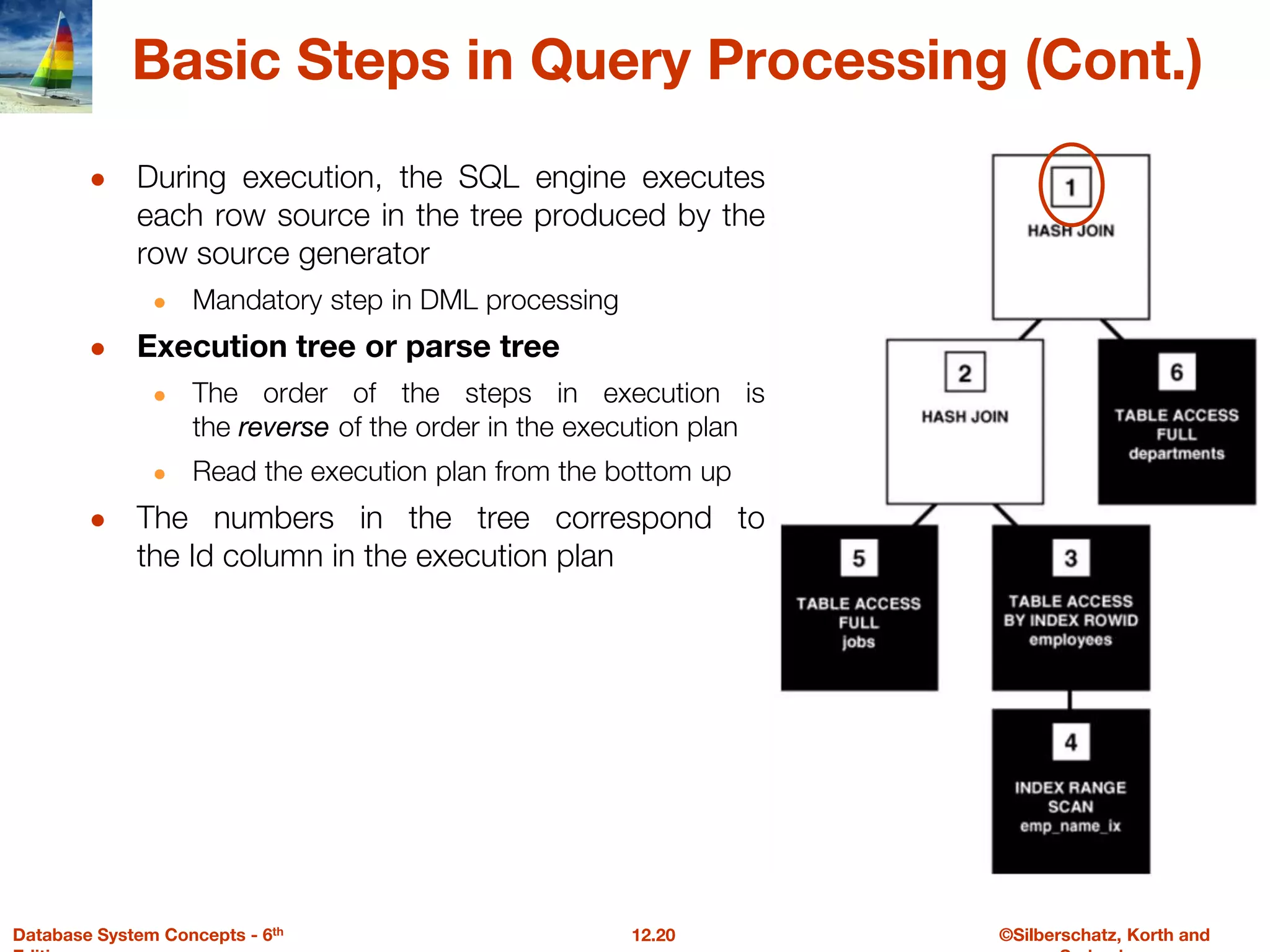
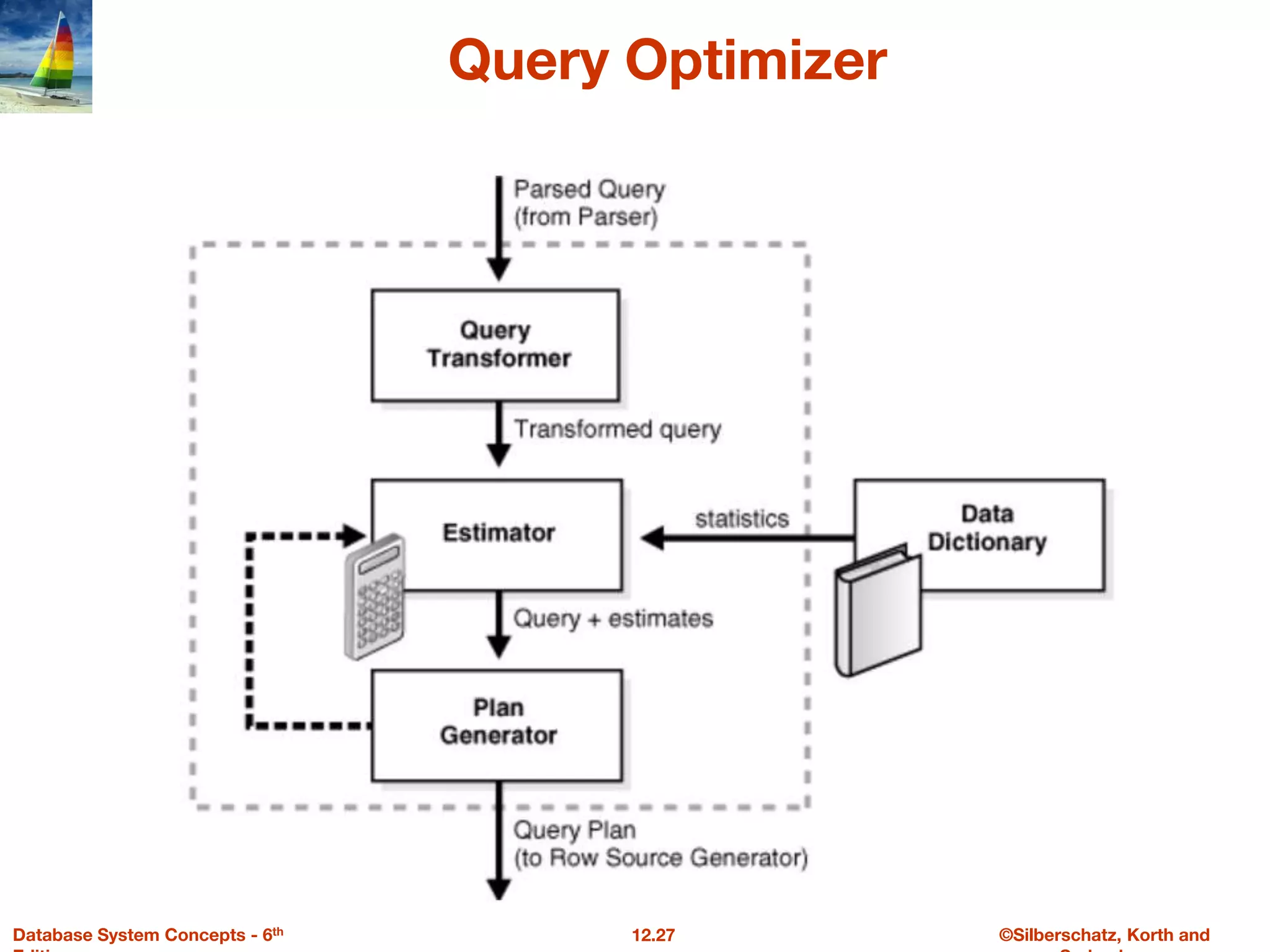
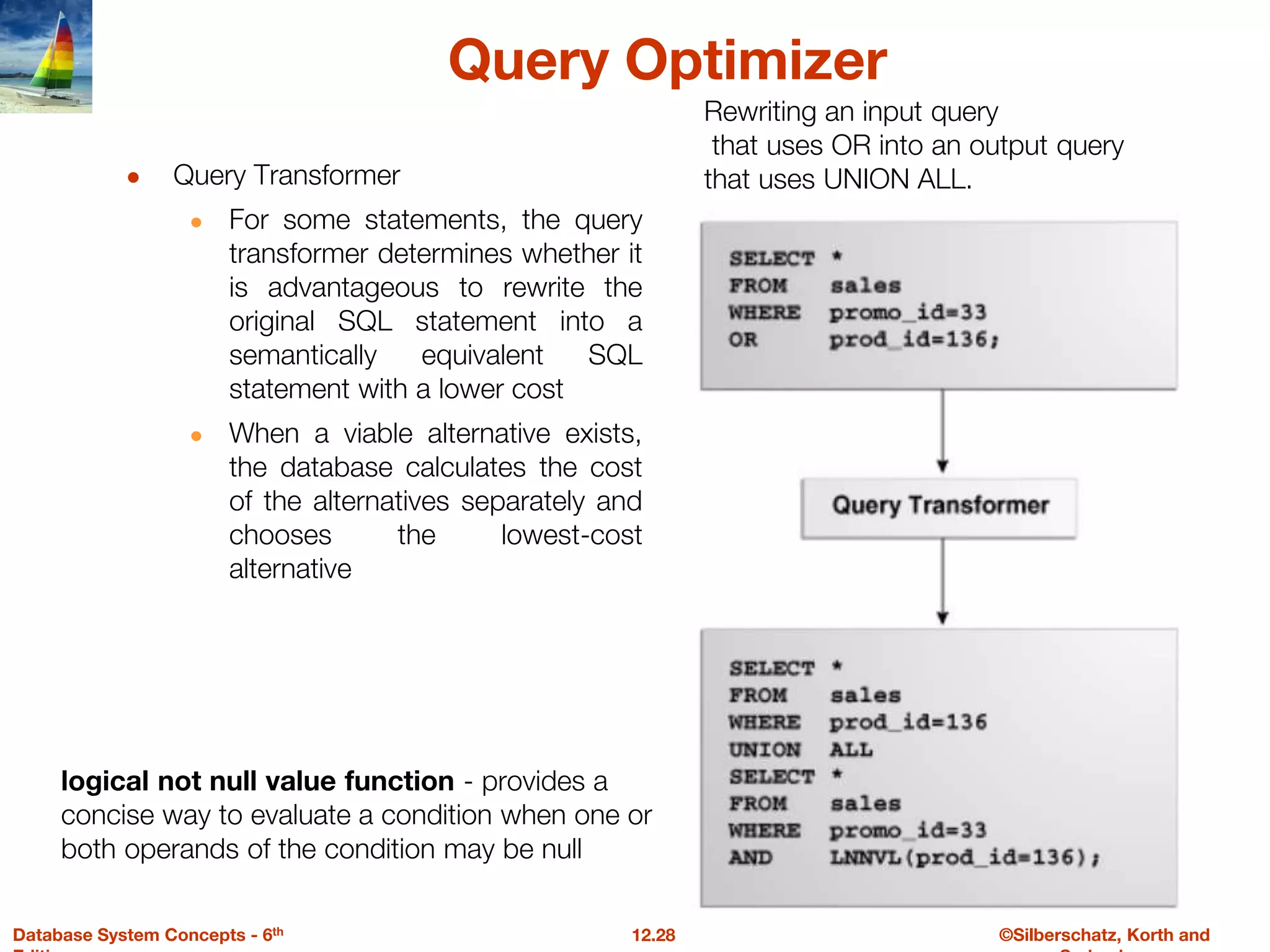
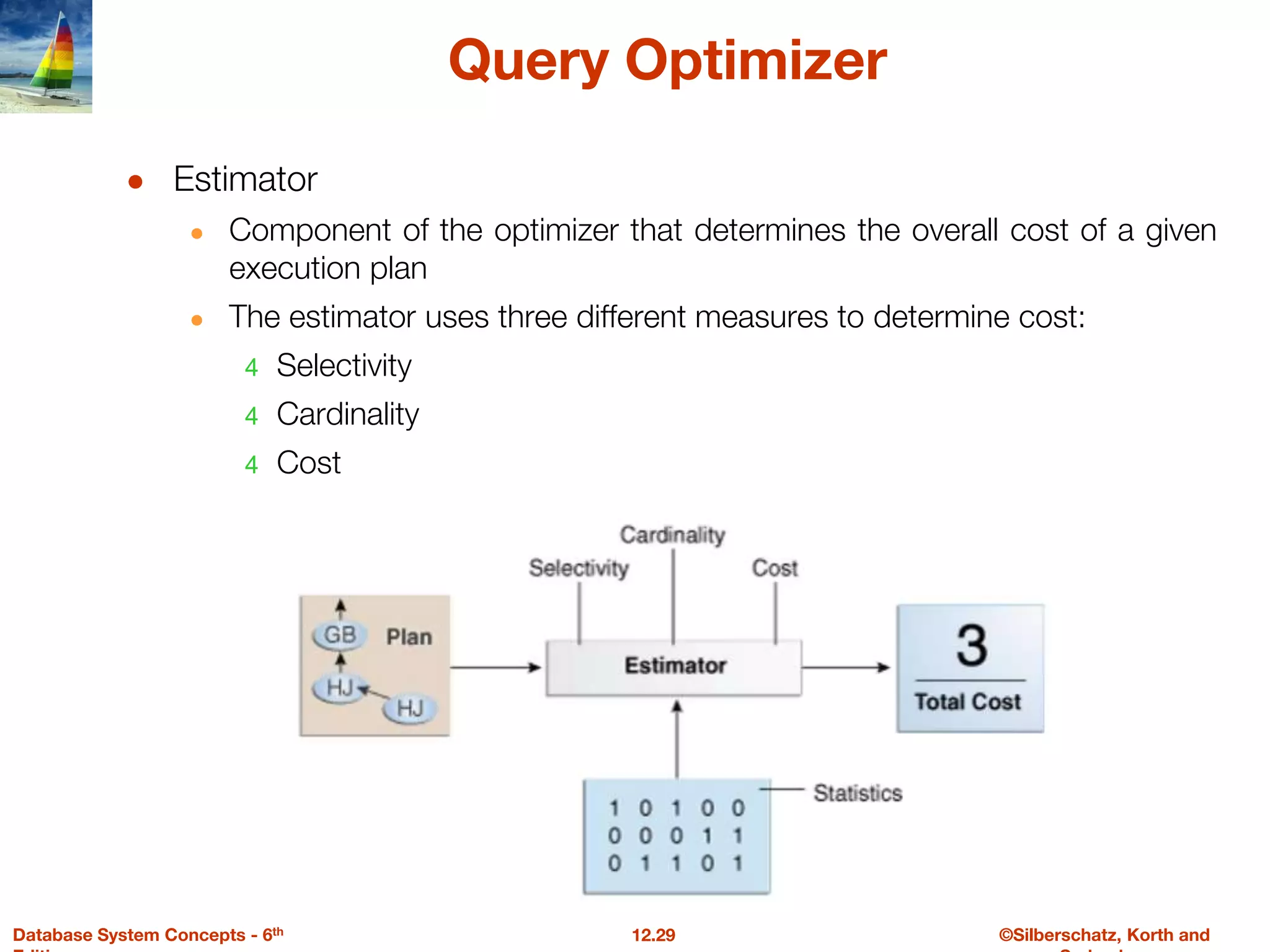
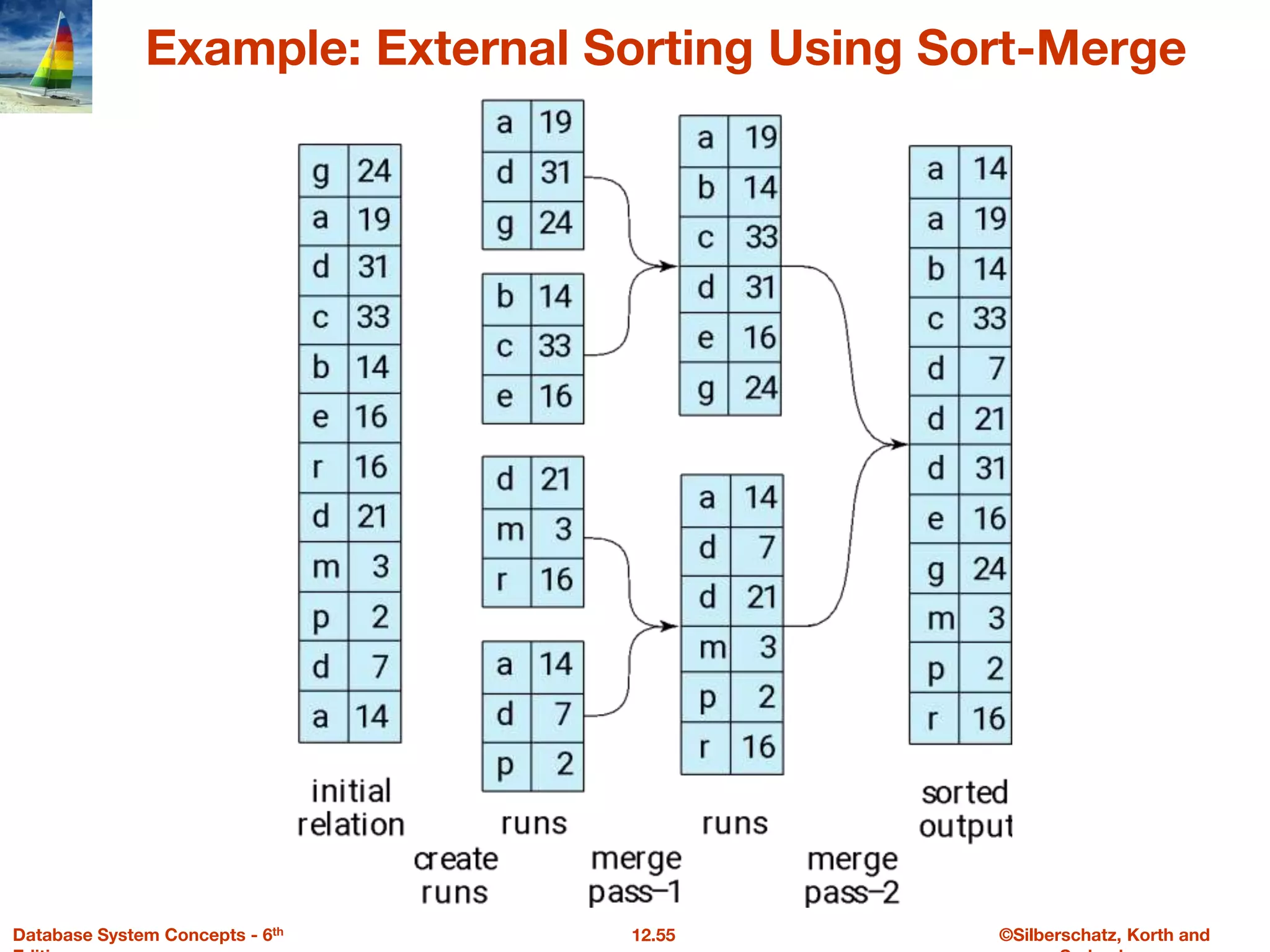
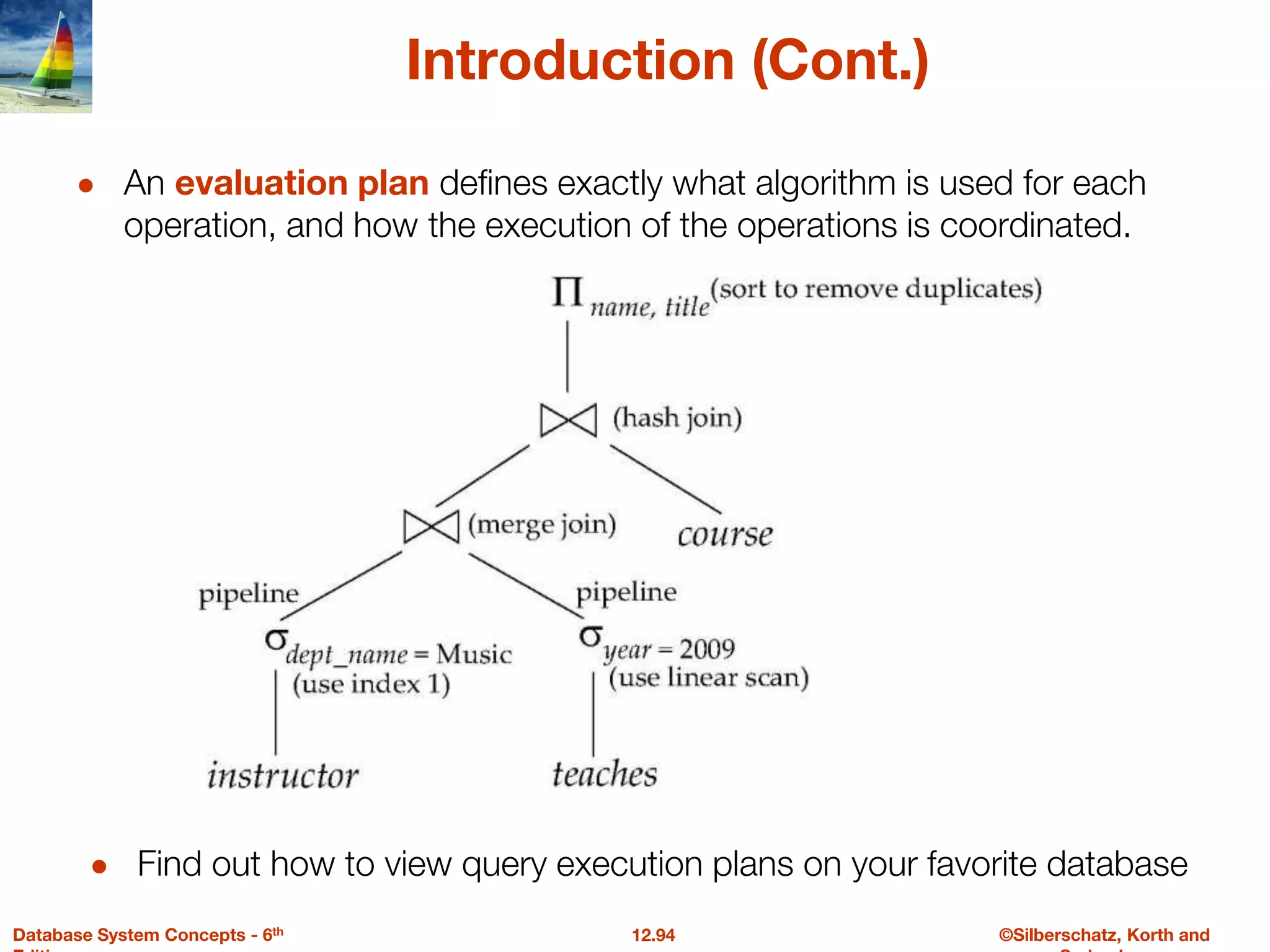
The document discusses the basic steps in query processing, including parsing and translation, optimization, and evaluation. It describes parsing a query into its internal form, translating it to relational algebra, and generating multiple evaluation plans. Optimization selects the most efficient plan based on estimated costs. The selected plan is then used to iteratively execute the query and return the result set.

























































![©Silberschatz, Korth and
12.67
Database System Concepts - 6th
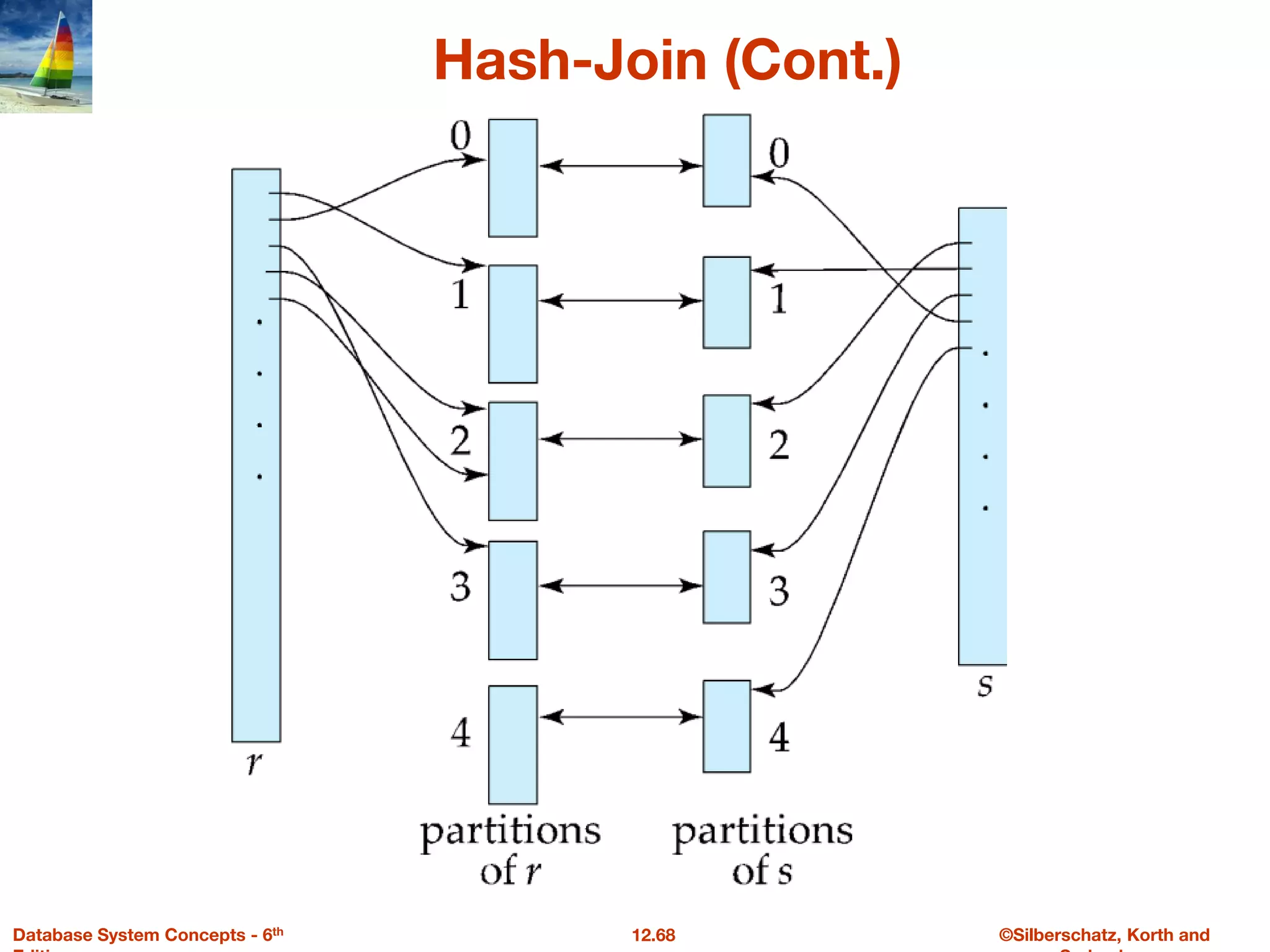
Hash-Join
● Applicable for equi-joins and natural joins.
● A hash function h is used to partition tuples of both relations
● h maps JoinAttrs values to {0, 1, ..., n}, where JoinAttrs denotes the
common attributes of r and s used in the natural join.
● r0, r1, . . ., rn denote partitions of r tuples
4 Each tuple tr ∈ r is put in partition ri where i = h(tr [JoinAttrs]).
● r0,, r1. . ., rn denotes partitions of s tuples
4 Each tuple ts ∈s is put in partition si, where i = h(ts [JoinAttrs]).
● Note: In book, ri is denoted as Hri, si is denoted as Hsi and
n is denoted as nh.](https://image.slidesharecdn.com/queryprocessingandoptimization-part1-230428042503-fd036e15/75/QueryProcessingAndOptimization-Part-1-pptx-67-2048.jpg)











































![©Silberschatz, Korth and
12.11
Database System Concepts - 6th
Join Order Optimization Algorithm
procedure findbestplan(S)
if (bestplan[S].cost ≠ ∞)
return bestplan[S]
// else bestplan[S] has not been computed earlier, compute it now
if (S contains only 1 relation)
set bestplan[S].plan and bestplan[S].cost based on the best way
of accessing S /* Using selections on S and indices on S */
else for each non-empty subset S1 of S such that S1 ≠ S
P1= findbestplan(S1)
P2= findbestplan(S - S1)
A = best algorithm for joining results of P1 and P2
cost = P1.cost + P2.cost + cost of A
if cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “execute P1.plan; execute P2.plan;
join results of P1 and P2 using A”
return bestplan[S]
* Some modifications to allow indexed nested loops joins on relations that have
selections (see book)](https://image.slidesharecdn.com/queryprocessingandoptimization-part1-230428042503-fd036e15/75/QueryProcessingAndOptimization-Part-1-pptx-117-2048.jpg)